
We are at the dawn of a new era in software development: the era of the “AI-first” product. This is a profound shift in how we think about building applications. Instead of adding a layer of AI onto an existing product, we are now building products where the AI is the core product. For an “AI-first” voice product, be it a hyper-realistic conversational agent, a real-time sales coach, or a voice-native productivity tool, the choice of the underlying voice API for developers is not just an implementation detail; it is the single most important architectural decision you will make.
The traditional voice API was built for a different world. It was designed to help a human talk to another human. An ai-first voice api is built on a completely different set of assumptions. It is designed to be the high-performance, low-latency, and deeply programmable “nervous system” for an artificial intelligence.
It is architected not just to connect a call, but to facilitate a real-time, high-throughput data exchange between a human user and an AI “brain.” This guide will explore the essential, non-negotiable characteristics that define a voice API for developers that is truly ready for the AI-first revolution.
Table of contents
The Foundational Shift: From a “Call” to a “Conversational Data Session”
To understand the needs of an AI-first product, we must first recognize that for an AI, a “phone call” is not a phone call. It is a conversational data session. It is a continuous, bidirectional, and incredibly time-sensitive stream of data.
- The “Downlink” Stream: The raw audio from the human user’s voice.
- The “Uplink” Stream: The synthesized audio of the AI’s voice.
The entire “conversation” is a high-speed, computational loop that processes this data. A modern, llm integration voice api must be architected from the ground up to facilitate this loop with maximum speed and flexibility. The quality of this loop is what separates a clunky, robotic experience from a magical, human-like one.
Also Read: Voice Recognition SDK Built For Low Latency Voice Streaming
The Three Pillars of an AI-First Voice API
A voice api for developers that is truly ideal for AI-first products is built on three unshakeable architectural pillars: ultra-low latency, radical flexibility, and deep observability.
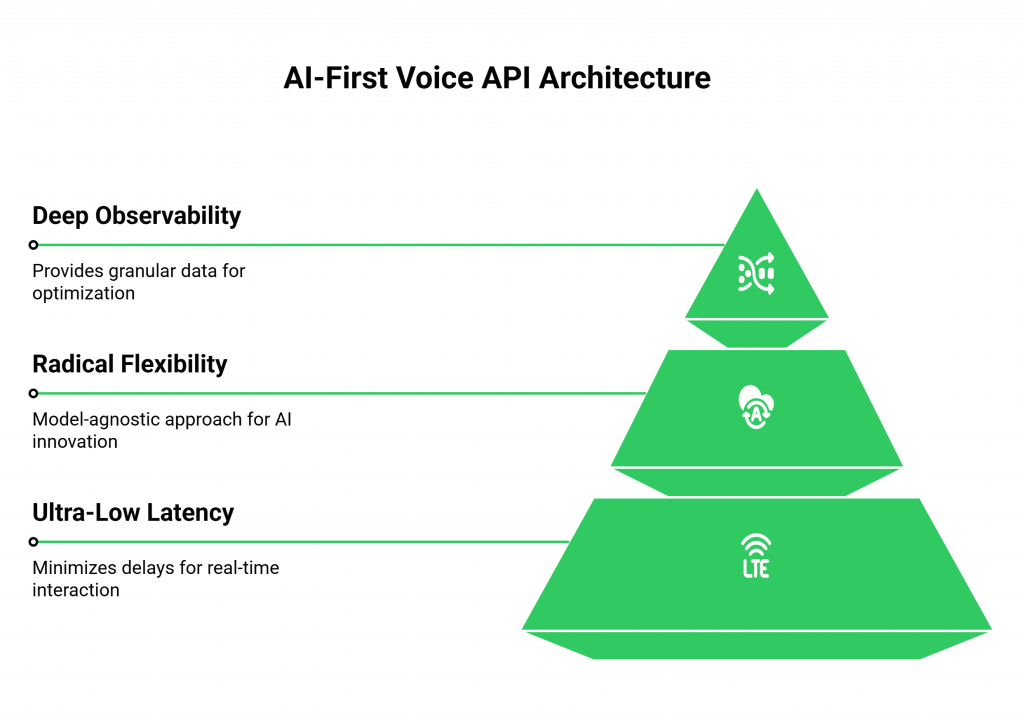
Pillar 1: An Obsessive, Architectural Commitment to Ultra-Low Latency
For an AI conversation, latency is the ultimate enemy. It is the awkward pause that shatters the illusion of real-time interaction. An ai-first voice api must be obsessively engineered to minimize latency at every possible step.
- An Edge-Native, Globally Distributed Architecture: This is the most critical component. The voice platform must have a global network of servers (Points of Presence) that can process the audio at “the edge,” as physically close to the end-user as possible. This is the single most effective way to slash the network latency that is caused by physical distance.
- Real-Time Media Streaming as a Core Primitive: The API must provide a mechanism, like a WebSocket API, for streaming the raw audio to your application the instant it is spoken. The traditional, request-response model of a REST API is far too slow for this task.
- A High-Performance Media Engine: The underlying voice streaming engine must be a highly optimized, carrier-grade piece of software that can process thousands of simultaneous audio streams with minimal processing delay.
Pillar 2: Radical Flexibility Through a Model-Agnostic Philosophy
The world of AI is in a state of explosive, chaotic innovation. The best Speech-to-Text (STT) model for English is different from the best for Spanish. The fastest Large Language Model (LLM) for simple queries is different from the most powerful for complex reasoning. An intelligent voice stack is not a monolith; it is a carefully curated collection of the best-in-class models for a specific job.
