
As a developer building a voice application, you live in a world of clean, structured data. You work with JSON payloads, RESTful endpoints, and logical, predictable request-response cycles. However the moment your application needs to listen to a live phone call, instead you are plunged into a different universe: consequently the chaotic, unpredictable, and time-sensitive world of real-time audio.
A live human voice is not a neat JSON object; it is a continuous, analog stream of data packets that must be captured, transported, and processed in a fraction of a second. The old tools of the web are simply not built for this task. This is the fundamental challenge that a modern voice API for developers, equipped with a real time audio streaming api, is designed to solve.
The future of voice AI and interactive communication hinges on the ability to close the gap between the chaotic world of live audio and the structured world of your application’s logic. This requires a specialized bridge, a high-speed data tunnel that can carry the voice stream with minimal delay.
The technology that provides this bridge is the WebSocket. Understanding how a websocket voice API works is the key for any developer looking to move beyond simple, pre-recorded call flows and build truly dynamic, conversational, and low-latency voice applications.
Table of contents
Why is Real-Time Audio Streaming a “Hard Problem” in Telephony?
To appreciate the elegance of the solution, we must first respect the profound difficulty of the problem. A phone call is not a file that you can download. It is a live, ephemeral event.
The Nature of Real-Time Audio
The audio of a phone call is transported over the internet using a protocol called RTP (Real-time Transport Protocol). An RTP stream is a continuous flow of tiny data packets, each containing a few milliseconds of sound. This stream has several characteristics that make it incredibly challenging to work with directly:
- It is Unpredictable: The packets do not always arrive in perfect order or at a perfectly consistent pace (a phenomenon known as “jitter”). Some packets may get lost entirely (“packet loss”).
- It is Low-Level: Working with raw RTP streams requires deep expertise in network engineering and telecommunications protocols. It is not something a typical application developer is equipped to, or should have to, handle.
- It is Time-Sensitive: The entire stream is useless if it is not processed in real-time. A delay of even one second makes a conversation impossible.
The Demands of an AI Conversation
This challenge is magnified tenfold in an AI-powered conversation. For an AI to have a natural dialogue, a high-speed, multi-step data relay must occur in a fraction of a second:
- The live audio must be captured.
- It must be streamed to a Speech-to-Text (STT) engine.
- The resulting text must be sent to a Large Language Model (LLM).
- The LLM’s text response must be sent to a Text-to-Speech (TTS) engine.
- The synthesized audio must be streamed back to the caller.
This entire loop needs to happen with minimal delay. Any latency in the initial audio stream will have a cascading effect, dooming the conversation to feel slow and robotic. This is why a high-performance real time audio streaming api is the non-negotiable foundation for any low latency voice streaming 2026 application.
Also Read: Why Choose a Voice API for Bulk Calling with Real-Time Control?
How Does a Modern Voice API Solve This with WebSockets?
The traditional, request-response model of a REST API is completely unsuitable for streaming live audio. You cannot make a new HTTP request for every 20-millisecond chunk of sound. The solution is to use a different protocol, one that is purpose-built for persistent, real-time, two-way communication: the WebSocket.
What is the Role of a Websocket Voice API?
