
Real-time AI voice assistants are no longer experimental systems limited to demos or labs. Today, they are becoming production tools for customer support, sales, and operations. However, building them correctly requires more than connecting a language model to a phone call. Teams must design for low latency, continuous audio streaming, reliable call handling, and scalable infrastructure.
This blog walks through the complete technical approach to building real-time assistants using an AI voice agent API. It explains the core components, architectural decisions, and infrastructure choices required to move from prototypes to production-ready live call AI systems.
What Are Real-Time AI Voice Assistants And Why Are They Different From IVRs?
Real-time AI voice assistants are systems that can listen, think, and respond during an active phone call. Unlike traditional IVRs, they do not wait for the caller to finish speaking. Instead, they process audio continuously and respond naturally, similar to a human.
Historically, voice systems were built using fixed scripts. However, modern expectations are very different. Users now expect conversations, not menus. As a result, real time AI voice assistants must handle interruptions, follow context, and respond without delays.
To understand the difference clearly, consider the comparison below.
IVR Vs Real-Time AI Voice Assistant
| Aspect | Traditional IVR | Real-Time AI Voice Assistant |
| Interaction Style | Menu-based | Conversational |
| Latency | High (waits per step) | Low (continuous) |
| Context Handling | None | Full session memory |
| Interruptions | Not supported | Supported |
| Intelligence | Rules-based | LLM-driven |
Because of these differences, building live call AI systems requires a completely different architecture. Therefore, before thinking about tools or vendors, it is important to understand the core system design.
What Components Make Up An AI Voice Agent API?
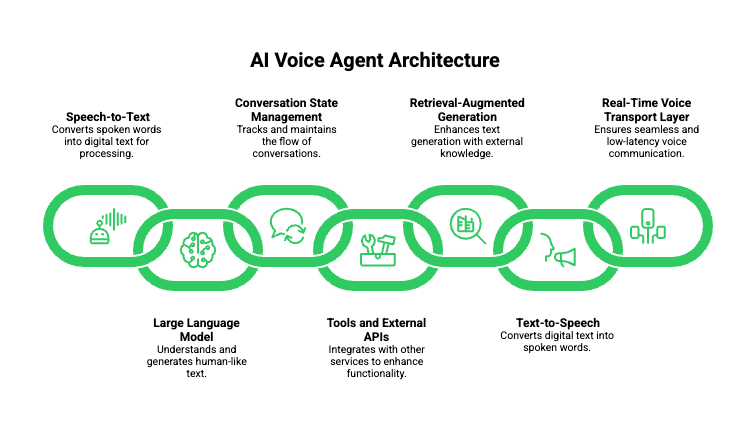
An AI voice agent API is not a single API. Instead, it is a collection of coordinated systems that work together in real time. Each component has a clear responsibility, and removing any one of them breaks the experience.
At a high level, a production-grade voice agent includes the following components:
- Speech-to-Text (STT)
- Large Language Model (LLM)
- Conversation State Management
- Tools and External APIs
- Retrieval-Augmented Generation (RAG)
- Text-to-Speech (TTS)
- Real-Time Voice Transport Layer
Importantly, voice agents are not defined by models. Instead, they are defined by how well these components are orchestrated.
Core Components And Their Responsibilities
| Component | Role In Live Call AI |
| STT | Converts streaming audio to text |
| LLM | Understands intent and generates responses |
| State Manager | Maintains conversational context |
| Tools | Executes actions like bookings or lookups |
| RAG | Injects business or domain knowledge |
| TTS | Converts text responses to audio |
| Voice Transport | Streams audio with low latency |
Because all components operate under strict timing limits, integration quality matters more than individual model accuracy.
How Does A Real-Time AI Voice Assistant Work During A Live Call?
To build an effective system, you must understand the call-time execution flow. Unlike chat systems, voice systems cannot pause. Every millisecond adds friction.
Below is the step-by-step lifecycle of a real-time AI voice assistant during a call.
Step-By-Step Call Flow
- The caller speaks into the phone.
- Audio frames are captured instantly.
- Audio is streamed in real time to the backend.
- STT produces partial and final transcripts.
- The LLM processes intent incrementally.
- Tools or RAG are triggered when needed.
- The LLM streams response tokens.
- TTS converts tokens into audio chunks.
- Audio is streamed back to the caller.
