
Building a voice AI system is no longer about choosing the best language model alone. In production, voice AI behaves like a live system where audio must move, respond, and scale in real time. Delays, dropped packets, or region-bound infrastructure quickly turn intelligent agents into unusable experiences.
That is why cloud-based media streaming has become the core foundation of scalable voice AI. By treating voice as a continuous stream instead of static files, teams can build systems that respond naturally, scale across regions, and remain resilient under load.
This article explains how scalable voice AI systems are designed – and why media streaming is the architecture that makes them possible.
Why Is Building Voice AI So Hard To Scale In Production?
Voice AI feels simple during early demos. You connect speech-to-text, pass the transcript to an LLM, convert the response to audio, and play it back. However, once real users start calling from different locations, the system begins to fail.
This happens because voice is time-sensitive, stateful, and interactive. Unlike chat, delays of even a few hundred milliseconds are noticeable. As a result, users start talking over the AI or disconnecting entirely.
In production systems, teams usually face issues such as:
- Delays between user speech and AI response
- Audio cutting out or starting late
- Inability to interrupt the AI mid-sentence
- Sudden cost spikes as call volume grows
- Regional latency for global users
Therefore, scaling voice AI is not only an AI problem. Instead, it is largely an infrastructure and media streaming problem.
Most failed implementations share one root cause: they treat audio as data, not as a continuous real-time stream.
What Does A Scalable Voice AI System Actually Consist Of?
At a high level, every voice AI system has the same functional components. However, the way these components are connected decides whether the system scales or breaks.
A production-ready voice AI system consists of:
| Layer | Responsibility |
| Media Streaming | Capture and deliver real-time audio |
| Speech To Text (STT) | Convert live audio into partial and final transcripts |
| AI / LLM | Decide what to say or what action to take |
| Context & RAG | Maintain conversation history and fetch relevant data |
| Tool Calling | Trigger backend actions (CRM, calendar, payments) |
| Text To Speech (TTS) | Convert responses into audio |
| Playback Layer | Stream audio back to the caller |
However, the order matters.
If media streaming is weak, every layer above it inherits latency. Consequently, even the best LLM cannot fix a slow audio pipeline.
That is why media streaming sits at the foundation of scalable voice AI systems.
Why Is Media Streaming The Foundation Of Real-Time Voice AI?
Media streaming means maintaining a persistent, bidirectional audio flow between the caller and your backend. Unlike file upload approaches, streaming does not wait for the speaker to finish talking.
Instead, audio is delivered in small chunks as the user speaks.
Because of this, media streaming enables:
- Partial transcriptions from STT
- Fast turn detection
- Real-time interruptions
- Natural back-and-forth conversations
Without media streaming, systems rely on batching audio files. As a result, they introduce delays at every stage: upload, processing, response generation, and playback.
Streaming Vs Non-Streaming Audio
| Approach | Outcome |
| Batch Audio Processing | High latency, unnatural conversations |
| Media Streaming | Low latency, real-time interaction |
Additionally, streaming allows systems to cancel playback immediately when a caller speaks. This is critical for natural conversations, yet impossible with batch audio responses.
Therefore, scalable streaming for AI is not an optimization. Instead, it is a requirement.
How Does Cloud-Based Voice Infrastructure Enable Scale?
Once streaming is adopted, the next constraint appears quickly: infrastructure scale.
Voice systems are connection-heavy. Each active call holds open audio streams, state, and timing expectations. If infrastructure is tightly coupled or single-region, it fails under load.
Cloud voice infrastructure solves this by separating concerns.
Key Characteristics Of Cloud Voice Infrastructure
- Stateless media edges with session routing
- Elastic scaling for concurrent calls
- Isolation between calls
- Fault tolerance without call drops
Moreover, cloud infrastructure allows media systems to handle spikes in traffic without manual provisioning. This is especially important for outbound campaigns and support peaks.
From a design perspective, this separation enables:
- One layer for media transport
- One layer for AI logic
- One layer for state and data
As a result, each layer can scale independently.
What Role Does Multi-Region Media Streaming Play In Global Voice AI?
As soon as voice AI is offered globally, latency becomes a geographical problem.
Audio does not tolerate distance well. Even small delays cause noticeable gaps in conversation flow. Therefore, routing all calls to a single region increases perceived delay.
Multi-region voice streaming solves this by placing media ingestion near users.
With about 40% global 5G coverage in 2023, multi-region streaming architectures can leverage low-latency mobile access where available while still supporting older networks gracefully.
Why Multi-Region Streaming Matters
- Reduces round-trip latency
- Improves speech recognition accuracy
- Prevents long silence gaps
- Supports regional compliance needs
However, multi-region systems must still maintain conversation continuity.
This requires:
- Session affinity routing
- Coordinated state replication
- Fast regional failover
Consequently, global voice API architecture must treat regions as interchangeable media access points, not rigid silos.
