
Voice assistants are everywhere. We use them to get directions, check the weather, and interact with customer service. The convenience is undeniable, but it comes with a nagging question that is becoming increasingly urgent: when I speak to an AI, where does my voice go?
For the vast majority of voice systems, the answer is “the cloud.” Your voice data is sent to a remote server, processed by a massive AI model, and stored for analysis. This creates a significant data privacy risk. What if you could have all the intelligence of a state-of-the-art voice AI, but with the guarantee that your conversations never leave your own secure network?
This is the promise of a local LLM voice assistant. Running the AI’s “brain” on your own hardware gives you full control. It ensures strong data privacy, ultra-low latency, and exceptional reliability. This guide covers the best open models for local LLM voice assistants and explains the hybrid architecture that makes this possible.
Table of contents
Why Should You Be Concerned About Voice Data Privacy?
A voice recording is not like other forms of data; it’s intensely personal. It contains your unique biometric signature, your emotional state, and, of course, the sensitive information you might be discussing. When you send this data to a third-party cloud, you are introducing inherent risks.
This isn’t just a hypothetical concern; consumers are more aware and anxious about their data privacy than ever before. A 2023 survey by McKinsey found that a staggering 85% of consumers are concerned about the amount of data that companies collect on them.
For businesses in regulated industries like healthcare (HIPAA) or finance (GDPR), a single data breach can lead to devastating fines and a complete loss of customer trust. The local LLM voice assistant is the definitive answer to this challenge.
What is a Local LLM Voice Assistant?
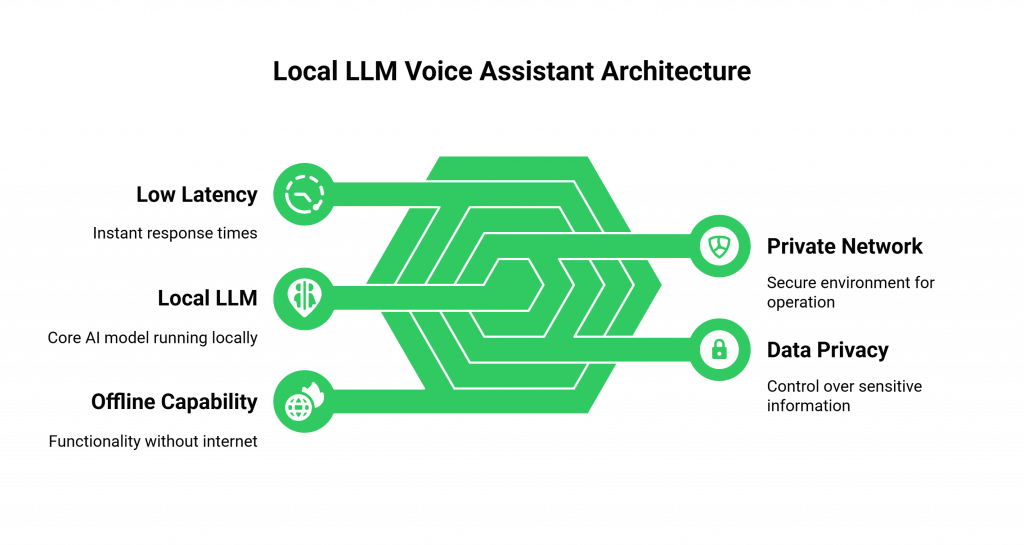
A local LLM voice assistant is a conversational AI where the core “brain”, the Large Language Model, runs on hardware that you control, within your own private network. This is often referred to as an “on-premises” or “edge” deployment.
Think of it this way: a cloud-based voice AI is like calling a public translation service for a private business meeting. You have to send your sensitive conversation out over the phone lines to a third party. A local LLM voice assistant is like having your own expert, in-house translator sitting right there in the secure meeting room with you. The conversation never leaves the four walls of your trusted environment.
This architecture provides three transformative benefits:
- Ultimate Data Privacy: Your conversational data is processed entirely on your own servers, giving you complete control.
