
Voice AI sounds simple until you try to ship it. Suddenly you’re tangled in SIP, WebRTC, real-time audio streams, and global telephony headaches. Your AI team turns into a telecom team.
FreJun AI handles all the hard parts of voice infrastructure so you don’t have to. You bring the AI, STT, and TTS stack that suits your use case. We connect it to the world securely, reliably, and in real time. No SDK nightmares required.
Table of contents
- The Challenge: The Hidden Complexity of Voice AI
- What is a Voice Enabled Chatbot?
- The Real Bottleneck: Why Building from Scratch is a Trap
- The FreJun Approach: Separating AI Logic from Voice Infrastructure
- How It Works: Connecting Your AI to the World with FreJun
- FreJun vs. Traditional Development: A Head-to-Head Comparison
- How to Build a Production-Grade Voice Enabled Chatbot with FreJun?
- Final Thoughts: Focus on Your AI, Not Your Infrastructure
- Frequently Asked Questions (FAQ)
The Challenge: The Hidden Complexity of Voice AI
Your development team has a clear directive: build an intelligent, responsive Voice Enabled Chatbot to automate customer service inquiries, qualify sales leads, or handle inbound appointment bookings. You have the AI expertise, a powerful Large Language Model (LLM) in mind, and a clear vision for the conversational flow.
But then reality hits.
Suddenly, you’re not just an AI developer; you’re expected to be a telecom engineer. You’re drowning in a sea of acronyms like SIP, WebRTC, and STUN/TURN. You’re wrestling with real-time audio streaming, managing call states, and trying to minimize the awkward, conversation-killing latency that plagues so many voice applications. The dream of building a cutting-edge AI agent is bogged down by the nightmare of managing complex voice infrastructure.
What is a Voice Enabled Chatbot?
Before we solve the infrastructure problem, let’s establish a clear definition. A Voice Enabled Chatbot is an advanced application that uses spoken language as its primary interface for interaction. Unlike its text-based predecessors, it leverages a sophisticated technology stack to conduct real-time, human-like conversations. The core components that power these agents are:
- Speech-to-Text (STT) or Automatic Speech Recognition (ASR): This technology captures the user’s spoken words and converts them into machine-readable text.
- Natural Language Processing (NLP): Once the speech is transcribed, NLP algorithms analyze the text to understand the user’s intent, extract key entities, and grasp the conversational context.
- AI/LLM Dialogue Management: This is the “brain” of the operation. The AI model or LLM processes the user’s intent and generates a logical, contextually appropriate response.
- Text-to-Speech (TTS): The AI’s text-based response is converted back into audible, natural-sounding speech that is played back to the user, completing the conversational loop.
Together, these technologies allow a Voice Enabled Chatbot to handle complex queries, execute transactions, and provide 24/7 support far beyond the capabilities of a simple IVR system.
The Real Bottleneck: Why Building from Scratch is a Trap
Many organizations attempt to build a voice agent in one of two ways, both of which are deeply flawed.
Approach 1: The All-in-One Platform Trap
Platforms like Amazon Lex or Google Dialogflow offer integrated solutions that bundle STT, NLP, and TTS. While convenient for simple prototypes, they create significant vendor lock-in. You are forced to use their proprietary AI services, which may not be the best-in-class for your specific use case. What if you need a different STT engine to better handle regional accents, or a more expressive TTS voice to match your brand? With these platforms, you sacrifice flexibility for simplicity.
Approach 2: The “Do-It-Yourself” Infrastructure Nightmare
The alternative is to build the voice stack yourself. This path requires deep, specialized expertise in telecommunications. Your team will be responsible for:
- Managing Real-Time Media Streams: Handling raw audio data over protocols like WebRTC.
- Controlling Call Legs: Managing the connection between your service and the user’s phone.
- Ensuring Carrier Interoperability: Integrating with the global telephone network (PSTN).
- Building Resilient Infrastructure: Creating a geographically distributed system to guarantee uptime and clarity.
- Minimizing Latency: Optimizing every millisecond of the audio path to prevent unnatural delays.
This approach diverts your most valuable resource, your AI developers, away from their core competency. They end up building and maintaining voice infrastructure instead of creating the intelligent conversational logic that differentiates your business. This is where projects stall, budgets bloat, and time-to-market stretches from weeks into months or even years.
The FreJun Approach: Separating AI Logic from Voice Infrastructure
There is a better way. FreJun AI was architected to solve this exact problem. We believe that developers should be free to build the most powerful AI imaginable, using the best tools for the job, without ever worrying about the underlying voice complexity.
