
You have a brilliant conversational AI, powered by a state-of-the-art Large Language Model (LLM), trained on your data, and ready to answer customer queries with uncanny accuracy. You’ve perfected the logic, the dialogue flows, and the response generation. In a text-based environment like a web chat, it’s flawless.
Now comes the hard part: making it talk.
Table of contents
- The Real Challenge in Building Voice AI Isn’t the Brain, It’s the Nervous System
- What is an API-First Approach in Conversational AI?
- Why a True API-First Strategy is Crucial for Voice
- The Anatomy of a Modern Voice AI Stack
- FreJun’s Role: The API-First Voice Transport Layer
- Building from Scratch vs. FreJun’s API-First Platform: A Head-to-Head Comparison
- Best Practices for Building with FreJun’s Voice API
- Final Thoughts: Stop Building Plumbing, Start Building Intelligence
- Frequently Asked Questions (FAQ)
The Real Challenge in Building Voice AI Isn’t the Brain, It’s the Nervous System
The moment you decide to move from text to voice, you enter a different world of complexity. The challenge is no longer just about the intelligence of your AI, the “brain”, but about the intricate infrastructure that connects it to a live phone call, the “nervous system.” This involves managing real-time audio streams, handling telephony protocols, minimizing latency to avoid awkward silences, and ensuring crystal-clear audio quality.
Many development teams, proficient in AI and software logic, find themselves suddenly entangled in the specialized, resource-intensive domain of telecommunications engineering. They spend months building and debugging the complex voice plumbing instead of refining the AI core. This is where the development lifecycle stalls, budgets inflate, and the project’s time-to-market extends from weeks to quarters or even years. The problem isn’t the AI; it’s the infrastructure.
What is an API-First Approach in Conversational AI?
To solve complex software challenges, modern development teams adopt an API-First methodology. This approach fundamentally shifts the development process. Instead of building a product and then creating APIs to expose its features, an API-First strategy treats the Application Programming Interface (API) as the central, primary product.
The process begins by designing and documenting the API contract before a single line of application code is written. This contract, often defined using standards like OpenAPI, serves as the blueprint for the entire system.
The core tenets of an API-First approach include:
- Prioritizing Interoperability: The API is designed to be easily consumed by various clients, be it a web app, a mobile app, or another backend service.
- Enabling Parallel Development: With a clear API contract in place, frontend and backend teams can work independently and simultaneously, dramatically accelerating the development timeline.
- Designing for Scalability: The API is built from the ground up to be robust, consistent, and ready for future integrations and increased demand.
In essence, you build the foundation and the doorways before you furnish the rooms. This ensures everything connects seamlessly and can be modified or expanded without demolishing the entire structure.
Why a True API-First Strategy is Crucial for Voice
For voice-based conversational AI, an API-First design isn’t just a best practice; it’s a necessity for creating scalable, maintainable, and effective solutions. Voice agents must often integrate with dozens of systems, CRMs, databases, and third-party services, and operate across multiple channels like phone calls, web widgets, and mobile apps. A standardized API makes these integrations manageable rather than chaotic.
However, applying this principle to voice reveals a critical gap. While you can adopt an API-First approach for your AI’s logic (e.g., creating an endpoint for your LLM), you nevertheless remain left with the colossal task of building the API for the voice layer itself. Consequently, this includes APIs for:
- Capturing real-time, low-latency audio from a live phone call.
- Streaming that raw audio data to your Speech-to-Text (STT) service.
- Receiving generated audio from your Text-to-Speech (TTS) service.
- Streaming the response back to the caller with minimal delay.
This is the heavy lifting that sidetracks even the most capable AI teams. The solution is to extend the API-First strategy one level deeper: by using a platform that has already built the complex voice infrastructure API for you.
This is the FreJun philosophy. We provide the robust, production-grade voice infrastructure API so you can focus exclusively on building and refining your AI.
The Anatomy of a Modern Voice AI Stack
To understand where a platform like FreJun fits, it helps to visualize the complete architecture of a voice conversational AI system. The process is a high-speed, sequential chain where latency at any step can ruin the user experience.
- Voice Transport & Call Management: This is the foundational layer. It establishes and maintains the phone call, captures the user’s voice as a raw audio stream, and delivers the AI’s audio response back to the user. This is the “plumbing.”
- Speech-to-Text (STT): Your chosen STT service receives the raw audio stream from the transport layer and transcribes it into text in real-time.
- AI Logic & Dialogue Management: This serves as your “brain.” Furthermore, we send the transcribed text to your AI, whether it’s a custom NLU model or a powerful LLM which processes the input, manages the conversational context, and generates a text response.
- Text-to-Speech (TTS): Your chosen TTS service takes the text response from your AI and synthesizes it into a natural-sounding audio file or stream.