- Ultra-Low Latency: Because the AI’s “brain” is on the same local network as the user, the response time is virtually instant.
- Offline Capability: The system can continue to function even if your connection to the wider internet goes down.
Also Read: Voice Interface UX Mistakes Businesses Should Avoid
Which are the Best Open Models for Building a Local LLM Voice Assistant?
The rise of powerful, efficient open-source models is the key technology that has made the local LLM voice assistant a practical reality. Here are some of the top open models that developers are using for on-premises deployments.
- Meta’s Llama 3: The Llama 3 family of models offers a fantastic balance of performance and size. The smaller 8B parameter version is a powerhouse of efficiency, making it an ideal choice for edge deployments where you need a strong reasoning ability without requiring a massive server farm.
- Google’s Gemma Family: Gemma models, particularly the newer Gemma 2, are designed for top-tier performance with a focus on efficiency. They are engineered to run well on a variety of hardware configurations, making them a highly flexible option for building a local LLM voice assistant.
- Mistral AI’s Models: Mistral has made a name for itself with its high-performance models. Models like Mixtral, which use a “Mixture of Experts” (MoE) architecture, offer performance that rivals much larger models, making them an excellent choice for a powerful on-premises deployment.
- Microsoft’s Phi-3: The Phi-3 family represents the cutting edge of “small language models” (SLMs). These models are incredibly compact but deliver surprisingly strong performance, making them perfect for resource-constrained environments or even on-device applications.
Why is FreJun AI Different?
You have chosen your local “brain,” but how do you connect it to the outside world? A customer calling you from their cell phone can’t directly access a private server in your office. You still need a bridge to the global telephone network. This is where the hybrid architecture comes in, and this is where FreJun AI provides the essential missing piece.
We are not an LLM provider. Our philosophy is simple: “We handle the complex voice infrastructure so you can focus on building your AI.”
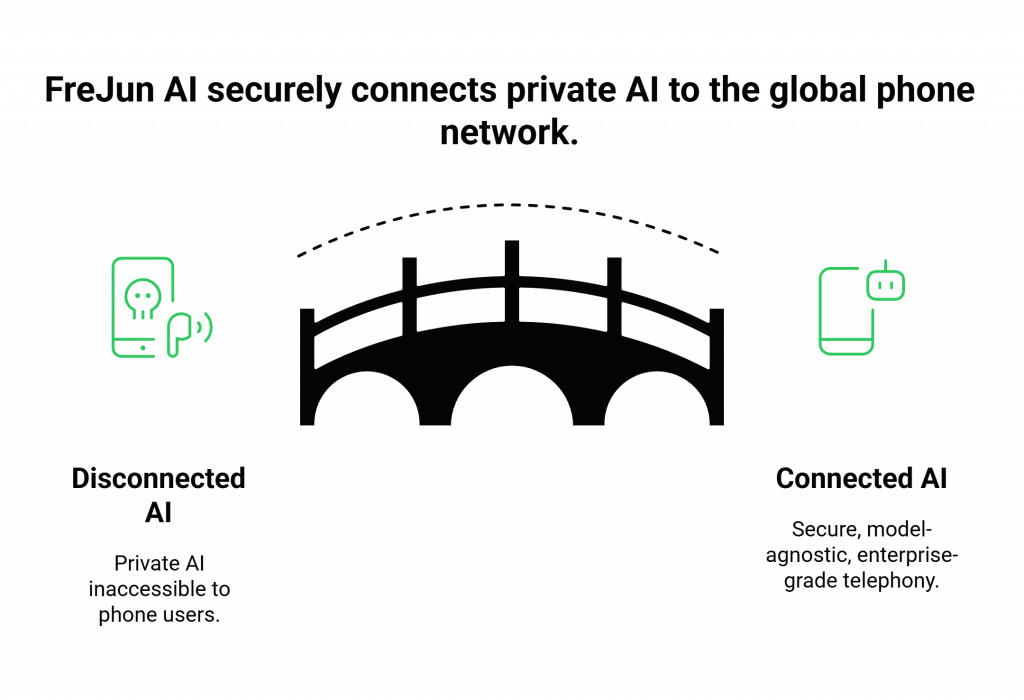
FreJun AI is the secure, cloud-based “nervous system” that connects the public telephone network to your private, on-premises “brain.”
