
Most chatbots sit quietly in a corner of your app. But voice bots? They face the real world, angry customers, noisy lines, split-second expectations. It is not just about adding speech to a chatbot. It is about building trust in real time. In this guide, we show why most voice bot projects fail before they scale, and how FreJun AI helps you build voice experiences that don’t just work, but win. If your AI needs to talk, this is where you start.
Table of contents
- The Hidden Challenge of Building Production-Ready Voice Bots
- Deconstructing the Modern Voice Bot: The Three Core API Layers
- Why Your Voice Infrastructure is the Most Critical Component?
- FreJun: The Voice Transport Layer for High-Performance AI Agents
- DIY Voice Infrastructure vs. Building on FreJun: A Clear Comparison
- How to Build a Scalable Voice Bot: The FreJun Method?
- Best Practices for Developing Enterprise-Grade Voice Bots
- Final Thoughts: Move Beyond DIY and Build on a Solid Foundation
- Frequently Asked Questions (FAQ)
The Hidden Challenge of Building Production-Ready Voice Bots
The promise of artificial intelligence is here. Businesses are eager to deploy sophisticated voice bots that can handle customer service inquiries, qualify leads, and automate outbound campaigns with human-like nuance. The building blocks, powerful Speech-to-Text (STT), Large Language Model (LLM), and Text-to-Speech (TTS) APIs are more accessible than ever. It seems as though assembling a custom voice agent is a simple matter of plugging these services together.
This is where most projects hit a wall.
The real challenge isn’t connecting to an LLM. It’s managing the real-time, bi-directional flow of audio that makes a voice conversation possible. Developers quickly discover that building a voice bot involves far more than just chaining API calls. You are suddenly responsible for managing complex telephony infrastructure, battling network latency, handling call state, and ensuring the crystal-clear audio quality necessary for accurate transcription.
Building this voice transport layer from scratch is a significant engineering challenge. It distracts from the primary goal: creating an intelligent and responsive AI. This is the critical, often-underestimated gap where promising voice bot projects falter, failing to move from a simple proof-of-concept to a scalable, production-grade application.
Deconstructing the Modern Voice Bot: The Three Core API Layers
Before addressing the infrastructure problem, it’s essential to understand the software components that power a voice bot. A functional voice agent is a carefully orchestrated system of three distinct services, each managed via its own API.
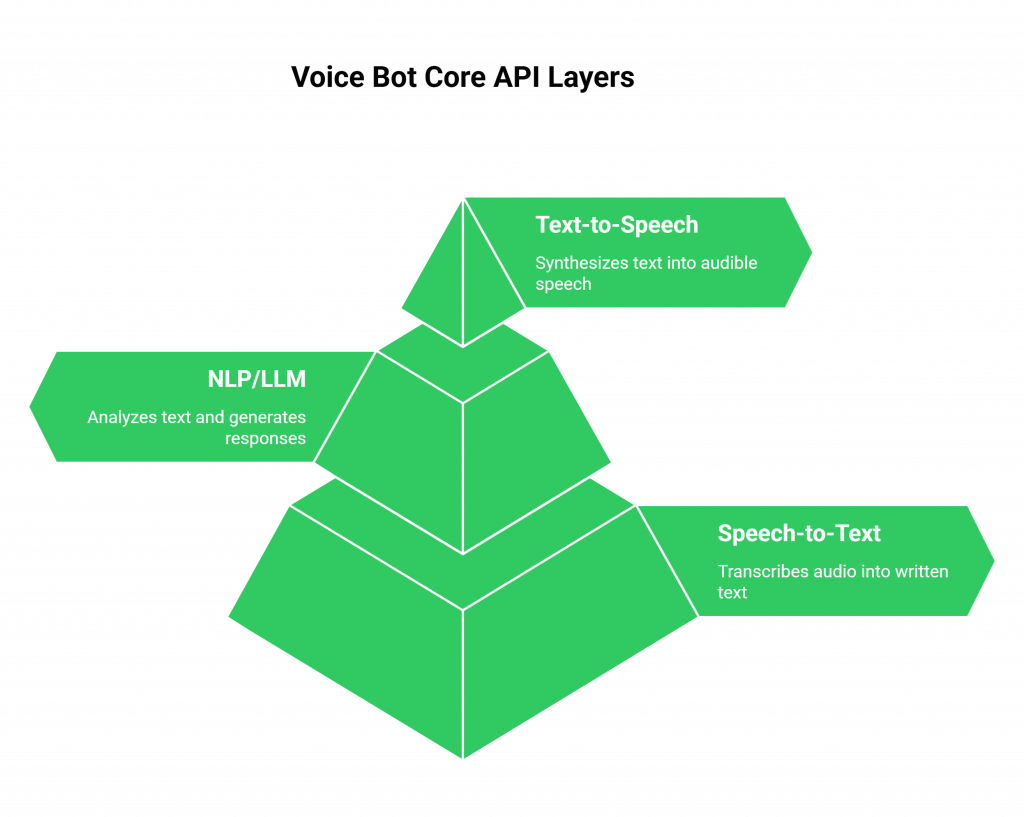
Speech-to-Text (STT)
This is the bot’s “ears.” An STT service takes the raw audio stream from the user and transcribes it into written text in real time. The accuracy and speed of this layer are paramount; if the bot can’t understand what the user said, the entire conversation fails.