- Return to Transport Layer: We pipe the generated audio back to the voice transport layer, which then plays it back to the user over the phone call, consequently completing the conversational loop.
Traditionally, developers had to build, integrate, and optimize all five of these components. The most difficult and specialized part is the first step: the voice transport layer.
FreJun’s Role: The API-First Voice Transport Layer
FreJun AI operates as the dedicated, API-First voice transport layer. We don’t provide the STT, LLM, or TTS services. Instead, we provide the critical infrastructure that connects them all together over a live phone call, engineered from the ground up for speed and clarity.
This model-agnostic approach is our greatest strength and your biggest advantage. It means you maintain full control over your AI stack. You can bring your own AI, connecting to any STT provider, LLM, or TTS service you choose.
Here’s how it works with FreJun:
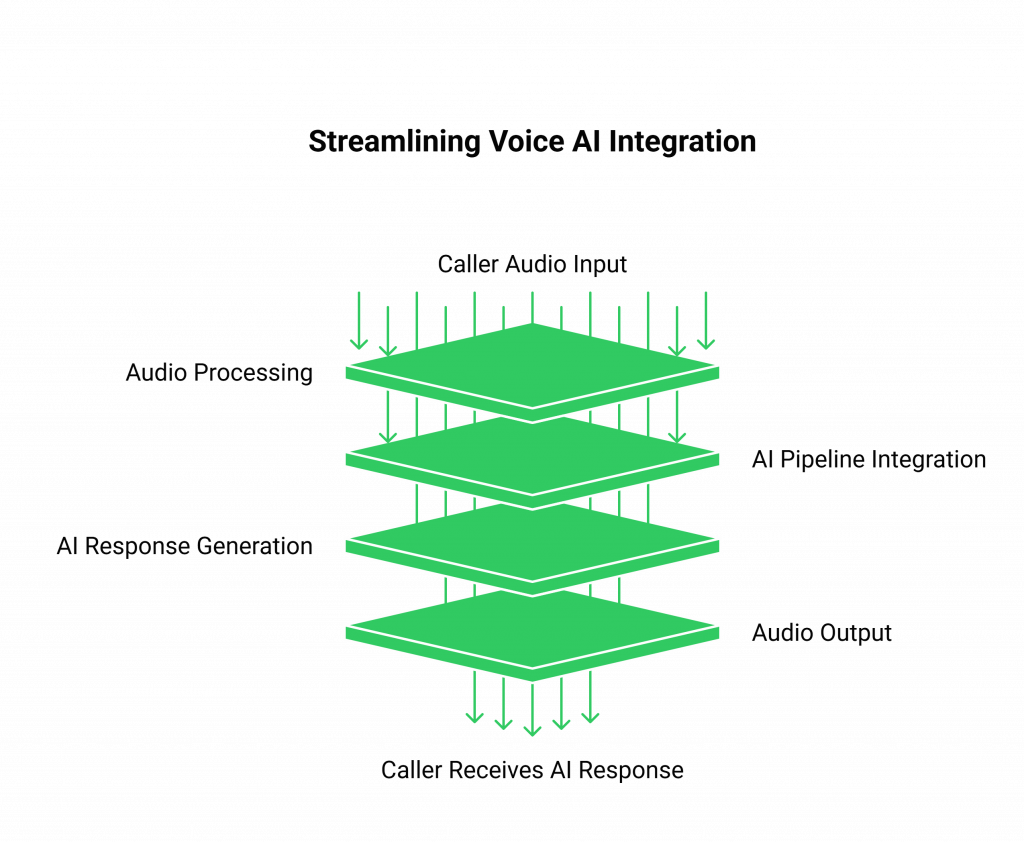
- Stream Voice Input: Our API captures real-time, low-latency audio from any inbound or outbound call and streams it directly to your application endpoint.
- Process with Your AI: Your backend receives the audio stream, sends it to your preferred STT service for transcription, and then passes the text to your LLM for processing. You maintain full control over the dialogue state and context.
- Generate Voice Response: Once your AI generates a text response, you pipe it through your chosen TTS service. You then send the resulting audio stream to FreJun’s API, which plays it back to the user with minimal latency.
We handle the complexities of telephony, audio codecs, and real-time streaming, allowing your API-First development approach to focus on the AI, not the infrastructure.
