
Building voice bots is no longer about making AI speak. It is about delivering conversations that feel natural, responsive, and reliable over real phone calls. For founders, product managers, and engineering leads, this creates a new challenge: how do you measure quality when interactions happen in real time, over audio, across unpredictable user behavior?
Quality assurance for voice bots goes beyond testing responses. It requires evaluating timing, audio clarity, turn-taking, and system reliability together.
This guide breaks down how QA teams should evaluate voice interactions step by step, focusing on real-world scenarios, technical metrics, and production readiness – so teams can ship voice bots users actually trust.
Why Is QA Critical When Building Voice Bots For Real Users?
Voice bots are no longer experimental systems. Today, they answer customer calls, qualify leads, handle support tickets, and trigger business workflows. As a result, quality assurance is no longer about catching small bugs. Instead, QA determines whether users trust the system or hang up within seconds.
When teams start building voice bots, they often focus heavily on the AI model. However, voice interactions are more fragile than chat interfaces. A small delay, unclear audio, or broken turn-taking can ruin the experience, even if the AI logic is correct.
Therefore, QA teams must evaluate voice bots differently.
Unlike chatbots, voice bots operate in real time. Audio flows continuously. Users interrupt, hesitate, or change direction mid-sentence. Meanwhile, the system must listen, think, and respond without noticeable delay. Because of this, traditional QA methods are not enough.
Simply put, if QA does not treat voice as a system-level problem, issues will appear in production.
What Exactly Should QA Teams Test In A Voice Bot?
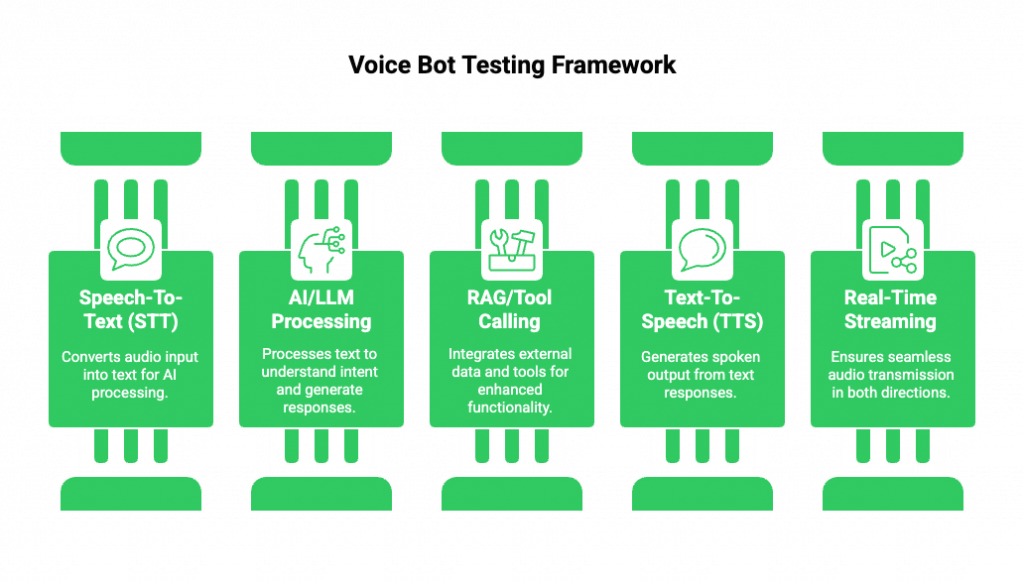
Before defining test cases, QA teams must understand what they are testing. A voice bot is not a single component. Instead, it is a pipeline of systems working together in real time.
At a high level, a typical voice bot includes:
- Speech-To-Text (STT) to convert audio into text
- An AI or LLM to process intent and generate responses
- Optional RAG or tool calling for data access and actions
- Text-To-Speech (TTS) to generate spoken output
- Real-time voice streaming infrastructure to move audio both ways
Because of this structure, QA cannot test each part in isolation alone. While unit tests are useful, most failures happen when components interact.