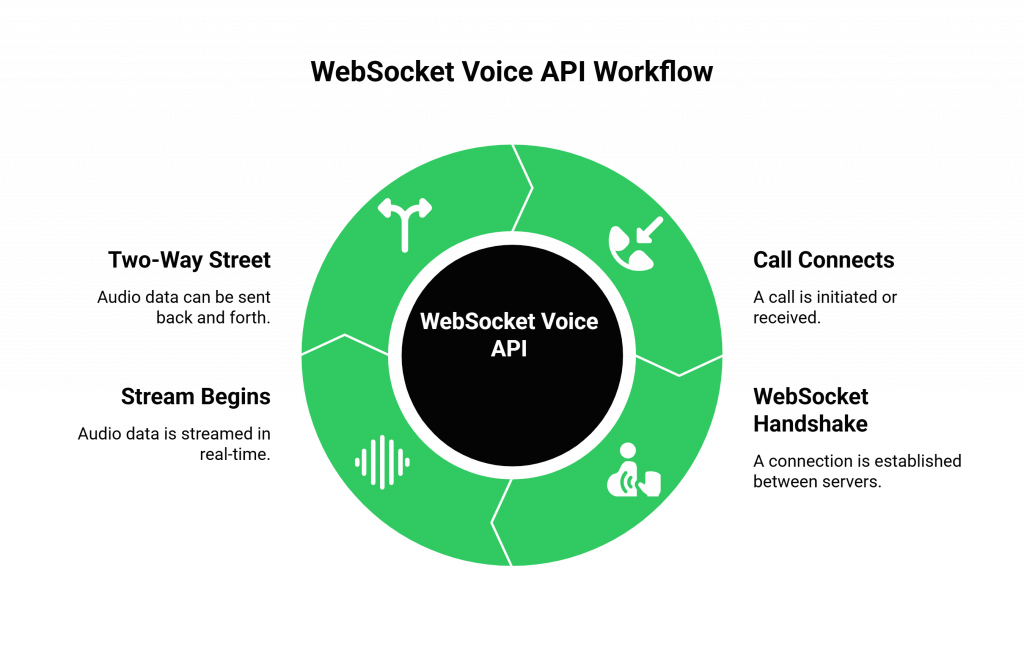
A websocket voice API is a feature of a modern voice API for developers that allows you to establish a direct, persistent, and bidirectional “tunnel” between the voice platform’s media server and your own application server. Instead of just “terminating” a call, the voice platform becomes a real-time media gateway that you can control. Here is how the workflow typically functions:
- The Call Connects: A call is initiated or received by the voice platform’s core infrastructure (e.g., FreJun AI’s Teler engine).
- The WebSocket Handshake: Your application sends an API command to the platform, instructing it to connect the live audio of that call to a specific WebSocket URL on your server. The voice platform’s media server then initiates a WebSocket handshake with your application server.
- The Stream Begins: Once the platform establishes a persistent WebSocket connection, the media server streams raw audio packets to your application in real time. The server encodes the audio, often in Base64, and sends it as sequential WebSocket messages.
- A Two-Way Street: This is the beautiful part. Because a WebSocket is bidirectional, your application can also send audio data back up the same connection. This is how you can inject your AI’s synthesized speech back into the live call.
What Are the Architectural Benefits of a WebSocket-Based Approach?
Choosing a websocket voice api over other potential methods is a critical architectural decision that provides several profound advantages for building high-performance voice applications.
The Triumph Over Latency
WebSockets are inherently faster and more efficient for real-time data than any HTTP-based method.
- No Connection Overhead: A WebSocket connection is established once. After that, data can flow freely in either direction with very little overhead. An HTTP-based approach would require the overhead of establishing a new TCP and TLS connection for every single chunk of data, adding significant latency.
- Full-Duplex Communication: Data can be sent and received at the same time, which is essential for a natural conversation.
Enabling True Interactivity (Barge-In)
The bidirectional nature of WebSockets is the key to enabling one of the most important features for a natural-sounding AI: barge-in.
- As your application is sending audio data up the WebSocket for your AI to speak, it can simultaneously be receiving audio data down the WebSocket from the user who has started to speak.
- Your application can detect this incoming audio and immediately stop sending its own audio, allowing the user to interrupt the AI. This is a level of real-time interactivity that is impossible with a simple request-response model.
Also Read: Faster Engagement Through Next-Gen Voice API for Bulk Calling Tools
This table provides a clear comparison of the architectural approaches.
| Characteristic | Hypothetical HTTP Polling for Audio | Real-Time Websocket Voice API |
| Connection Model | Stateless, request-response. A new connection for every piece of data. | Stateful, persistent. A single connection for the entire session. |
| Data Flow | Half-duplex (you can either send or receive, not both at once). | Full-duplex (you can send and receive data simultaneously). |
| Latency | High, due to repeated connection setup and header overhead. | Ultra-low, with minimal overhead after the initial handshake. |
| Server Load | High, as the server has to handle a constant stream of new requests. | Low, as it maintains a single, efficient connection. |
| Use Case Suitability | Unsuitable for real-time voice. Good for simple commands. | Perfectly suited for real time audio streaming api and conversational AI. |
Ready to harness the power of real-time streaming for your own voice applications? Sign up for FreJun AI
How Does This Fit into the Broader FreJun AI Architecture?
This WebSocket-based approach is a core component of the FreJun AI platform, designed to give developers the ultimate power and flexibility. The voice api for developers is the toolkit that lets you orchestrate this complex dance.