- Leading Providers: Google Speech-to-Text, AssemblyAI, Deepgram, Whisper.
Natural Language Processing (NLP) / Large Language Model (LLM)
This is the bot’s “brain.” The system sends the transcribed text from the STT service to an LLM, which analyzes the user’s intent, consults its knowledge base, and generates a contextually appropriate response. This step defines the bot’s personality, logic, and intelligence.
- Leading Providers: OpenAI (GPT-4, GPT-3.5), Anthropic (Claude), Google (Gemini).
Text-to-Speech (TTS)
This is the bot’s “voice.” The text response generated by the LLM is sent to a TTS service, which synthesizes it into audible speech. The quality of the TTS, its naturalness, tone, and clarity, directly impacts the user’s experience and their perception of the bot.
- Leading Providers: ElevenLabs, Google TTS, Amazon Polly.
While developers have a rich ecosystem of these modular Voice Bot APIs to choose from, they all depend on one thing: a flawless, low-latency audio stream.
Also Read: Best VoIP Providers in Kazakhstan for International Calls
Why Your Voice Infrastructure is the Most Critical Component?
You can have the most advanced LLM and the most human-like TTS, but if the audio transport layer is slow or unreliable, your bot will be unusable. Awkward silences, dropped words, and robotic delays shatter the illusion of a natural conversation and frustrate users.
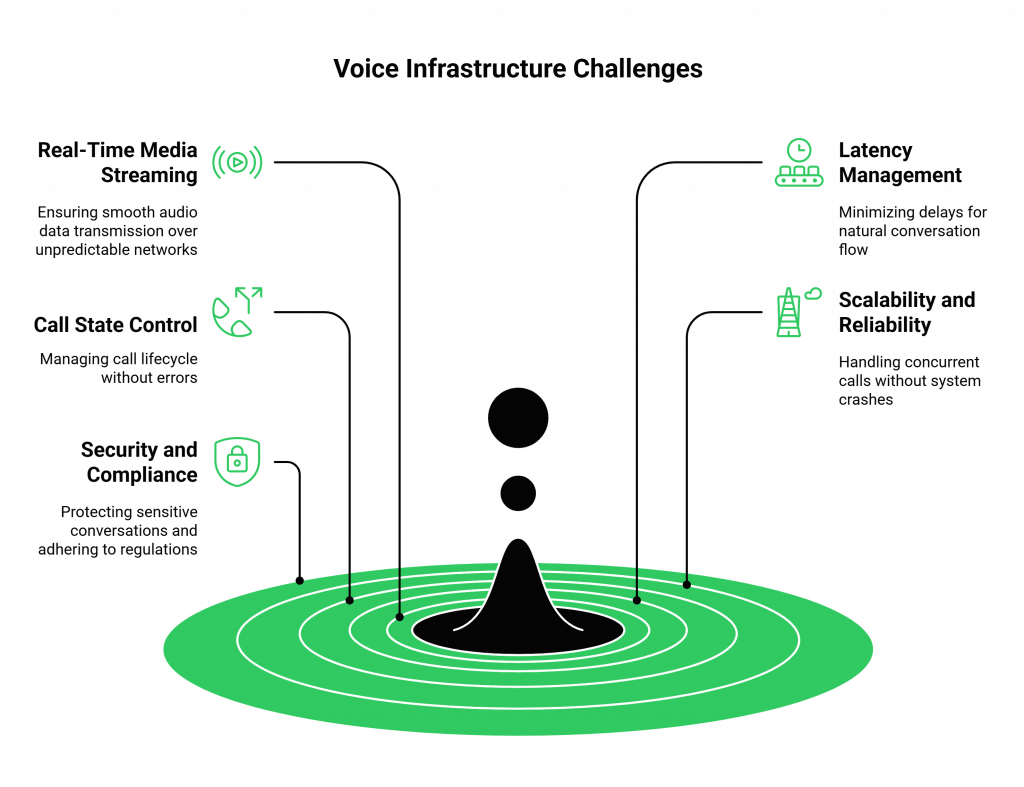
Building and managing this infrastructure yourself means you are responsible for:
- Real-Time Media Streaming: Capturing and transmitting raw audio data over the public internet or telephony networks, which are notoriously unpredictable.