For example:
- A small STT delay can cause the AI to respond too late
- A long TTS response can block user interruptions
- A tool call delay can create awkward silence
Therefore, QA must focus on interaction quality, not just correctness.
This is why modern voice bot testing methods emphasize end-to-end evaluation.
How Are Voice Bots Different From Chatbots From A QA Perspective?
Many teams reuse chatbot QA frameworks for voice bots. However, this approach misses critical issues.
First, chatbots are asynchronous. Users type, wait, and read. Voice bots, on the other hand, are synchronous. Users expect immediate feedback.
Second, chatbots hide latency better. A one-second delay feels acceptable in chat. In voice, the same delay feels broken.
Third, audio adds new failure points. Background noise, accents, low-quality microphones, and packet loss all affect quality. These issues do not exist in text-based systems.
Because of these differences, QA teams must test for:
- Timing, not just content
- Flow, not just intent accuracy
- Perceived quality, not just technical success
As a result, voice bot QA requires a mindset shift.
How Should QA Teams Evaluate Real-Time Voice Interactions?
To evaluate real-time interactions, QA teams need a structured framework. Random testing is not enough. Instead, evaluation should follow a clear set of dimensions.
The most effective approach is to test interactions across three layers:
1. Interaction Timing
Timing determines whether a conversation feels natural.
QA teams should measure:
- Time from user speech end to bot response start
- Delays between turns
- Pauses during tool calls or data fetches
Even when responses are correct, poor timing breaks trust.
2. Turn-Taking Behavior
Voice conversations depend on smooth turn-taking.
QA must test:
- Whether the bot stops speaking when the user interrupts
- Whether partial user speech is captured correctly
- Whether the bot resumes correctly after interruption
These are common failure points in real-time calls.
3. Conversation Flow
Flow goes beyond single responses.
QA should check:
- Whether context is carried across turns
- Whether clarifying questions make sense
- Whether the bot recovers from misunderstandings
Therefore, real-time evaluation must simulate real users, not scripted ones.
This is why test scenarios for real-time calls are critical.
What Are The Most Important Technical Metrics For Voice Bot QA?
While user experience is important, QA teams still need hard metrics. These metrics help identify root causes and track improvements over time.
Below are the core technical metrics QA teams should monitor.
Key Metrics For Voice Bot Testing
| Metric | What It Measures | Why It Matters |
| End-To-End Latency | Time from user speech to bot speech | Affects natural flow |
| Word Error Rate (WER) | STT accuracy | Impacts intent detection |
| Audio Drop Rate | Missing or cut audio | Breaks conversations |
| TTS Start Delay | Time before speech playback | Impacts perceived speed |
| Call Stability | Stream continuity | Prevents call failures |
However, metrics alone are not enough. QA teams must correlate metrics with user outcomes. For example, a low WER does not guarantee task success if timing is poor.
Because of this, metrics should always be reviewed alongside call recordings and transcripts.
This approach also helps with debugging audio streams, since patterns become visible over time.
How Should QA Teams Test Multi-Turn And Context-Aware Conversations?
Most real voice bots are multi-turn systems. They remember context, ask follow-up questions, and trigger actions. Therefore, QA must validate more than one-turn accuracy.
Key areas to test include:
Context Retention
QA should verify:
- Whether the bot remembers previous answers
- Whether corrections override earlier inputs
- Whether context resets correctly between calls
RAG And Tool Calling Accuracy
When bots fetch data or trigger actions:
- Is the correct tool called?
- Is the data spoken accurately?
- Is the response timed correctly?
Errors here often sound confident but are wrong. Therefore, QA must validate both logic and output.
Error Propagation
In voice bots, one error can cascade. A single STT mistake can lead to:
- Wrong intent detection
- Wrong tool call
- Wrong spoken response
Because of this, QA teams should trace failures backward, not just inspect the final answer.
This level of testing is essential for a reliable QA checklist for voice AI.