Because all steps happen in parallel, the system must be streaming-first, not request-based.
Why Partial Transcripts Matter
Partial transcripts allow the system to:
- Predict user intent earlier
- Reduce response latency
- Handle interruptions smoothly
As a result, real-time systems feel natural, while batch systems feel robotic.
Why Is Low Latency The Hardest Problem In Live Call AI?
Latency is the single most difficult challenge in live call AI. Even small delays are noticeable in voice interactions. Studies of human conversation show median turn-taking latencies under 300 ms, which means production systems must target sub-300 ms round trips to feel natural.
From a human perception standpoint:
- Under 300ms feels instant
- Between 300–700ms feels slow
- Above 1 second feels broken
Unfortunately, latency compounds across the pipeline.
Latency Breakdown In A Voice Agent
| Stage | Typical Delay |
| Audio Capture | 20–40 ms |
| STT Processing | 100–300 ms |
| LLM Inference | 200–800 ms |
| Tool Calls | 100–500 ms |
| TTS Generation | 150–400 ms |
| Audio Playback | 50–100 ms |
Because of this, reducing latency in one component is not enough. Instead, systems must be designed to overlap processing wherever possible.
Therefore, streaming, chunking, and early intent detection are mandatory design patterns.
How Do You Choose The Right LLM For A Real-Time Voice Agent?
Choosing an LLM for voice is different from choosing one for chat. Accuracy matters, but response speed matters more.
When evaluating LLMs for real time AI voice assistants, focus on the following:
Key LLM Requirements For Voice
- Fast first-token latency
- Token-level streaming output
- Reliable tool calling
- Predictable response timing
Although large models may sound appealing, smaller or optimized models often perform better for live conversations. Therefore, many teams use different models for:
- Voice conversations
- Offline reasoning
- Analytics or summaries
Because the LLM does not control the voice transport, it should remain stateless and fast.
How Do Speech-To-Text And Text-To-Speech Affect Voice Quality?
STT and TTS directly shape how natural the assistant feels. Even with a strong LLM, poor audio handling breaks trust.
Speech-To-Text (STT) Considerations
A production STT system should support:
- Streaming transcription
- Partial hypotheses
- Accent robustness
- Noise handling
- Endpoint detection
Without partial results, systems cannot respond fast enough. Therefore, batch transcription is not suitable for live call AI.
Text-To-Speech (TTS) Considerations
A good TTS system must support:
- Chunked audio output
- Consistent voice tone
- Low synthesis latency
- Mid-speech interruption handling
Because callers interrupt often, TTS playback must stop immediately when new input arrives.
How Do You Maintain Context In Real-Time AI Voice Assistants?
Context management is harder in voice than in chat. Unlike chat, users do not wait politely.
To handle this, systems usually maintain two layers of memory:
- Short-term memory: current call context
- Long-term memory: user or business data
Importantly, the voice layer should not own context. Instead, the backend should manage it centrally.
Best Practices For Context Management
- Use session-based identifiers
- Store structured conversation state
- Reset memory cleanly after calls
- Avoid sending full transcripts repeatedly
Because of this separation, systems remain scalable and predictable.
How Do Tools And RAG Work In A Live Call AI System?
Voice agents become useful when they can act, not just talk. Tools and RAG enable this.
Tool Calling In Voice Agents
Common tools include:
- Appointment booking
- CRM lookups
- Order tracking
- Ticket creation
However, tool latency can hurt conversation flow. Therefore, systems often:
- Prefetch likely data
- Use async tool execution
- Speak while tools process
RAG In Voice Conversations
RAG allows assistants to:
- Answer policy questions
- Access product knowledge
- Provide account-specific responses
Because RAG queries take time, they must be carefully timed to avoid silence.
Why Is Voice Infrastructure The Missing Layer In Most Live Call AI Systems?