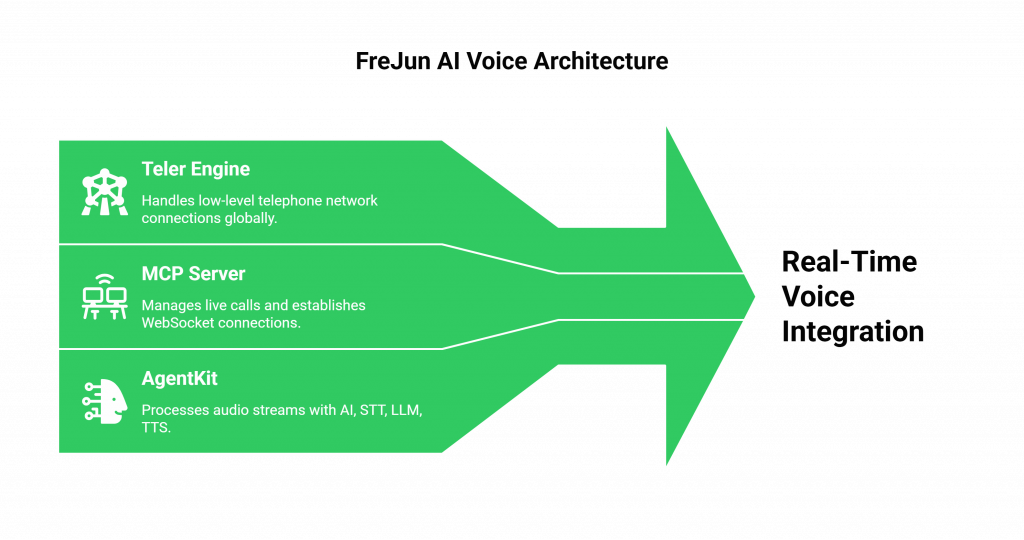
- Teler, the Foundation: Our globally distributed Teler engine handles the initial, low-level connection to the telephone network at the edge, as close to the user as possible.
- The MCP Server, the Conductor: Our Media Control Plane (MCP) server is the brain that manages the live call. It is the component that you instruct, via our API, to establish the WebSocket connection to your application.
- Your AgentKit, the Intelligence: Your application (your “AgentKit”) receives the WebSocket stream. This is where your AI’s intelligence, your STT, LLM, and TTS models lives.
This decoupled architecture is designed for maximum performance and flexibility. We handle the incredibly complex, carrier-grade voice infrastructure, and you get a simple, powerful, and real-time stream of audio to work with. The power of this API-driven model is reflected in the growth of the API economy itself.
One market analysis projects that the global API management market will reach over $13 billion by 2027, a clear sign that developers are increasingly relying on specialized APIs to build their applications.
Also Read: How Voice API for Bulk Calling Improves OTP & Verification Flows
Conclusion
The ability to process live, real-time audio therefore represents the final frontier that separates a simple, command-based voice application from a truly intelligent, conversational one. Moreover, the raw and unpredictable nature of a phone call’s audio stream introduces a formidable technical challenge; however, modern voice APIs for developers have now solved this challenge elegantly.
By leveraging the power of a websocket voice API, developers can now establish a high-speed, low-latency, and fully bidirectional data tunnel directly into the heart of a live conversation.
Therefore, this audio streaming API goes beyond a feature; instead, it enables low-latency voice AI as its nervous system.
Want a technical deep dive into our WebSocket API and to see a live demonstration of real-time audio streaming in action? Schedule a demo for FreJun Teler.
Also Read: IVR Software for Healthcare: Appointment Booking & Patient Routing
Frequently Asked Questions (FAQs)
Its main purpose is to provide a developer’s application with a live, low-latency audio feed from a phone call, which is essential for AI transcription.
A WebSocket creates a persistent, two-way data tunnel between servers, enabling a constant, bidirectional stream of information without the overhead of repeated connections.
WebSockets are better for voice because they are persistent and bidirectional, which is perfect for streaming audio with ultra-low latency. REST APIs are too slow.
RTP is the low-level internet protocol used to transport real-time data like voice and video. A voice API abstracts this complexity away from the developer.
Because a WebSocket is bidirectional, your application can receive the user’s audio (they are interrupting) at the same time it is sending the AI’s audio.
This refers to the ongoing trend and future expectation for voice AI conversations to have an imperceptibly small delay, making them feel completely natural and human-like.
Yes. The voice platform typically sends the audio in a specific format (like PCMU/G.711) and encoding (like Base64) that your application needs to be able to handle.