- Latency Management: Minimizing the delay between the user speaking, your AI processing the request, and the voice response being played back. Every millisecond counts.
- Call State Control: Managing the entire lifecycle of a call, initiating, connecting, transferring, and terminating without errors.
- Scalability and Reliability: Ensuring your system can handle one call or ten thousand concurrent calls without crashing. This requires geographically distributed infrastructure and engineering for high availability.
- Security and Compliance: Protecting sensitive conversations and adhering to data privacy regulations across different regions.
This is complex, resource-intensive work. It’s undifferentiated heavy lifting that pulls your focus away from creating a unique and intelligent AI experience.
FreJun: The Voice Transport Layer for High-Performance AI Agents
This is precisely the problem FreJun solves. We handle the complex voice infrastructure so you can focus on building your AI. FreJun is the robust, developer-first transport layer designed for speed and clarity, turning your text-based AI into a powerful, production-grade voice agent.
We provide the foundational API that seamlessly connects the user to your AI stack and back again. Here’s how our platform works:
- Stream Voice Input: Our API captures real-time, low-latency audio from any inbound or outbound call. This crystal-clear audio stream is sent directly to your backend, ready to be processed by your chosen STT service.
- Process with Your AI: Your application maintains full control. You receive the audio stream, transcribe it with your STT, process the text with your LLM, and generate a response. FreJun acts as the reliable and stable connection, ensuring your backend can manage the conversational context without interruption.
- Generate Voice Response: You take the generated audio from your TTS service and simply pipe it to our API. FreJun handles the low-latency playback to the user, completing the conversational loop instantly and naturally.
By abstracting away the complexities of telephony, FreJun provides the most critical set of Voice Bot APIs, the ones that manage the call itself. This allows you to bring your own AI and maintain complete control over your bot’s logic while we ensure the conversation flows perfectly.
DIY Voice Infrastructure vs. Building on FreJun: A Clear Comparison
Choosing the right foundation for your voice bot is a critical strategic decision. The following table illustrates the difference between tackling voice infrastructure yourself versus leveraging a specialized platform like FreJun.
| Feature / Responsibility | DIY Approach (Building from Scratch) | The FreJun Solution (Managed Transport Layer) |
| Real-Time Audio Streaming | Must build and manage custom WebRTC/SIP servers. Prone to jitter and packet loss. | Optimized, low-latency media streaming core. Engineered for vocal clarity. |
| Infrastructure & Scaling | Requires provisioning, managing, and scaling telephony servers globally. High operational overhead. | Built on resilient, geographically distributed infrastructure for high availability. |
| Developer Focus | 60% on telephony/infrastructure, 40% on AI logic. | 100% on AI logic and application features. |
| Latency | A constant battle. Optimizing the full stack is a major engineering effort. | Entire stack is obsessively optimized for minimal latency. No awkward pauses. |
| Time to Market | Months to build a stable, scalable infrastructure. | Launch sophisticated voice agents in days, not months. |
| Call Management | Complex state management logic must be written and maintained in-house. | Simple, powerful SDKs and Voice Bot APIs for complete call control. |
| Integration | Requires deep expertise in telephony protocols to connect to STT/LLM/TTS services. | Model-agnostic platform. Easily connect any STT, LLM, or TTS service. |
| Support & Reliability | You are solely responsible for uptime, security, and troubleshooting. | Guaranteed uptime, security by design, and dedicated integration support. |
The choice is clear. Attempting to build your own voice infrastructure introduces significant risk, cost, and delays. FreJun provides a production-ready foundation so you can innovate faster and with more confidence.
