
Building voice bots used to require large teams, complex infrastructure, and long integration cycles. However, that reality has changed. Today, small teams can build reliable, real-time voice bots using modular AI components and cloud-based voice infrastructure. The challenge is no longer whether voice bots are possible, but how to build them efficiently without increasing cost or complexity.
This guide breaks down the technical building blocks behind modern voice bots and explains how founders, product managers, and engineering leads can design cost-effective systems. By focusing on architecture, component choices, and infrastructure boundaries, small teams can move from idea to production voice bots faster and with predictable costs.
Why Are More Small Teams Building Voice Bots Today?
For a long time, voice automation was expensive, slow, and rigid. Traditional IVRs required hardware, long setup cycles, and vendor contracts. As a result, small teams avoided voice entirely.
However, over the last few years, several changes have reshaped this space.
First, cloud-native AI services removed the need for on-premise systems. Second, LLMs made conversational logic easier to build and maintain. Finally, streaming speech APIs reduced latency, making voice interactions feel more natural.
Because of these shifts, building voice bots is now closer to building a web service than deploying telecom infrastructure.
Despite huge call volumes worldwide, only about 6% of interactions are fully automated by AI voice agents today, indicating significant room for innovation and cost-efficient adoption by small teams.
More importantly, small teams are choosing voice bots for practical reasons:
- Support teams want to reduce call volume
- Sales teams want automated qualification
- Ops teams want reminders and confirmations
- Founders want faster experiments without large upfront spend
As a result, low-cost voice bot development has become a realistic goal, not a compromise.
What Exactly Is A Voice Bot From A Technical Perspective?
Before discussing costs, it is important to understand what a voice bot really is. Many teams underestimate this, which later leads to wrong architectural decisions.
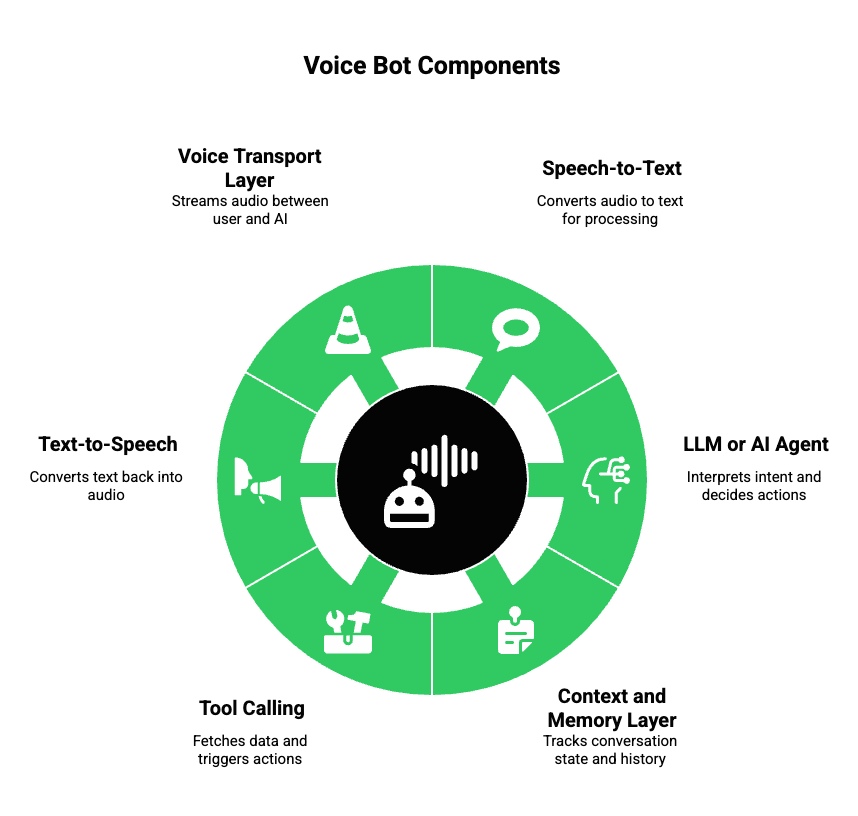
A modern voice bot is not a single tool. Instead, it is a system composed of multiple independent components working together in real time.