Building from Scratch vs. FreJun’s API-First Platform: A Head-to-Head Comparison
Choosing how to power your voice agent is a critical decision. Here’s how building the voice layer yourself compares to leveraging FreJun’s specialized platform.
| Feature / Aspect | DIY / Building Voice Infrastructure from Scratch | Using FreJun’s API-First Platform |
| Voice Infrastructure API | High Complexity: Requires building and maintaining telephony connections, media servers, and streaming protocols from the ground up. | Pre-Built & Managed: A robust, documented, and production-ready voice API is provided out-of-the-box. |
| Development Speed | Months to Years: Significant time spent on specialized telecommunications engineering, debugging, and testing. | Days to Weeks: Focus immediately on AI integration using FreJun’s comprehensive SDKs and APIs. |
| AI Model Flexibility | Potentially Rigid: The infrastructure is often tightly coupled with the initial choice of STT/TTS services, making changes difficult. | Completely Model-Agnostic: Bring your own AI. Connect to any LLM, STT, or TTS provider. Swap them out as better models emerge. |
| Latency Management | Difficult to Optimize: Achieving low latency across the entire stack requires deep expertise in audio processing and network engineering. | Engineered for Low Latency: The entire FreJun stack is optimized for real-time media streaming to enable natural conversations. |
| Scalability & Reliability | Capital Intensive: Requires building and managing a geographically distributed, high-availability infrastructure to handle call volume. | Managed & Scalable: Built on resilient, geographically distributed infrastructure engineered for high availability and enterprise scale. |
| Maintenance & Support | Dedicated Team Required: Ongoing maintenance, carrier negotiations, and troubleshooting fall entirely on your in-house team. | Fully Supported: FreJun manages the infrastructure, and our team provides dedicated integration support. |
Best Practices for Building with FreJun’s Voice API
Once you’ve chosen to build on a solid foundation, success comes from following best practices that leverage the platform’s strengths.
Architect for a Modular AI Stack
Since FreJun is model-agnostic, treat your AI components as interchangeable modules. This allows you to experiment with and upgrade your STT, LLM, and TTS services independently. You might start with one provider for cost-effectiveness and later switch to another for higher accuracy, all without changing your core integration with FreJun’s voice API.
Utilize SDKs to Accelerate Development
We design FreJun to provide comprehensive client-side and server-side SDKs. Furthermore, we engineer these tools to handle the boilerplate code for establishing connections and streaming media, consequently allowing your developers to embed voice capabilities into web or mobile applications and manage backend call logic with just a few lines of code.
Maintain Full Control of Conversational Context
FreJun acts as a stable and reliable transport layer, but it is intentionally stateless. Your application is the single source of truth for the dialogue. This is a powerful feature, as it gives you complete control to track and manage the conversational context on your backend. You can implement sophisticated context management strategies that are perfectly tailored to your use case, without being limited by the transport platform.
Design for Speed Across Your Entire Stack
FreJun eliminates the latency in the voice transport portion of the conversation. However, to create a truly natural-sounding interaction, you must also optimize the processing time of your own services. Therefore, choose STT, LLM, and TTS providers known for their speed. Furthermore, the faster your stack can process input and generate a response, the faster FreJun can deliver it, consequently creating a fluid conversational flow that delights users.
Final Thoughts: Stop Building Plumbing, Start Building Intelligence
The goal of creating a voice-based conversational AI is to build a smarter, more efficient, and more human-like way to interact with technology. The value lies in the quality of that conversation, the accuracy of the answers, the relevance of the information, and the natural flow of the dialogue.
For too long, development teams have been forced to divert their focus from this core mission to the painstaking task of building the underlying infrastructure. They’ve become plumbers instead of architects, spending their most valuable resources on connecting pipes instead of designing intelligent systems.
FreJun changes this paradigm. By providing an enterprise-grade, API-First voice transport layer, we abstract away the immense complexity of real-time voice communication.
We give you the reliable, low-latency nervous system so you can dedicate 100% of your energy to building the best possible brain.
With our robust API, comprehensive SDKs, and dedicated support, you can finally move from concept to a production-grade voice agent in days, not months.
Further Reading – A Developer’s Guide to Embedding AI Voice Chat in Your App
Frequently Asked Questions (FAQ)
An API-First approach means that the APIs connecting the different components of the voice AI system (voice transport, STT, AI logic, TTS) are designed and documented before the applications themselves.
No. FreJun is a dedicated voice transport layer. We provide the API and infrastructure to connect a live phone call to your AI services. You bring your own Speech-to-Text (STT), Large Language Model (LLM), and Text-to-Speech (TTS) services.
Our entire platform is built around real-time media streaming. The stack is obsessively optimized to minimize the delay between a user speaking, your AI processing the request, and the voice response being played back.
To get started, you need your own AI logic (like a chatbot or LLM integration), a subscription to a third-party STT service, and a subscription to a third-party TTS service. FreJun provides the developer-first SDKs and the voice API to bridge the gap between these services and a live phone call.
Absolutely. FreJun’s API is model-agnostic. Because we act as the transport layer, you can connect to any AI chatbot, NLU engine, or Large Language Model on your backend. Our platform simply provides the real-time voice stream for your chosen model to interact with.
We simplify development by abstracting away the most complex part of building a voice agent. Your team doesn’t need to become experts in VoIP, WebRTC, or audio codec management.