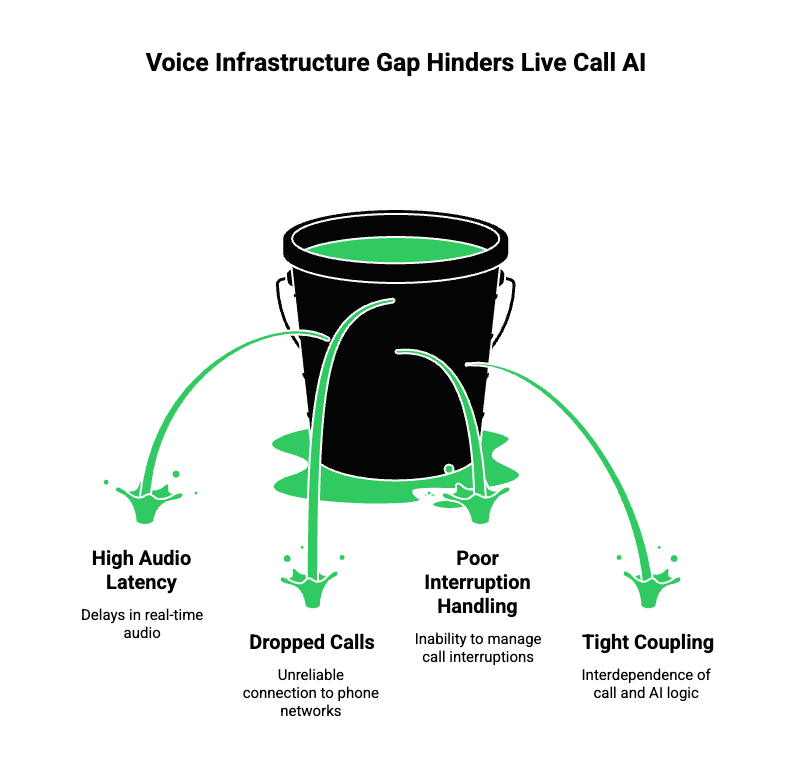
So far, we have explained how real-time AI voice assistants work internally. However, most teams fail not because of AI quality, but because of voice infrastructure complexity.
LLMs, STT, and TTS are accessible today. Yet, connecting them reliably to live phone calls remains difficult. This gap exists because telephony was never designed for streaming AI workloads.
As a result, teams often face:
- High audio latency
- Dropped calls
- Poor interruption handling
- Tight coupling between call logic and AI logic
Therefore, voice infrastructure must act as a neutral, real-time transport layer between phone networks and AI systems.
What Does A Production-Grade Voice Infrastructure Need To Handle?
Before discussing solutions, it is important to define requirements clearly.
A production-ready voice layer must support:
- Real-time bidirectional audio streaming
- Low-latency media transport
- Inbound and outbound call handling
- Global telephony and VoIP compatibility
- High availability and fault tolerance
- Clean separation from AI logic
Without these capabilities, even the best AI voice agent API will fail under real traffic.
Because of this separation, teams can evolve AI logic without rewriting telephony code.
How Does FreJun Teler Fit Into A Real-Time AI Voice Assistant Stack?
FreJun Teler is designed specifically to solve the voice transport problem for AI systems.
Importantly, FreJun Teler:
- Is not an LLM
- Is not a chatbot
- Does not own AI logic
Instead, it acts as a real-time voice infrastructure layer that streams live call audio between phone networks and your AI backend.
What FreJun Teler Provides Technically
- Low-latency audio streaming for live calls
- Bidirectional media pipelines
- Inbound and outbound call support
- SDKs for fast integration
- Compatibility with any LLM, STT, or TTS
Because of this design, teams keep full control over AI behavior while avoiding telephony complexity.
How Do You Build A Real-Time Voice Assistant Using Teler + Any LLM?
Now that the stack is clear, let’s walk through an implementation flow.
Step-By-Step Architecture Using Teler
- A live call is received or initiated.
- FreJun Teler streams raw audio in real time.
- Your backend receives the audio stream.
- Audio is forwarded to your chosen STT.
- Partial transcripts are generated continuously.
- Transcripts are sent to your LLM.
- Tools or RAG are invoked when needed.
- The LLM streams response tokens.
- Tokens are sent to your TTS engine.
- Audio output is streamed back via Teler.
Because each step is streaming-based, latency stays low.
Key Design Principle
Teler handles voice transport.
Your backend handles intelligence.
This separation keeps systems clean and scalable.
How Does AI Voice Agent API Usage Change With Streaming Infrastructure?
Traditional APIs are request-based. However, ai voice agent api usage in live calls must be streaming-first.
Request-Based Vs Streaming APIs
| Feature | Request-Based | Streaming |
| Latency | High | Low |
| Interruptions | Unsupported | Supported |
| Natural Flow | Poor | Strong |
| Scalability | Limited | High |
Therefore, Teler’s streaming approach aligns with how humans actually speak.