At a high level, a voice bot includes:
- Speech-to-Text (STT): Converts live audio into text
- LLM Or AI Agent: Interprets intent and decides what to say or do next
- Context And Memory Layer: Tracks conversation state and user history
- Tool Calling Or Business Logic: Fetches data, triggers actions, or updates systems
- Text-to-Speech (TTS): Converts responses back into audio
- Voice Transport Layer: Streams audio between the user and the AI system
Because all of these components are loosely coupled, teams can swap providers without rewriting the entire system. This flexibility is the foundation of building voice bots without infrastructure-heavy commitments.
Where Do Voice Bot Costs Usually Come From?
Even though APIs are easier to use today, costs can still add up quickly if teams are not careful. Therefore, understanding cost sources early is critical.
Most voice bot expenses fall into five categories:
- Voice Streaming And Telephony
- Inbound and outbound calls
- Media streaming
- Network reliability
- Inbound and outbound calls
- Speech-to-Text Usage
- Charged per second or per minute
- Streaming STT often costs more than batch
- Charged per second or per minute
- Text-to-Speech Generation
- Charged per character or per second
- Voice quality impacts price
- Charged per character or per second
- LLM Tokens
- Prompt size
- Response length
- Context history
- Prompt size
- Infrastructure And Maintenance
- Media servers
- Scaling logic
- Monitoring and retries
- Media servers
However, many teams overspend not because of usage, but because of bundled platforms. Platforms whose core offering is calling often bundle AI features, forcing teams to pay for logic they already control elsewhere.
Therefore, separating AI logic from voice infrastructure is one of the most effective ways to reduce long-term costs.
How Can Small Teams Build Voice Bots Without Owning Infrastructure?
At this point, one thing becomes clear: owning telephony infrastructure is expensive and unnecessary for most teams.
Traditionally, building voice bots required:
- SIP servers
- Media gateways
- Call routing logic
- Failover systems
However, modern architectures remove this burden by introducing a voice transport layer. This layer handles real-time audio streaming while letting your application manage intelligence.
As a result, teams no longer need to manage:
- Audio buffers
- Network jitter
- Call lifecycle events
- Regional telephony differences
Instead, teams focus on AI behavior and business logic.
This approach allows small teams to build voice bots without infrastructure while still maintaining full control over:
- Dialogue flow
- Context handling
- Tool execution
- AI provider choice
Which Free Or Low-Cost STT And TTS Options Can Teams Start With?
One of the biggest concerns for teams is speech processing cost. Fortunately, there are several budget-friendly AI tools available today.
Free Or Low-Cost STT Options
Teams can start with:
- Open-source speech models
- Freemium cloud STT APIs
- Usage-limited developer tiers
These options are often sufficient for early prototypes and MVPs. However, accuracy is not the only factor to consider.
Streaming support matters because voice bots require partial transcripts, not delayed responses.
Free Or Low-Cost TTS Options
Similarly, TTS engines now offer:
- Basic voices at low cost
- Character-based pricing
- Open-source synthesis models
While premium voices sound better, early-stage voice bots can function well with simpler outputs, especially for internal or operational use cases.
| Component | Early-Stage Priority | Cost Impact |
| STT | Low latency | Medium |
| TTS | Streaming support | Low |
| Voice quality | Acceptable clarity | Low |
Because of this, teams should prioritize latency and stability over premium quality during early development.
How Do LLMs Power Voice Bots Without Increasing Costs Too Fast?
LLMs are often seen as the most expensive part of voice bots. However, this only happens when they are used inefficiently.
Smart teams control LLM costs by:
- Keeping prompts short
- Limiting conversation history
- Using intent detection before full generation
- Routing simple tasks to tools instead of free text
Additionally, voice bots do not need long-form responses. In fact, shorter responses improve call flow and reduce latency.
Instead of asking the LLM to “think aloud,” teams should:
- Use structured outputs
- Define clear system roles
- Separate decision-making from phrasing
As a result, LLM usage becomes predictable and budget-friendly, even at scale.
How Do All These Components Talk To Each Other In Real Time?
Now that we understand the pieces, it is important to see how they connect.
A real-time voice bot follows this flow:
- User speaks into a call
- Audio is streamed to STT
- Partial transcripts are generated
- LLM processes intent
- Tools are called if needed
- Response text is generated
- TTS converts text to audio
- Audio is streamed back to the user
Each step introduces latency. Therefore, even small delays can compound.
This is why polling-based or request-response systems fail for voice bots. Instead, streaming pipelines are required to maintain conversational flow.
At this stage, it becomes clear that voice bots are timing-sensitive systems, not simple chat applications.
How Does FreJun Teler Fit Into A Low-Cost Voice Bot Stack?
