
In the sprawling ecosystem of the modern digital landscape, the user journey is no longer confined to a single screen or a single device. A customer might start an interaction on their laptop at work, continue it on their smartphone during their commute, and finish it through a smart speaker at home. For businesses building on this landscape, the challenge is immense: how do you provide a consistent, seamless, and intelligent experience across this fragmented, multi-device world?
For a rapidly growing number of applications, the answer is voice. But not just any voice technology. It requires a new breed of voice recognition SDK, one that is architected from the ground up for the realities of omnichannel and cross-device interaction.
The traditional approach to voice recognition was born in a simpler time, a time of dedicated call centers and desktop applications. It was not designed for the fluid, on-the-go nature of a modern digital platform.
A digital platform STT (Speech-to-Text) solution cannot be a siloed feature; it must be a deeply integrated, context-aware, and incredibly flexible component of the platform’s core architecture. This guide will explore the essential characteristics of a voice recognition SDK that is truly built for the demands of the modern, omnichannel digital world.
Table of contents
The Problem: The Disconnected, Device-Specific Voice Experience
Many platforms today have “voice features,” but very few have a true “voice strategy.” The result is a collection of disconnected, siloed experiences that frustrate users and fail to deliver on the true promise of voice.
The Silo of the Single Channel
This is the most common failure mode. A company might have a fantastic voice-powered IVR for their phone line, but that system has absolutely no connection to the voice assistant in their mobile app.
- The User’s Frustration: A user has a long, detailed conversation with the phone agent, only to open the mobile app and find that the app has no memory of that interaction. They have to start their journey all over again. This is a direct consequence of not having an omnichannel voice SDK.
- The Business’s Inefficiency: The company is forced to build, manage, and maintain two completely separate voice technology stacks, doubling the cost and the engineering effort.
The Challenge of Cross-Device Speech
The physical and acoustic environment of a user changes dramatically as they move between devices.
- Acoustic Diversity: The audio captured from a high-quality headset on a desktop computer in a quiet office is pristine. The audio from a smartphone’s built-in microphone on a noisy street is a chaotic mess of background noise.
- The Accuracy Problem: A standard, one-size-fits-all voice recognition model will perform very differently in these two scenarios. If the SDK is not intelligent enough to adapt, the accuracy of the cross-device speech recognition will be inconsistent and unreliable, leading to a poor user experience.
Also Read: Key Benefits of Programmable SIP for Building Context-Aware Voice Applications
What Defines a Voice Recognition SDK for the Modern Digital Platform?
A voice recognition SDK that is truly built for the omnichannel world is not just an API for transcription; it is a comprehensive toolkit for building a unified, context-aware, and high-performance voice experience across every user touchpoint.
A Unified, API-First Architecture
The foundation of an omnichannel voice SDK is a unified, API-first architecture. This means there is a single, centralized “brain” (your application’s backend) that manages the state of every user’s conversation, regardless of the channel.
- The “Brain” and the “Senses”: Your backend is the brain. The SDK, deployed on your website, in your mobile app, and connected to your phone line, acts as the different “senses” (the ears and mouth) for that brain.
- The Power of a Unified State: This architecture is what allows for a seamless, cross-device journey. When a user has a conversation through the SDK on their phone, the state of that conversation is updated in the central brain. When they later log in on their laptop, the SDK on the web can query that same brain and pick up the conversation exactly where it left off.
Advanced, Adaptive Audio Processing
To solve the challenge of cross-device speech, the SDK must be more than just a simple audio pipe. It needs to be an intelligent audio pre-processor.
- Client-Side Intelligence: An advanced voice recognition SDK will have powerful, client-side features that run on the user’s device. This can include AI-powered noise suppression, echo cancellation, and automatic gain control. This ensures that the audio stream sent from the device to the STT engine is as clean and clear as possible, regardless of the user’s environment.
- Model Agnosticism: The platform should be model-agnostic, allowing you to route the audio from different devices or environments to different, specialized STT models. For example, you could route the audio from a car’s infotainment system to an STT model that is specifically trained to handle in-vehicle noise. The importance of this is growing; a recent report on the connected car market shows that voice assistants are now a standard feature in over 90% of new cars.
Also Read: Why Programmable SIP Is the Backbone of Voice Infrastructure for AI Agents
This table highlights the key differences between a traditional and a modern, platform-oriented SDK.
| Feature | Traditional, Siloed SDK | Modern, Omnichannel Voice SDK |
| Architecture | Channel-specific; a separate stack for each channel. | Unified and API-first; a single backend “brain” for all channels. |
| State Management | State is trapped within the single channel. | State is centralized, enabling a seamless cross-device journey. |
| Audio Processing | Basic audio capture. | Advanced, client-side audio pre-processing (e.g., noise suppression). |
| STT Integration | Typically locked into a single, general-purpose STT model. | Model-agnostic, allowing for the use of specialized models for different contexts. |
| Developer Experience | Requires learning and maintaining multiple, different SDKs. | A single, consistent SDK and API for all voice touchpoints. |
Ready to build a unified voice experience that follows your customers wherever they go? Sign up for FreJun AI
What is FreJun AI’s Role in Building This Unified Experience?