What Makes Teler Different From Telephony-First Platforms?
Many platforms start with calling and add AI later. This creates architectural limitations.
Telephony-First Limitations
- Audio handled in chunks
- AI invoked after speech ends
- Long response delays
- Limited context awareness
Teler’s AI-First Design
- Continuous audio streaming
- Early intent detection
- AI owns conversation flow
- Telephony stays abstracted
As a result, Teler works well with modern real time AI voice assistants, not just scripted bots.
How Do You Handle Scaling And Reliability In Live Call AI?
Scaling voice AI is harder than scaling chat. Calls cannot be retried.
To handle scale properly:
- Audio streams must be stateless
- Backend services must autoscale
- Call routing must be resilient
- Failures must degrade gracefully
Common Scaling Strategies
- Horizontal scaling of AI workers
- Session-based routing
- Regional media routing
- Timeout-based fallbacks
Because Teler is built for high availability, teams can focus on AI performance instead of call stability.
What Are Common Mistakes When Building Live Call AI Systems?
Even strong teams make predictable mistakes.
Frequent Pitfalls
- Treating voice like chat
- Blocking calls during tool execution
- Sending full transcripts repeatedly
- Ignoring partial STT results
- Coupling telephony with AI logic
Avoiding these mistakes improves both user experience and system reliability.
When Should You Build Vs Buy Voice Infrastructure?
This decision matters for founders and engineering leads.
Build Voice Infrastructure If:
- Telephony is your core business
- You need custom carrier integrations
- You can invest months of engineering time
Use Infrastructure Platforms If:
- AI logic is your core value
- You want faster time to market
- You need global reliability
Most teams fall into the second category. Therefore, using a platform like Teler makes practical sense.
How Can Teams Get Started With Real-Time AI Voice Assistants Today?
Building live call AI is no longer experimental. The tools are mature, but architecture still matters.
To get started:
- Design your AI pipeline first
- Choose fast, streaming-capable models
- Separate voice transport from intelligence
- Test latency aggressively
- Scale gradually
By combining any LLM, any STT/TTS, and FreJun Teler for voice transport, teams can launch production-grade voice assistants faster and with less risk.
Final Thoughts
Building real-time AI voice assistants is ultimately an infrastructure and systems problem, not just a model problem. While LLMs, STT, and TTS enable intelligence, production success depends on how well audio, latency, and reliability are handled during live calls. Teams that separate voice transport from AI logic gain flexibility, faster iteration, and long-term scalability.
This approach allows any LLM, any STT, and any TTS to work together without locking the system to a single vendor or model. FreJun Teler fits naturally into this architecture by providing the real-time voice infrastructure layer required for live call AI.
Schedule a demo to see how Teler enables low-latency, production-grade AI voice assistants.
FAQs
1. What Is An AI Voice Agent API?
An AI voice agent API connects speech input, language models, tools, and speech output to enable real-time voice conversations.
2. Can I Use Any LLM With A Voice Agent API?
Yes, as long as the LLM supports fast inference and streaming output, it can work in real-time voice systems.
3. Why Is Latency So Critical In Live Call AI?
Because delays above a few hundred milliseconds break conversational flow and make voice assistants feel unnatural.
4. Do Voice Agents Require Streaming STT And TTS?
Yes, streaming STT and TTS are essential for partial responses, interruptions, and low-latency interactions.
5. How Is Live Call AI Different From Chatbots?
Live call AI processes continuous audio streams and must respond instantly, unlike turn-based text chat systems.
6. Can Voice Agents Handle Interruptions Naturally?
Yes, when built with streaming pipelines that support barge-in and mid-speech playback cancellation.
7. Where Does RAG Fit In A Voice Agent?
RAG supplies domain or business knowledge during conversations without embedding all data into the language model.
8. Should Voice Infrastructure Manage Conversation Logic?
No, voice infrastructure should only stream audio; AI logic and context must remain in the backend.
9. Is Building Voice Infrastructure From Scratch Practical?
Only for teams with deep telephony expertise; most teams benefit from using dedicated voice infrastructure platforms.
10. How Fast Can Teams Launch Production Voice Agents?
With proper infrastructure, teams can deploy production-ready voice agents in weeks instead of months.