What Test Scenarios Should QA Teams Run For Real-World Voice Calls?
Synthetic tests are useful, but they are not enough. Real users behave unpredictably. Therefore, QA teams must simulate real-world conditions.
Below are essential test scenarios:
- Short and vague responses (“yes”, “okay”, “hmm”)
- Long pauses before answering
- Users speaking over the bot
- Background noise and echo
- Accents and varied speech speed
- Call drops and reconnections
Each scenario should be tested across:
- Different devices
- Different network conditions
- Different conversation paths
By doing this, QA teams can catch issues before users do.
This approach also strengthens pre-launch validation for AI agents, which is critical before scaling.
How Can QA Teams Debug Issues In Live Audio Streams?
Even with strong test coverage, voice bots will fail if teams cannot debug them properly. Unlike chat systems, voice issues are harder to see. Audio problems often appear as “bad experience” rather than clear errors.
Therefore, QA teams must treat debugging audio streams as a core responsibility, not an afterthought.
Common Audio-Level Issues QA Teams Encounter
Most production issues fall into a few repeatable patterns:
- Delayed responses despite correct AI output
- Missing or clipped user audio
- Bot speaking over the user
- Long silence during backend processing
- Inconsistent audio quality mid-call
While these issues may appear random, they usually originate from the voice transport layer.
How QA Teams Should Debug Step By Step
To debug effectively, QA teams should follow a layered approach.
Step 1: Separate Audio From Logic: First, confirm whether the AI logic is correct using transcripts. If the logic is sound but the audio is broken, the issue is likely in streaming or playback.
Step 2: Inspect Timing Between Events: Next, analyze timestamps:
- When did audio arrive?
- When did STT finalize?
- When did the AI respond?
- When did TTS playback start?
Delays between these steps often explain user complaints.
Step 3: Compare Expected Vs Actual Flow: Finally, replay the interaction and compare it against the expected conversation flow. This helps identify missing interrupts or late responses.
By following this process, QA teams can isolate problems quickly and avoid guessing.
How Should QA Be Structured Across Pre-Launch And Post-Launch Phases?

QA for voice bots does not end at launch. In fact, many issues only appear at scale. Because of this, QA must be continuous.
Pre-Launch Validation For AI Agents
Before launch, QA teams should focus on controlled testing.
This includes:
- End-to-end call simulations
- Stress testing with concurrent calls
- Failure injection (network delay, tool timeouts)
- Review of edge cases discovered during testing
At this stage, the goal is not perfection. Instead, the goal is to reduce unknown risks.
Strong pre-launch validation for AI agents prevents costly rollbacks later.
Post-Launch QA And Monitoring
After launch, QA shifts from testing to observation.
Key activities include:
- Monitoring latency and error trends
- Reviewing failed or escalated calls
- Sampling real conversations weekly
- Tracking quality drift after model updates
Because voice bots evolve, QA must evolve with them. Otherwise, small changes can silently degrade quality.
Where Does Voice Infrastructure Fit Into QA And Why Does It Matter?
Many teams assume QA failures are caused by the AI model. However, in voice systems, infrastructure is often the hidden problem.
Voice bots rely on real-time audio streaming. If this layer is unstable, no amount of prompt tuning will fix the experience.
This is where infrastructure choice directly affects QA outcomes.
Why Infrastructure Impacts Voice Bot Quality
Poor infrastructure can cause:
- Audio buffering
- Late STT input
- Delayed TTS playback
- Inconsistent turn-taking
These issues appear to users as “the bot feels slow” or “the bot talks over me”.
QA teams need infrastructure that is:
- Low latency
- Predictable
- Observable
- Designed for real-time voice, not just calls
How FreJun Teler Supports Better Voice Bot QA
FreJun Teler is built as a voice infrastructure layer for AI agents, not as a calling-only platform.
From a QA perspective, this matters for several reasons:
- Real-Time Media Streaming: Teler streams audio with low latency, which helps QA teams evaluate natural turn-taking without artificial delays.