At FreJun AI, we have built our entire platform to be the foundational, omnichannel communication layer for the modern digital enterprise. Our voice recognition SDK is the developer’s toolkit for accessing this powerful infrastructure.
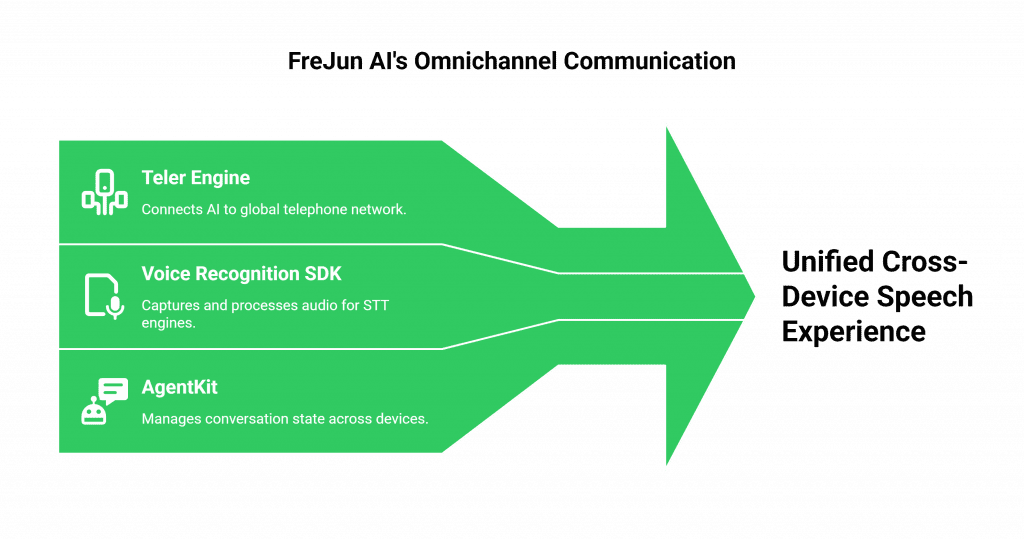
The Universal Bridge for Voice
FreJun AI is not an STT provider. We are the universal bridge that can connect any of your digital endpoints to any STT engine you choose.
- For Your Phone Channel: Our Teler engine is the powerful, globally distributed voice network that connects your central AI brain to the global telephone network.
- For Your Digital Channels: Our voice recognition SDK for web and mobile provides the tools to capture the user’s microphone audio, pre-process it for clarity, and stream it in real-time to your chosen STT engine.
Because both the phone channel and the digital channels are powered by the same underlying, API-driven platform, creating a unified, cross-device speech experience is not just possible; it is simple. Your central application logic (your AgentKit) can manage the state of a conversation that starts on a phone call and seamlessly continues inside your mobile app.
Also Read: The Developer’s Guide to Integrating LLMs with Programmable SIP Infrastructure
Conclusion
The future of digital interaction is a fluid, conversational, and omnichannel one. Voice is no longer a feature that can be bolted onto a single channel; it must be a cohesive and intelligent thread that is woven through the entire user journey.
A traditional, siloed voice recognition SDK cannot support this new reality. Modern digital platforms need a different STT approach. They require a unified, API-first SDK architecture. The SDK must handle cross-device speech intelligently. It must also integrate flexibly with diverse AI model ecosystems.
By building on this kind of omnichannel voice SDK, businesses can finally deliver on the promise of a truly seamless, context-aware, and exceptional voice experience for their customers, no matter where or how they choose to connect.
Want to do a deep dive into the architecture of our cross-platform SDK and see how it can unify the voice experience across your web, mobile, and phone channels? Schedule a demo for FreJun Teler.
Also Read: 10 Best Business Phone Systems: Features, Pricing & Comparison
Frequently Asked Questions (FAQs)
An omnichannel voice SDK gives developers tools for consistent voice experiences. It works across phone lines, websites, and mobile apps. It connects all channels through a unified backend architecture.
The main problem is the start-over experience. A customer begins on one channel, such as a phone call. They then switch to another channel, like a mobile app. The system loses conversation memory. This forces the customer to repeat information.
A modern SDK for cross-device speech uses advanced, client-side audio processing. It can perform tasks like noise suppression and echo cancellation on the user’s device before the audio is sent for recognition.
A digital platform STT (Speech-to-Text) is not a specific product, but a strategy. It refers to a voice recognition solution that is deeply and seamlessly integrated across all of a company’s digital platforms.
A unified architecture uses a single, centralized backend “brain” to manage the conversational state for a user. This means that the memory of a conversation on one channel is instantly available on all other channels.
It means the SDK is not locked to one proprietary STT engine. The SDK provides a clean, processed audio stream. Developers can route this stream to any STT provider.
FreJun AI delivers a unified, API-first voice infrastructure. Our voice recognition SDK supports web and mobile. Our Teler engine powers the phone channel. Both connect to the same central application backend.