
Have you ever tried to have a conversation on a walkie talkie? You press the button and say “Over” and then wait. There is a pause. Then the static clears and your friend answers. It is fun for a game but it is terrible for a real conversation.
Now imagine that same delay happening on a customer support call. You explain your problem. There is a two second silence. You think the line is dead so you start talking again just as the agent starts talking. You interrupt each other and you apologize. They apologize. It is awkward and frustrating.
In the world of software development this delay is called latency. When you are building a modern communication app using a voice API integration latency is your biggest enemy.
You can have the smartest AI model and the most beautiful user interface and the best features in the world. But if the audio takes too long to travel from the speaker to the listener the experience falls apart.
In this guide we will explore why speed is the single most important metric in voice deployment. We will look at the physics behind the delay and how it impacts AI voice agents and how infrastructure platforms like FreJun AI utilize advanced routing to ensure your conversations happen in real time.
Table of contents
- What Exactly Is Latency in Voice Communications?
- How Does Latency Affect the User Experience?
- Why Is Latency Even More Important for AI Voice Agents?
- What Are the Main Causes of High Latency?
- How Does Infrastructure Impact Voice API Integration?
- How Can Developers Measure and Monitor Latency?
- How Do Codecs Play a Role in Speed?
- How Does FreJun AI Solve the Latency Problem?
- What Is the Future of Low Latency Voice?
- Conclusion
- Frequently Asked Questions (FAQs)
What Exactly Is Latency in Voice Communications?
Latency is simply the time it takes for a packet of data to travel from its source to its destination. In a voice call we measure the “Round Trip Time” or RTT. This is the time it takes for you to speak and for your voice to reach the other person and for their reply to reach you.
Voice is different from other types of data. If an email arrives two seconds late nobody notices. If a webpage takes two seconds to load it is annoying but acceptable. But voice must be real time.
According to the International Telecommunication Union which sets global standards for communications a one way delay of up to 150 milliseconds is acceptable for most user applications. Once the delay exceeds 150 milliseconds users start to notice a lag. If it goes over 300 milliseconds the conversation becomes difficult to sustain.
When deploying a voice API integration developers must fight to keep this number as low as possible. Every millisecond counts.
How Does Latency Affect the User Experience?
High latency creates a psychological barrier between speakers. It breaks the natural rhythm of human interaction.
The Over Talking Phenomenon
Humans use subtle cues to know when to speak. We pause for a fraction of a second to let the other person answer. High latency messes up these cues. You finish your sentence and wait. The other person has not heard you yet so they stay silent. You think they did not hear you so you start repeating yourself. Suddenly they answer. Now you are both talking at once. This makes the user feel like the system is broken.
The Perception of Intelligence
This is especially true for automated systems. If a user asks an AI agent a question and there is a long pause the user assumes the AI is “dumb” or confused. Fast responses are associated with competence. Slow responses breed distrust.
Customer Abandonment
In a sales or support context frustration leads to hanging up. If the connection feels laggy or distant customers are more likely to end the call before their issue is resolved. This directly impacts customer satisfaction scores (CSAT) and revenue.
Also Read: What Ethical Issues Should Leaders Consider When Building Voice Bots?
Why Is Latency Even More Important for AI Voice Agents?
The rise of AI has made low latency infrastructure even more critical.
When two humans talk the only delay is the network. But when a human talks to an AI there are three sources of delay.
- Transport: Sending the voice to the cloud.
- Processing: The AI has to transcribe the audio (STT) and think of an answer (LLM) and generate the voice (TTS).
- Return: Sending the audio back to the user.
The AI processing part takes time. It might take 500 to 1000 milliseconds for the AI to “think.” This means you have very little “budget” left for network latency.
If your voice API integration adds another 500 milliseconds of network lag on top of the AI processing the total delay becomes 1.5 seconds. That is an eternity in a conversation.
This is where FreJun AI becomes essential. We handle the complex voice infrastructure so you can focus on building your AI. By optimizing the transport layer to be nearly instant FreJun gives your AI more time to process ensuring the total interaction remains fast and fluid.
What Are the Main Causes of High Latency?
To fix latency you have to understand where it comes from. It is usually a combination of three factors.