Also Read: Best VoIP Providers in Ukraine for International Calls
How to Build a Scalable Voice Bot: The FreJun Method?
With FreJun handling the transport layer, building a powerful voice bot becomes a streamlined, logical process focused on AI, not infrastructure.
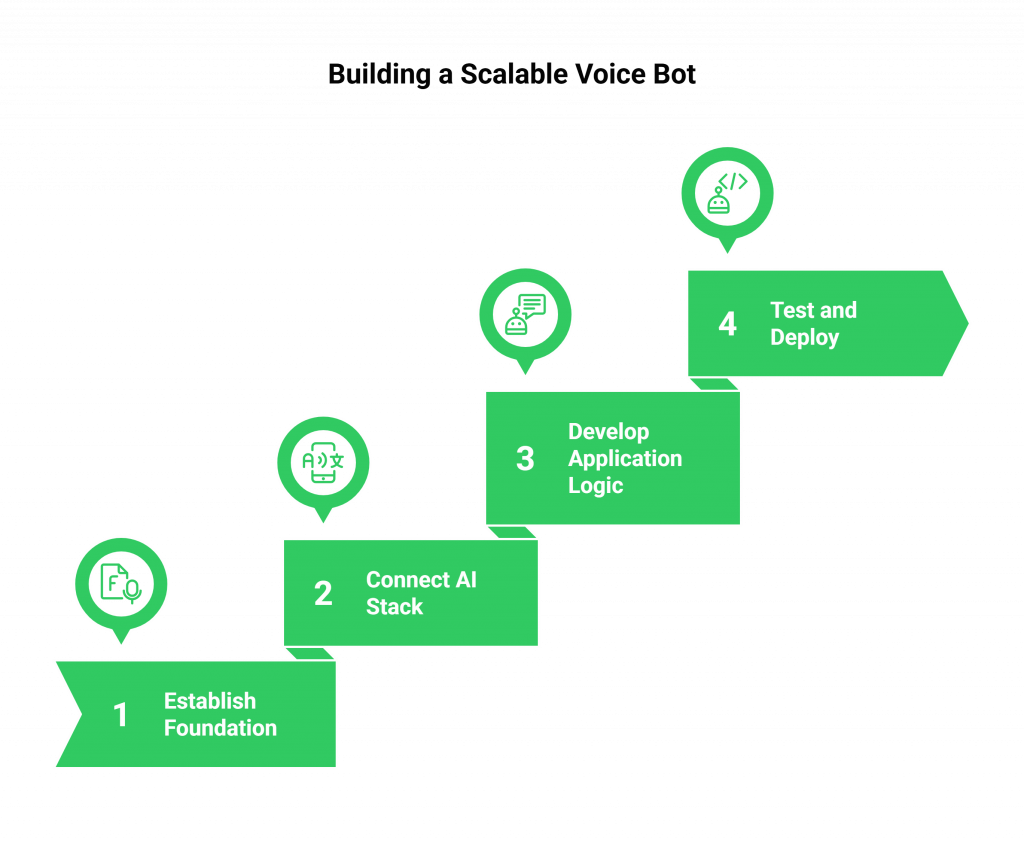
Step 1: Establish Your Voice Foundation with FreJun
This is the most important first step. Instead of wrestling with telephony protocols, you simply sign up for FreJun and get your API key. This gives you instant access to our robust infrastructure for making and receiving calls and streaming audio. Our developer-first SDKs make integration with your application backend straightforward.
Step 2: Choose and Connect Your AI Stack
Because FreJun is model-agnostic, you have complete freedom. Select the best-in-class Voice Bot APIs for your specific use case.
- For Transcription (STT): Choose a provider like AssemblyAI for its real-time streaming accuracy.
- For Intelligence (LLM): Connect to OpenAI’s GPT-4 for its advanced reasoning or any other model that fits your needs.