Think of us as the secure, encrypted phone line that runs from the outside world directly into your secure, private office where your local expert (the LLM voice assistant) resides. The conversation is piped in, handled entirely within your local environment, and the response is piped back out. Your conversational data is never processed or stored in the FreJun AI cloud.
- Securely Bridge the Gap: We allow you to connect your private AI to a global phone number without ever exposing your server directly to the public internet.
- Model-Agnostic Freedom: FreJun AI doesn’t care which local LLM you’re running. Llama 3, Gemma, Mistral, our infrastructure is designed to connect to all of them.
- Enterprise-Grade Telephony: You get the reliability and scalability of a global VoIP network without having to manage any of the complex telephony hardware or carrier negotiations yourself.
Ready to connect your private AI to the world of voice? Sign up for FreJun AI developer platform.
Also Read: How Multimodal AI Agents Transform Business Operations
Conclusion
The future of secure, high-performance voice AI is a hybrid one. It’s about combining the absolute data privacy and ultra-low latency of a local LLM voice assistant with the global reach and reliability of a modern cloud telephony platform.
This architecture is no longer a niche, experimental concept. The growth of open-source AI in the business world is explosive. A 2024 survey by Andreessen Horowitz found that a majority of enterprises are already using open-source models, driven by the need for customization, cost-efficiency, and control. By leveraging this trend and partnering with the right voice infrastructure provider, you can build a voice AI that is not only intelligent but also perfectly secure.
Want to learn more about the hybrid architecture that powers the most secure voice bots? Schedule a demo with FreJun AI today.
Also Read : Outbound Call Center Software: Essential Features, Benefits, and Top Providers
Frequently Asked Questions (FAQs)
The key benefits include strong data privacy, as conversations never leave your network. It offers low latency since responses don’t rely on distant cloud servers, and high reliability. Because it continues working even if your internet connection fails.
The main benefits are data privacy (conversations never leave your network), low latency (responses are faster because there’s no trip to a distant cloud), and reliability (it can work even if your internet connection goes down)
“On-premises” means the software and hardware are located at the physical site of the business, such as in your own data center or office, rather than being hosted by a third-party cloud provider.
This largely depends on the model size. Smaller models can run on a high-end desktop with a strong GPU. While larger ones like the 70B Llama 3 or 27B Gemma 2 need a dedicated server equipped with one or more powerful, data center-grade GPUs.
The models themselves are typically free to download and use, even for commercial purposes (though you must always check the specific license terms). However, you will be responsible for the significant costs of the hardware require to run them.
These terms are often used interchangeably. “Local” or “on-premises” usually refers to a server in your own data center. “Edge” can refer to that, or it can refer to an even smaller deployment on a specialized “edge device” located even closer to the user, like in a factory or a retail store.
You have the same choice for the “ears” and “mouth.” You can use cloud-based STT and TTS APIs for convenience, or for ultimate privacy, you can also run open-source STT and TTS models on your local hardware alongside your voice LLM.
The AI processing can be completely offline. However, to make or receive a phone call from the public telephone network, you will still need a connection to a voice infrastructure provider like FreJun AI, which bridges your local system to the global network.
FreJun AI acts purely as a secure transport layer in this model. We stream encrypted audio from call to your local system and stream audio response from your system back to caller. We do not process or store the content of your conversations.
This is a great use case. A local LLM can listen to live calls via FreJun AI. That will analyze conversations between agents and customers in real time, and instantly show helpful suggestions on the agent’s screen. Since it runs locally, it’s extremely fast and fully private.