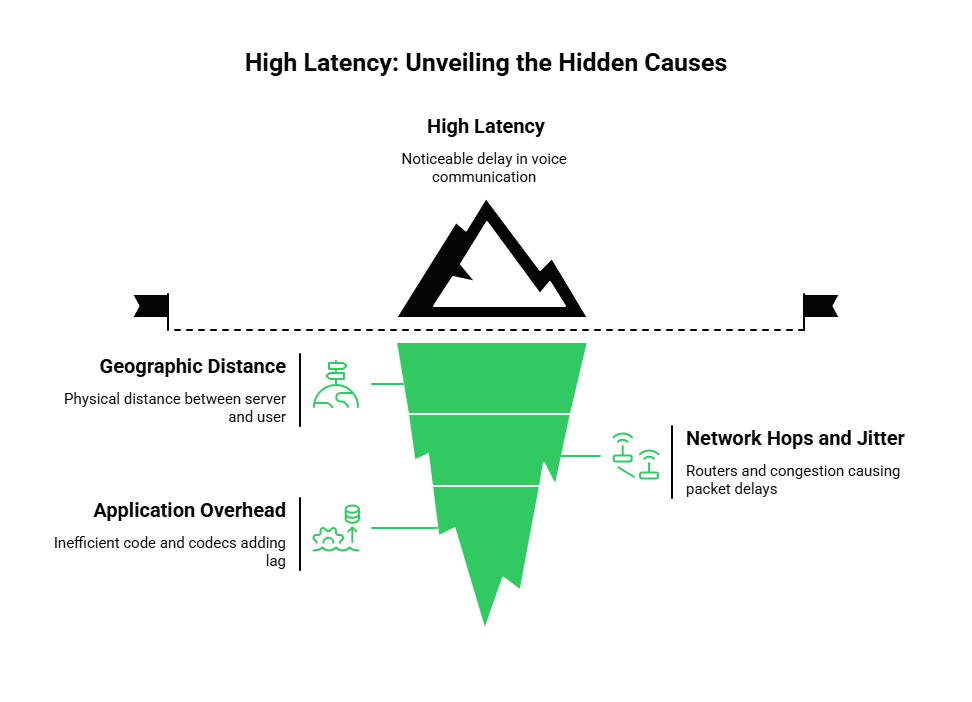
1. Geographic Distance
Data travels at the speed of light but the speed of light is finite. If your server is in New York and your user is in Sydney the data has to travel thousands of miles. This adds unavoidable physical delay.
2. Network Hops and Jitter
The internet is not a direct wire. Your voice packets jump from router to router. Each jump (or hop) takes processing time. If one of those routers is congested packets get stuck in a queue. This causes jitter (variation in delay) which forces the system to buffer the audio adding more delay.
3. Application Overhead
Poorly written code or inefficient codecs can add delay. If your application takes too long to encode the audio before sending it via the voice API integration you are adding lag before the data even leaves the device.
Here is a breakdown of where the delay typically hides.
| Source of Latency | Cause | Impact on Call |
| Propagation | Physical distance | Constant delay based on location |
| Serialization | Pushing bits onto the wire | Minimal impact on high speed links |
| Routing/Queuing | Congestion at routers | Variable delay (Jitter) |
| Buffering | Waiting for packets to arrive | Significant delay to smooth audio |
| Processing | Encoding/Decoding audio | Variable based on CPU power |
How Does Infrastructure Impact Voice API Integration?
Many developers make the mistake of treating voice packets like web traffic. They route calls over the public internet without optimization.
The public internet is a “best effort” network. It does not promise that your data will arrive on time. It just promises it will try.
For high quality voice you need a specialized network. This is why FreJun Teler offers elastic SIP trunking.
Elastic SIP trunking provides a more direct and dedicated path for your voice traffic. It connects your application directly to the Public Switched Telephone Network (PSTN). This bypasses many of the congested public routes that cause lag.
When you choose a provider for your voice API integration you are really choosing their network. FreJun utilizes a distributed architecture. We have Points of Presence (PoPs) all over the world. This ensures that a user in Europe connects to a server in Europe and a user in Asia connects to a server in Asia keeping the travel distance short.
Also Read: How Can Businesses Predict ROI Before Building Voice Bots?
How Can Developers Measure and Monitor Latency?
You cannot improve what you do not measure. A robust deployment strategy involves constant monitoring.
Round Trip Time (RTT) Logs
Your API should provide logs that show the average RTT for each call. If you see a spike in latency in a specific region you know there is a network issue to investigate.