- For Speech (TTS): Use a service like ElevenLabs for its natural and customizable voices.
You simply point the audio stream from FreJun to your STT endpoint and route the audio output from your TTS back to FreJun.
Step 3: Develop Your Application Logic
This is where you bring your voice bot to life. Using FreJun’s server-side SDKs, you can easily manage the conversation flow. Your code will handle the business logic:
- Receiving the transcribed text from your STT.
- Maintaining conversational context and history.
- Sending the text to your LLM with appropriate prompts.
- Receiving the LLM’s response and sending it to your TTS.
- Streaming the final audio back to the user via the FreJun API.
Our platform ensures your backend maintains full control over the dialogue state.
Step 4: Test, Deploy, and Scale with Confidence
Once your bot is functional, you can leverage FreJun’s reliable infrastructure to deploy it. Test your bot with diverse accents and unexpected user interruptions to refine its performance. As your usage grows, our platform scales effortlessly with you, ensuring every user has a seamless and responsive experience.
Best Practices for Developing Enterprise-Grade Voice Bots
Building a simple bot is one thing; deploying a reliable, enterprise-grade agent requires discipline and adherence to best practices.
- Define a Clear Purpose: Know exactly what the bot is supposed to accomplish. Set clear boundaries and design a graceful hand-off to a human agent when a query goes beyond its capabilities.
- Obsess Over Latency: Speed is everything in a voice conversation. Choose fast Voice Bot APIs for your STT, LLM, and TTS layers and ensure your own backend processing is highly optimized.
- Embrace Composability: The ability to swap out components is a major advantage. If a new, more cost-effective TTS provider emerges, a platform like FreJun makes it easy to switch without rebuilding your entire stack.
- Prioritize Security: Use platforms that offer robust security and compliance features, such as PII redaction and end-to-end encryption, to protect user data.
- Monitor and Iterate: Continuously analyze performance metrics like call success rates, transcription accuracy, user sentiment, and task completion rates. Use these insights to refine your prompts and improve the user experience over time.
Also Read: 13 Best VoIP Providers in Poland for International Calls
Final Thoughts: Move Beyond DIY and Build on a Solid Foundation
The ability to create custom voice experiences is no longer a luxury; it’s a competitive necessity. While the ecosystem of Voice Bot APIs for speech and language processing is mature and accessible, the true differentiator for a successful project is the quality of the underlying voice transport layer.
Wasting valuable engineering resources on building and maintaining complex telephony infrastructure is a strategic error. It slows you down, increases costs, and distracts you from your core objective: building a truly intelligent and valuable AI agent.
FreJun AI provides the critical missing piece. By offering a developer-first, low-latency, and infinitely scalable voice infrastructure, we empower you to focus on what you do best. Bring your own AI, control your own logic, and build powerful, real-time voice bots in days, not months. The future of voice automation is built on a solid foundation, let FreJun AI be yours.
Further Reading –Stream Voice to a Chatbot Speech Recognition Engine via API
Frequently Asked Questions (FAQ)
No. FreJun specializes in providing the voice transport layer. Our platform is model-agnostic, which gives you the freedom and flexibility to choose the best-in-class STT, LLM, and TTS providers for your specific needs. This allows you to maintain full control over your AI stack’s cost, performance, and quality.
While bundled platforms can be good for simple use cases, FreJun is designed for developers who require more control, flexibility, and performance. We focus on perfecting the most difficult part of the equation, the real-time voice infrastructure. This allows you to build truly custom, best-of-breed solutions without being locked into a single provider’s AI ecosystem.
Absolutely. FreJun handle both inbound and outbound call scenarios, allowing you to deploy voice agents for a wide range of use cases, from 24/7 AI receptionists to proactive, personalized outbound campaigns.
Our entire platform is engineered for low-latency conversations. By optimizing the media streaming core and providing a robust, geographically distributed network, we minimize the delays between user speech, AI processing, and voice response, enabling natural, fluid interactions.
Getting started is simple. You need three things: a FreJun account for managing the voice infrastructure, API keys for your chosen STT and TTS services, and an API key for your preferred Large Language Model (LLM). Our comprehensive SDKs and dedicated integration support will guide you through the rest.