At this point in the architecture, one missing piece becomes clear: the voice transport layer. This is where FreJun Teler fits, and it fits only here.
FreJun Teler is not an AI platform and not a calling product. Instead, it acts as global voice infrastructure for AI agents and LLMs. Its role is narrow, but critical.
FreJun Teler handles:
- Real-time audio streaming from live calls
- Low-latency media transport
- Call lifecycle management
- Reliable audio delivery back to the user
At the same time, it does not interfere with:
- Your LLM choice
- Your STT or TTS provider
- Your prompt logic
- Your context or memory handling
This separation is important. Because Teler focuses only on the voice layer, small teams avoid paying for bundled AI logic or locked-in workflows.
From a cost perspective, this means:
- No need to manage SIP servers
- No need to build media pipelines
- No need to solve telephony reliability issues
- No forced AI usage pricing
As a result, teams can scale voice bots without infrastructure overhead while keeping full ownership of intelligence.
What Does A Minimal-Cost Voice Bot Architecture Look Like?
With the roles clearly defined, we can now describe a clean, budget-friendly architecture.
A minimal production-ready stack looks like this:
- Voice Layer: FreJun Teler
- STT: Streaming STT (open-source or freemium)
- LLM: Any hosted or self-managed model
- Context Layer: Lightweight state store
- Tools: APIs, databases, or internal services
- TTS: Streaming TTS engine
Importantly, each component can be replaced independently.
Why This Architecture Keeps Costs Low
First, voice streaming is handled externally, so there is no media server cost.
Second, AI usage is modular, so teams pay only for what they use.
Finally, scaling happens per component, not as a bundled system.
| Layer | Cost Control Mechanism |
| Voice | Usage-based streaming |
| STT | Swap providers as volume grows |
| LLM | Token limits and routing |
| TTS | Voice quality by use case |
| Tools | Execute only when needed |
Because of this, teams can start small and improve components gradually instead of overpaying upfront.
How Can Teams Start With A Small MVP And Scale Later?
One common mistake is trying to build a “complete” voice bot on day one. Instead, successful teams start with a narrow use case.
For example:
- Appointment confirmations
- Lead qualification
- Internal support routing
These use cases share three advantages:
- Short conversations
- Clear intent paths
- Limited context needs
As a result, they keep STT, LLM, and TTS usage low while validating real-world value.
Once the MVP is stable, teams can:
- Add better voices
- Improve intent handling
- Introduce RAG for knowledge access
- Expand to new call flows
Because the architecture is modular, these improvements do not require rework.
How Can Small Teams Optimize Voice Bot Costs As Usage Grows?
As usage increases, cost optimization becomes more important. Fortunately, voice bots offer many optimization points.
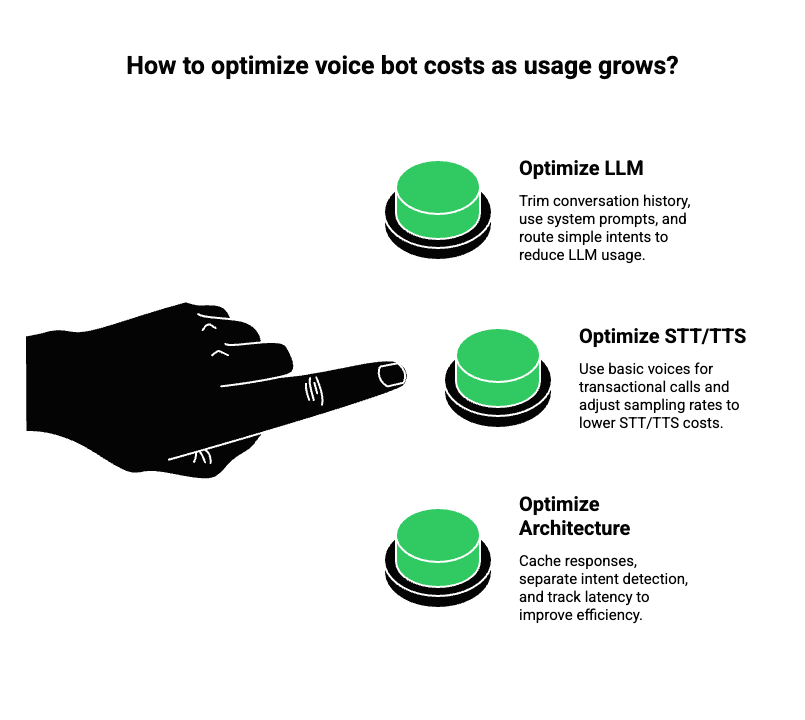
Optimize At The LLM Level
- Trim conversation history aggressively
- Use system prompts instead of long examples
- Route simple intents away from the LLM
Optimize At The STT And TTS Level
- Use basic voices for transactional calls
- Switch to higher-quality voices only where needed
- Adjust sampling rates carefully
Optimize At The Architecture Level
- Cache frequent responses
- Separate intent detection from response generation
- Track latency alongside cost
Because each component is isolated, optimization does not disrupt the entire system.