Mean Opinion Score (MOS)
This is the gold standard for voice quality. It rates the call from 1 (Bad) to 5 (Excellent). Latency drags this score down heavily. FreJun provides analytics that help you track the quality of your calls over time.
Real Time Control Protocol (RTCP)
This protocol runs alongside the media stream. It provides live feedback on packet loss and delay. Developers can use this data to adjust the call quality on the fly such as switching to a lower bandwidth codec if the network slows down.
Ready to upgrade your infrastructure for speed? Sign up for FreJun AI to access our low latency network.
How Do Codecs Play a Role in Speed?
A codec is the software that compresses your voice. It shrinks the file size so it can travel faster. But there is a trade off.
- High Compression: Creates smaller packets that travel fast but takes more CPU time to squeeze and unsqueeze.
- Low Compression: Takes less CPU time but creates big packets that might clog the network.
Modern voice platforms use adaptive codecs like Opus. Opus is smart. It looks at the network. If the connection is fast it sends high quality audio. If the connection is slow it shrinks the audio instantly to ensure it arrives on time.
FreJun AI supports these modern codecs. Our infrastructure negotiates the best possible format for every call ensuring that speed and quality are balanced perfectly.
How Does FreJun AI Solve the Latency Problem?
We designed our platform with one goal which is to make voice real time.
Global Media Routing
We do not hairpin traffic. If two people are talking in London we keep the traffic in London. We do not send it to a server in California and back. This “local media processing” drastically cuts down delay.
Streaming Architecture
For AI integration we use a streaming architecture. We do not wait for the user to finish a sentence before we start sending data. We stream the audio in real time chunks. This allows the AI to start processing the beginning of the sentence while the user is still finishing the end of the sentence. This parallel processing makes the voice API integration feel instant.
Carrier Grade Connections
Through FreJun Teler we maintain high quality interconnections with major global carriers. This ensures that the “last mile” of the call from our cloud to the user’s phone is as clean and fast as possible.
What Is the Future of Low Latency Voice?
The demand for speed is only increasing. With the rollout of 5G networks and edge computing we are moving toward a world where voice latency is virtually zero.
Edge computing involves moving the servers even closer to the user to the “edge” of the network. FreJun is constantly expanding our edge network to ensure that our voice API integration remains the fastest in the market.
As AI models get smaller and faster the bottleneck will shift entirely to the network. Having a partner like FreJun that prioritizes infrastructure will be the deciding factor between a successful voice app and one that feels sluggish and outdated.
Also Read: What Future Trends Will Define Building Voice Bots Over The Next Five Years?
Conclusion
Latency is the invisible wall that separates a good user experience from a bad one. In the world of voice communication where timing is everything you cannot afford to be slow.
A successful voice API integration requires more than just functional code. It requires a deep understanding of network physics and a robust infrastructure strategy.
By choosing a platform that prioritizes low latency you ensure that your conversations are natural and your agents are efficient and your customers are happy. FreJun AI provides the global reach and the optimized routing and the elastic capacity needed to deliver real time voice at scale.
We handle the heavy lifting of the network so you can focus on the conversation. Do not let lag destroy your user experience. Build on a foundation of speed.
Want to test our low latency performance yourself? Schedule a demo with our team at FreJun Teler and hear the difference.
Also Read: Virtual Number Call Routing: Handle Calls From Any Location Seamlessly
Frequently Asked Questions (FAQs)
Voice API integration is the process of connecting software applications to telephone networks using code. It allows apps to make calls and manage audio streams programmatically.
The industry standard is below 150 milliseconds for one way delay. Anything above this can cause users to talk over each other.
FreJun Teler uses elastic SIP trunking and direct carrier connections. This avoids the congested public internet routes that typically cause high latency and jitter.
AI agents add processing time. They have to convert speech to text and generate a response and convert text back to speech. This processing time adds to the network latency making low latency infrastructure even more critical.
Jitter is the variation in latency. If some voice packets arrive fast and others arrive slow the audio sounds choppy. A good voice API integration handles jitter to ensure smooth playback.
Yes. Using a modern codec like Opus allows the system to adapt to network conditions reducing packet size to maintain speed even on slow connections.
Yes. You should always use a voice provider that has servers (Points of Presence) close to your users. Connecting a user in Asia to a server in the US will always result in lag.
RTT (Round Trip Time) is the time to go there and back. One way delay is just the time to get there. Usually one way delay is half of the RTT.