- Clear Separation Between Audio And AI Logic: Since Teler handles the voice layer, QA teams can isolate whether issues come from AI logic or audio transport.
- LLM, STT, And TTS Agnostic Design: QA teams can test different models and services without changing the voice infrastructure, making comparisons reliable.
- Event-Level Visibility: Teler exposes call events and timing signals, which helps QA teams trace issues instead of guessing.
Because of this, QA teams spend less time debugging transport problems and more time improving interaction quality.
What Does A Practical QA Checklist For Voice AI Look Like?
To make QA repeatable, teams need a checklist. This ensures consistency across releases and team members.
Below is a simplified QA checklist for voice AI that teams can adapt.
Before The Call
- Audio capture starts immediately
- STT receives partial transcripts
- Initial latency is within target range
During The Call
- Bot responds within acceptable time
- Interruptions are handled correctly
- Context is maintained across turns
- Tool calls complete without silence
After The Call
- Transcript matches spoken content
- Task outcome is correct
- No unexplained delays occurred
- Logs and metrics are complete
This checklist helps QA teams move from reactive testing to proactive quality control.
How Can QA Teams Improve Voice Bot Quality Over Time?
Voice bot quality is not static. Models change. Prompts evolve. User behavior shifts. Therefore, QA must support continuous improvement.
Using QA Data For Better Models
QA findings should feed back into development:
- Update prompts based on failures
- Improve STT handling for common errors
- Adjust response length and pacing
Over time, this reduces repeated issues.
Monitoring Quality Drift
Even small changes can affect quality.
QA teams should:
- Track key metrics weekly
- Compare new releases with baselines
- Watch for rising latency or error rates
This prevents silent degradation.
Treating QA As A Product Function
The best teams treat QA as part of product design. They ask:
- Does this interaction feel natural?
- Does it respect the user’s time?
- Would I trust this system on a real call?
This mindset leads to better voice products.
Final Thoughts
Quality assurance is the foundation of successful voice bots. When QA teams evaluate interactions instead of isolated components, they uncover issues that directly impact user trust, latency, interruptions, unclear audio, and broken conversational flow. For teams building voice bots at scale, QA must combine real-time testing, technical metrics, and real-world call scenarios across the entire voice stack.
This is where having the right voice infrastructure matters. FreJun Teler enables teams to test, observe, and optimize real-time voice interactions while remaining fully flexible with any LLM, STT, or TTS provider. By handling low-latency media streaming and call transport, Teler lets QA and engineering teams focus on interaction quality, not plumbing.
Schedule a demo to see how FreJun Teler supports production-grade voice bots.
FAQs –
1. What is the biggest QA challenge when building voice bots?
Managing real-time latency, interruptions, and audio quality together is harder than validating AI responses alone.
2. How is voice bot QA different from chatbot QA?
Voice bots require testing timing, audio flow, and turn-taking, not just intent accuracy or response correctness.
3. What metrics matter most for voice bot testing?
End-to-end latency, STT accuracy, audio stability, interruption handling, and task completion rate matter most.
4. Why do voice bots fail even with accurate AI models?
Poor audio streaming, delayed responses, or broken turn-taking can ruin interactions despite correct AI logic.
5. How should QA teams test real-world voice scenarios?
By simulating accents, noise, interruptions, short answers, long pauses, and unstable network conditions.
6. What is pre-launch validation for AI agents?
It ensures voice bots perform reliably under real call conditions before exposure to production users.
7. How do QA teams debug live audio issues?
By separating audio transport issues from AI logic and analyzing timing across streaming, STT, and TTS stages.
8. Should QA teams test voice bots end-to-end?
Yes, because most failures occur when STT, AI, TTS, and streaming interact under real-time conditions.
9. How often should voice bot QA be repeated after launch?
Continuously, especially after model updates, prompt changes, traffic spikes, or infrastructure changes.
10. Why does voice infrastructure impact QA outcomes?
Because unstable or high-latency audio transport directly affects user experience and test reliability.