FreJun is not another chatbot framework. We are the voice transport layer.
Our platform is purpose-built to handle the entire complex voice infrastructure, acting as a robust and reliable bridge between any phone call and your custom AI application. We provide the real-time, low-latency “plumbing” so you can focus 100% of your effort on building your AI.
With FreJun, you bring your own AI stack.
- Bring your own Speech-to-Text service.
- Bring your own Large Language Model or NLP engine.
- Bring your own Text-to-Speech service.
We provide the mission-critical infrastructure that captures voice from any inbound or outbound call and delivers your AI’s response with speed and clarity. This model-agnostic approach liberates you from vendor lock-in and allows you to build a truly bespoke Voice Enabled Chatbot using best-in-class components.
How It Works: Connecting Your AI to the World with FreJun
The elegance of the FreJun architecture lies in its simplicity. We have turned a complex engineering challenge into a straightforward API-driven workflow. Here’s how you can transform your text-based AI into a powerful voice agent.
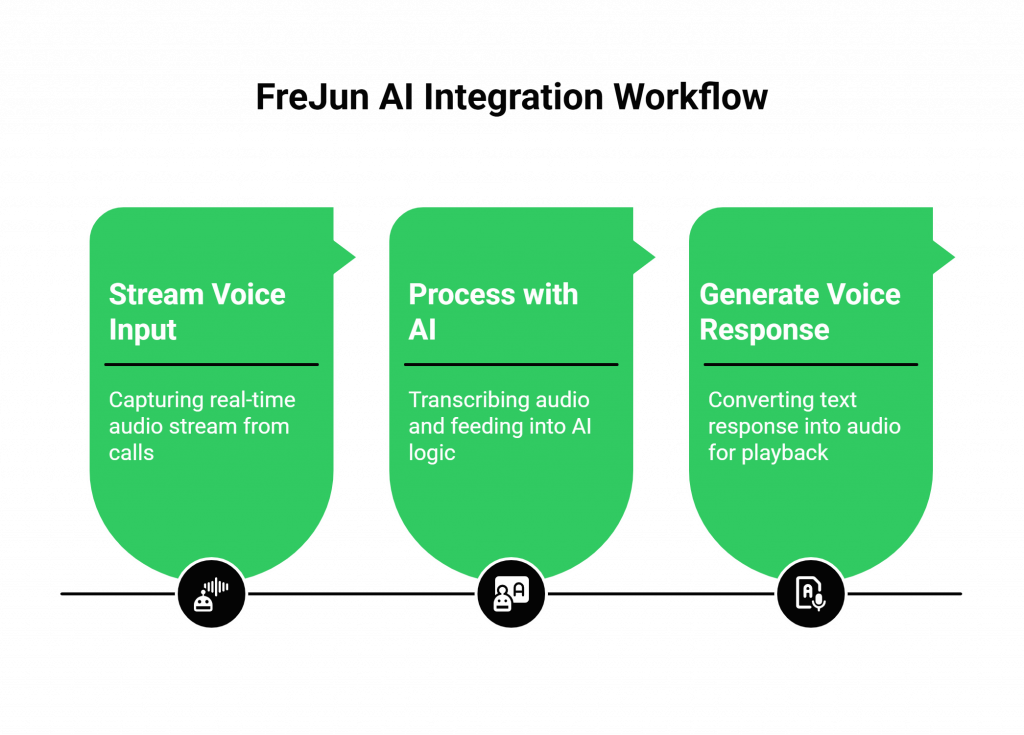
Step 1: Stream Voice Input
When a user makes or receives a call through a number on our platform, FreJun’s API captures the real-time, low-latency audio stream. Whether the call is from a mobile phone, a landline, or a web application, our infrastructure ensures every word is captured clearly and delivered to your application without delay.
Step 2: Process with Your AI (The Magic Happens Here)
FreJun serves as a reliable transport layer for this raw audio stream. You simply direct this stream to your chosen STT provider (e.g., Google, Deepgram, AssemblyAI). The resulting transcription is then fed into your AI logic, whether it’s built on Rasa, Dialogflow, a custom framework, or directly with an LLM provider like OpenAI. Your application maintains complete control over the dialogue state and conversational context.
Step 3: Generate Voice Response
Once your AI generates a text response, you pipe that text to your chosen TTS service (e.g., ElevenLabs, PlayHT, Microsoft Azure). The resulting audio response is then streamed back to the FreJun API, which plays it back to the user over the call with minimal latency. This completes the conversational loop, creating a seamless and natural-sounding interaction.