How Does Cost Optimization Change With Scale?
Early-stage cost control focuses on avoiding waste. Later-stage cost control focuses on efficiency.
At low scale:
- Use freemium tiers
- Avoid premium voices
- Keep logic simple
At higher scale:
- Negotiate usage-based pricing
- Introduce hybrid STT or TTS setups
- Fine-tune prompts for shorter outputs
This phased approach allows teams to grow without sudden cost spikes.
What Are Common Mistakes Small Teams Should Avoid?
Even with good tools, teams can make decisions that increase cost and complexity.
Some common mistakes include:
- Treating voice bots like chatbots
- Choosing platforms that bundle AI logic
- Ignoring streaming latency requirements
- Overengineering conversation memory
- Locking into proprietary voice workflows
Each of these mistakes leads to higher cost, slower iteration, or both.
Therefore, simplicity is not a limitation. Instead, it is a strategy.
How Quickly Can A Small Team Launch A Voice Bot Today?
With the right architecture, timelines are shorter than most teams expect.
A realistic breakdown looks like this:
- Prototype: 2–5 days
- MVP: 1–2 weeks
- Production-ready: 3–4 weeks
This includes real phone calls, real users, and real AI responses.
Because infrastructure is abstracted and AI logic is modular, teams spend time on behavior, not plumbing.
Why Voice Bots Are Now A Product Decision, Not An Infrastructure Project
In the past, voice automation required long-term commitments and heavy upfront investment. Today, the situation is different.
Because teams can now:
- Build voice bots without infrastructure
- Use budget-friendly AI tools
- Control costs at every layer
- Scale incrementally
Voice bots have become a product-level choice.
This shift is important. It means founders, product managers, and engineering leads can experiment, learn, and iterate without betting the company on day one.
Final Thoughts
Building voice bots at minimal cost is not about cutting features or compromising quality. Instead, it is about making disciplined architectural choices. When teams separate voice infrastructure from AI logic, they gain flexibility, control, and cost efficiency. Modern voice bots are composed systems—LLMs, STT, TTS, context, and tools, connected through a reliable real-time voice layer.
FreJun Teler fits this model by providing global, low-latency voice infrastructure purpose-built for AI agents. It allows teams to focus on building intelligence while offloading the complexity of real-time voice streaming and telephony reliability.
If you are planning to launch or scale AI voice bots without infrastructure overhead, FreJun Teler helps you move faster with confidence.
Schedule a demo.
FAQs (User-Focused, Practical, 20-Word Answers Each)
1. Can small teams really build voice bots without telephony infrastructure?
Yes, modern voice APIs handle media streaming, allowing teams to focus on AI logic instead of telecom complexity.
2. What is the minimum stack required to build a voice bot?
A voice layer, STT, LLM, TTS, and basic backend logic are enough to launch a functional voice bot.
3. Are voice bots expensive to run at scale?
They can be cost-efficient if AI usage, streaming, and infrastructure are separated and optimized independently.
4. Do voice bots require high-quality voices to work well?
No, early versions work well with basic voices; quality upgrades can be added after validation.
5. How important is real-time streaming for voice bots?
It is critical. Streaming prevents delays and maintains conversational flow during live phone interactions.
6. Can teams switch STT or TTS providers later?
Yes, modular architectures allow provider changes without rewriting the entire system.
7. How much development time is needed for a voice bot MVP?
Most teams can build a working MVP within one to two weeks using modern voice infrastructure.
8. Are voice bots suitable for outbound calling use cases?
Yes, they are widely used for reminders, qualification, confirmations, and feedback collection.
9. How do teams control LLM costs in voice bots?
By limiting prompt size, managing context, and routing simple tasks through tools instead of free-text generation.
10. Is voice bot adoption growing among businesses?
Yes, AI-driven voice automation is rapidly expanding across support, sales, and operational workflows.