- The “Walled Garden” Trap: A voice API that locks you into its own, proprietary AI models is a strategic dead end. It prevents you from using the best tools on the market and puts you at the mercy of a single vendor’s innovation cycle.
- The Power of Being a “Bridge”: A true ai-first voice api, like the one from FreJun AI, is model-agnostic. Our job is not to be the “brain.” Our job is to be the best possible “bridge” between the telephone network and your chosen brain. We provide the high-performance audio stream, and you have the complete freedom to pipe it to any STT, LLM, or TTS provider in the world. This is our core promise: “We handle the complex voice infrastructure so you can focus on building your AI.”
Pillar 3: Deep, Granular Observability
You cannot optimize what you cannot measure. A complex, real-time system like a voice AI agent is a “black box” without deep, granular observability.
- Beyond Simple Call Logs: An intelligent voice stack requires more than just a Call Detail Record (CDR). The API must provide a rich stream of real-time events and post-call analytics that give you a complete, end-to-end picture of the entire conversational data session.
- The Data You Need: This includes:
- Detailed, sub-second timestamps for every event in the call.
- Granular, real-time quality metrics for the audio stream (jitter, packet loss, MOS).
- The ability to easily capture full, dual-channel call recordings for analysis and model training.
This deep observability is the key to troubleshooting voice integrations and to the continuous, data-driven optimization of your AI’s performance.
Also Read: What Should You Look For In A Scalable Voice Recognition SDK?
This table provides a clear summary of what to look for in a modern voice API.
| Characteristic | The Traditional Voice API | The AI-First Voice API |
| Core Architecture | Centralized; designed for human-to-human calls. | Globally distributed and edge-native; designed for human-to-machine data sessions. |
| AI Model Integration | Often a closed, proprietary “walled garden.” | Radically model-agnostic; a flexible bridge to any AI provider. |
| Primary Media Interface | High-level commands (e.g., “play audio file”). | A low-level, real-time audio streaming API (e.g., WebSockets). |
| Key Performance Metric | Call uptime and basic audio clarity. | End-to-end, “glass-to-glass” latency in milliseconds. |
| Developer’s Role | To integrate a pre-built communication feature. | To architect a real-time, conversational data processing pipeline. |
Ready to build your AI-first product on a platform that was architected for this new era? Sign up for FreJun AI
How This Architecture Enables the Next Generation of Voice AI
This architectural philosophy is not just a technical preference; it is what enables the next wave of innovation in voice AI. The future of voice AI is not just about having a single, monolithic agent; it is about creating a dynamic and intelligent system.
The Hybrid AI Brain
A model-agnostic LLM integration voice API allows for a sophisticated, hybrid AI architecture.
- The Workflow: You can use a very fast, lightweight “router” model to handle the first few turns of a conversation with ultra-low latency. If the conversation becomes more complex, this router can then seamlessly hand off the context to a larger, more powerful, but slightly slower LLM in the cloud to handle the “heavy thinking.”
- The Benefit: This gives you the best of both worlds: the instantaneous feel of an edge-based model for most of the conversation, and the deep intelligence of a cloud-based model for the most critical moments.
A Foundation for Multi-Modal Experiences
The next gen voice platform is not just about voice. A flexible, API-driven architecture is the foundation for building multi-modal experiences that can seamlessly blend a voice call with other channels, like video, text chat, or real-time data sharing. The API acts as the unified session manager for this entire, rich interaction.
Also Read: How Can a Voice Recognition SDK Enhance Real Time Call Accuracy
Conclusion
The rise of the AI-first product is a seismic shift in software development. For a voice application, this shift places a new and profound set of demands on the underlying communication infrastructure. The voice API for developers is no longer a simple utility; it is a mission-critical, high-performance component of the AI stack.
The ideal ai-first voice API is one that is architected from its very foundation for the demands of this new world. It is a platform that is obsessively focused on low latency, radically flexible and model-agnostic, and deeply observable.
By choosing a provider that embodies these core principles, developers are not just selecting a tool; they are choosing an architectural partner that will empower them to build the truly intelligent, conversational, and human-like voice experiences of the future.
Want to do a deep architectural dive into how our platform can provide the low-latency, model-agnostic foundation for your AI-first product? Schedule a demo for FreJun Teler.
Also Read: 7 Best IVR Software for Small Businesses: Affordable & Scalable Options
Frequently Asked Questions (FAQs)
An “AI-first” voice product is an application where the core functionality and user experience are deliver by an intelligent, conversational AI, not just augmented by it.
The most important feature is an architectural commitment to ultra-low latency, which is essential for a natural-sounding, real-time AI conversation.
An LLM integration voice API specifically simplifies connecting a large language model to a live phone call.
An intelligent voice stack includes all technologies required to build voice AI, including the voice API, STT, LLM, and TTS models.
It is important because it provides the freedom to choose the best-in-class AI models from any provider, preventing vendor lock-in and allowing for greater innovation.
An edge-native architecture processes the call at a data center that is physically closer to the end-user, which dramatically reduces the network travel time for the audio data.
It is an architectural pattern for hybrid AI processing. A fast, lightweight model handles simple conversation turns at the edge. More complex queries are handed off to a larger cloud-based AI model.