FreJun vs. Traditional Development: A Head-to-Head Comparison
The strategic advantage of using a dedicated voice transport layer becomes clear when compared to traditional development methods.
| Feature | Building with Traditional SDKs / All-in-One Platforms | Building with FreJun’s Voice Transport Layer |
|---|---|---|
| AI/Model Flexibility | Locked into the platform’s proprietary STT, NLP, and TTS. Limited choice and difficult to customize. | Bring Your Own AI. Use any combination of best-in-class services for STT, NLP, and TTS that fit your exact needs. |
| Infrastructure Management | You must build, manage, and scale complex VoIP infrastructure (SIP/WebRTC), a massive engineering overhead. | Fully Managed & Abstracted. FreJun handles all global voice infrastructure, real-time streaming, and call management. |
| Development Focus | Heavily divided between AI logic and complex, low-level telephony engineering. | 100% Focused on Building AI. Your team dedicates its time to conversational logic and creating a superior user experience. |
| Conversational Latency | Often high and inconsistent due to non-specialized components or poorly optimized self-built stacks. | Engineered for Ultra-Low Latency. Our entire stack is optimized for real-time conversation, eliminating awkward pauses. |
| Developer Control | Limited control over the voice layer. You are subject to the platform’s rules, limitations, and pricing models. | Full Control Over AI Logic. FreJun acts as a transparent, reliable transport layer, giving you complete autonomy. |
| Time to Production | Months or Years. High complexity, steep learning curves, and significant infrastructure builds. | Days or Weeks. Abstract away the hard parts and launch a sophisticated Voice Enabled Chatbot in record time. |
How to Build a Production-Grade Voice Enabled Chatbot with FreJun?
Ready to get your AI talking? Here is a practical, step-by-step guide to developing a sophisticated voice agent using FreJun’s infrastructure.
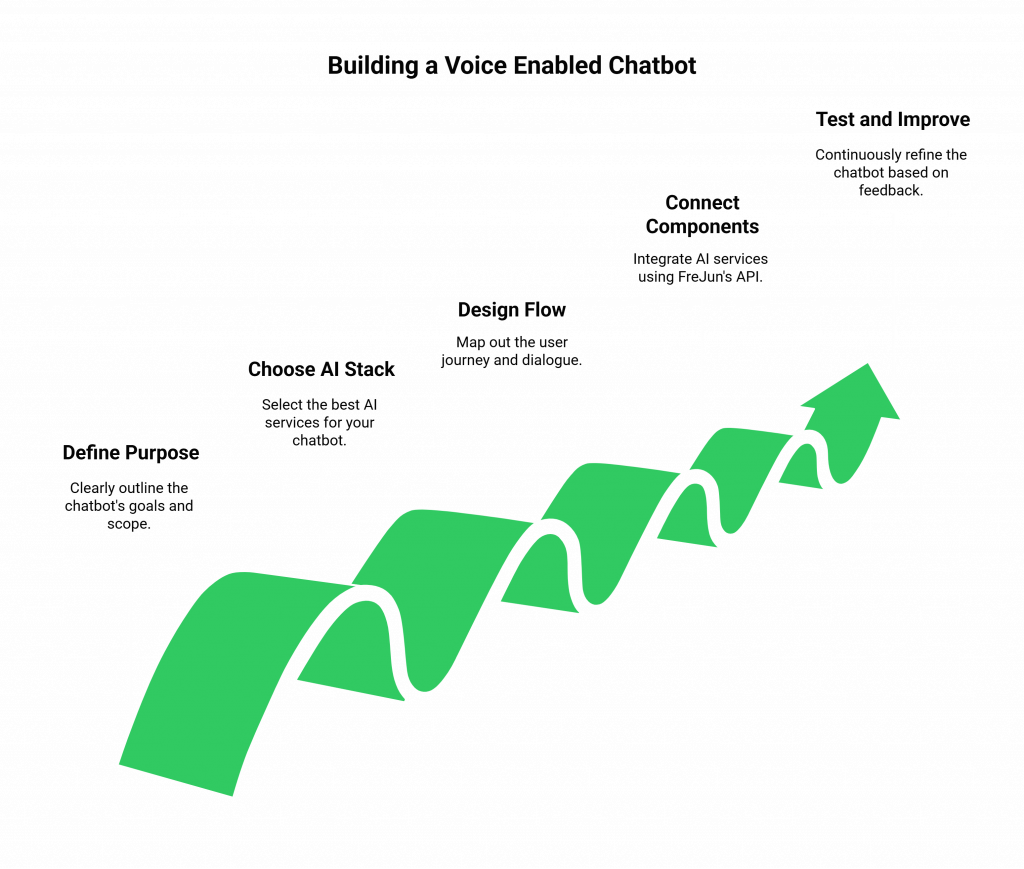
Step 1: Define Your Bot’s Purpose and Scope
First, clearly outline what you want your Voice Enabled Chatbot to achieve. Is it for 24/7 customer support? Inbound lead qualification? Proactive appointment reminders? Defining the use case will inform the entire design of your conversation flow and the complexity of the AI required.
Step 2: Choose Your Best-in-Class AI Stack
This is where the freedom of FreJun’s model shines. Instead of being forced into a single vendor’s ecosystem, you can assemble your dream team of AI services:
- Select an STT Service: Choose a provider known for its accuracy with the accents and languages of your target audience.
- Select an NLP/LLM Framework: Decide on the brain of your bot. You can use open-source frameworks like Rasa for deep customization, managed services like Dialogflow for ease of use, or connect directly to a powerful LLM for more dynamic conversations.
- Select a TTS Service: Pick a voice that aligns with your brand identity. Modern TTS services offer a vast range of incredibly human-like voices and emotional tones.
Step 3: Design the Conversational Flow
Map out the user journey. What are the common intents you need to recognize? What are the key pieces of information (entities) your bot needs to extract? Design your dialogue to be intuitive, handle interruptions gracefully, and provide clear paths for escalation to a human agent if necessary.
Step 4: Connect the Components Using FreJun’s API
This is the core integration step, where FreJun AI acts as the central nervous system.
- Receive the Call: Use FreJun’s API to manage the inbound or outbound call.
- Stream to STT: As the user speaks, take the real-time audio stream provided by FreJun and send it to your chosen STT service’s API.
- Process with AI: Take the text output from your STT and send it to your AI/LLM for processing.
- Generate with TTS: Take the text response from your AI and send it to your chosen TTS service’s API to generate the audio response.
- Respond to User: Stream the audio response from your TTS service back to the FreJun API, which plays it to the user in real-time.
FreJun’s developer-first SDKs for web, mobile, and backend environments simplify this process, allowing you to manage call logic and embed voice capabilities with ease.
Step 5: Test, Deploy, and Continuously Improve
Rigorous testing is crucial. Test your Voice Enabled Chatbot with different accents, background noises, and unexpected user queries. Monitor performance analytics, paying close attention to response latency and intent recognition accuracy. Use this feedback to continuously refine your AI models and conversational flows for an ever-improving user experience.
Final Thoughts: Focus on Your AI, Not Your Infrastructure
The future of digital interaction is conversational, and voice is its most natural medium. Businesses that can deploy sophisticated, reliable voice agents will create more efficient operations and build deeper relationships with their customers.
However, building a truly great Voice Enabled Chatbot comes with the complexities of telecommunications. For too long, developers have faced a tough choice: accept the limitations of a locked-in platform or take on the monumental task of building voice infrastructure from scratch.
FreJun offers a third, strategically superior path. We handle the complex voice infrastructure so you can focus on building your AI. Our model-agnostic, developer-first platform provides the enterprise-grade reliability, security, and low-latency performance required for mission-critical voice applications. By decoupling the AI from the transport layer, we empower you to build faster, innovate freely, and launch the next generation of voice automation in days, not months.
Also Read: 13 Essential Features to Look for in Your Next Call Center Phone System
Frequently Asked Questions (FAQ)
No, and this is our core strength. FreJun provides the voice transport layer and call management infrastructure. You bring your own AI, LLM, STT, and TTS services. This gives you complete control and flexibility to use the best-in-class technologies for your specific needs without vendor lock-in.
Absolutely not. FreJun is designed to abstract away all that complexity. We manage the entire telephony stack, from carrier connections to real-time media streaming, so you can interact with voice through a simple, powerful API.
Yes. FreJun is completely model-agnostic. Our platform can serve as the voice front-end for any AI backend, whether it’s a custom model built with Rasa or PyTorch, a managed NLP service, or a direct integration with an LLM.
Our entire platform is engineered for speed. We use a geographically distributed infrastructure and have optimized every component in the media path from ingestion to processing to playback to minimize latency and eliminate the awkward pauses that break conversational flow.
You need four key components: a Speech-to-Text (STT) engine, a Natural Language Processing (NLP) or LLM brain, a Text-to-Speech (TTS) engine, and a reliable voice transport layer like FreJun to connect them all to the telephone network.