How Do You Design A Global Voice API Architecture For AI Agents?
A global voice API acts as the control plane for real-time voice interactions.
Instead of handling raw protocols directly, developers interact with a unified API that abstracts:
- Telephony integration
- Media transport
- Session lifecycle
- Event delivery
Responsibilities Of A Global Voice API
- Create and manage call sessions
- Stream audio events in real time
- Expose hooks for AI decision making
- Handle reconnects and retries
Importantly, the API should not embed AI logic. Instead, it should serve as a bridge between voice networks and your backend.
This separation allows teams to change models, prompts, or tools without touching the voice layer.
What Engineering Challenges Break Voice AI At Scale?
Once traffic grows, several hidden issues surface.
1. Turn Detection And Interrupt Handling
Humans interrupt each other naturally. Voice AI must do the same. This requires detecting speech onset early and stopping TTS immediately.
2. Latency Budget Control
Latency accumulates across:
- Audio capture
- Network transit
- STT processing
- LLM inference
- TTS generation
If any stage exceeds its budget, conversation quality drops.
3. Packet Loss And Jitter
Voice traffic must handle unreliable networks gracefully. Otherwise, audio becomes choppy or delayed.
4. Stateful Conversation Management
Context must survive reconnects and retries without duplication or loss.
Because of these challenges, scalable voice systems are event-driven, not request-driven.
How Can Any LLM, STT, And TTS Be Combined Effectively?
The strongest voice AI systems are model-agnostic.
Instead of binding architecture to one vendor, they define clean interfaces between components.
Best Practices For Component Integration
- Stream audio to STT, not files
- Send partial transcripts to the LLM
- Keep RAG context short and recent
- Stream TTS output instead of waiting for full audio
- Support dynamic tool calls mid-conversation
This allows teams to experiment with better models over time without redesigning the system.
Where Does FreJun Teler Fit In A Scalable Voice AI Stack?
So far, we have established that scalable voice AI depends on three things:
- Real-time media streaming
- Cloud-based voice infrastructure
- Multi-region, low-latency architecture
However, most teams struggle at the exact point where telephony meets AI logic. Managing SIP, PSTN, real-time audio streams, retries, and global routing quickly becomes a bottleneck.
This is where FreJun Teler fits into the system.
FreJun Teler functions as the cloud voice and media streaming layer between voice networks and your AI backend. Instead of building and maintaining carrier integrations, media handling, and regional routing, teams rely on Teler to handle the voice layer while keeping full control of AI logic.
What Teler Handles Technically
- Real-time media streaming for inbound and outbound calls
- Cloud voice infrastructure across regions
- SDKs to stream audio events to your backend
- Low-latency playback of streamed TTS audio
- Telephony and VoIP abstraction
What Your System Controls
- LLM selection and orchestration
- Prompting and agent logic
- RAG pipelines and data access
- Tool calls and workflow decisions
As a result, teams can focus on building intelligent behavior, not voice transport mechanics.
Sign Up with FreJun Teler Today!
How Does An End-To-End Voice AI Flow Work In Production?
Once a proper global voice API architecture is in place, an end-to-end voice interaction follows a predictable flow.
Below is a real-world implementation pattern used in scalable streaming for AI systems.
Step-By-Step Voice AI Flow
- Call Is Initiated: A user initiates or receives a call through PSTN or VoIP. The cloud voice layer establishes a session.
- Media Streaming Starts: Audio is streamed in real time to the backend as small chunks, not files.
- Streaming STT Processing: Audio chunks are passed to a streaming STT engine, which emits partial and final transcripts.
- LLM Decision Loop: Partial transcripts are forwarded to the LLM. The model decides whether to respond, wait, or call a tool.
- Tool Calling (If Needed): The LLM may fetch data such as order status, booking availability, or CRM context.
- Streaming TTS Output: The response text is sent to TTS. Audio output is streamed immediately as it becomes available.
- Audio Playback To Caller: TTS audio is streamed back through the voice layer with minimal buffering.
- Interruption Handling: If the caller speaks mid-response, playback is cancelled instantly.
This flow enables natural, human-style conversations while maintaining system control.
How Do You Handle Turn Detection And Interruptions Reliably?
Turn detection is one of the hardest problems in voice AI. Poor handling causes either awkward silence or constant talk-overs.
Key Techniques Used In Production Systems
- Voice Activity Detection (VAD) to detect speech start
- Short pause thresholds instead of fixed silence timers
- TTS cancellation hooks when speech resumes
- Partial transcript monitoring to anticipate interruptions
Additionally, turn detection logic should run close to the media layer. Otherwise, network delays reduce accuracy.
Therefore, scalable voice systems treat turn detection as part of the streaming pipeline, not an AI afterthought.
How Should You Manage Conversation Context At Scale?
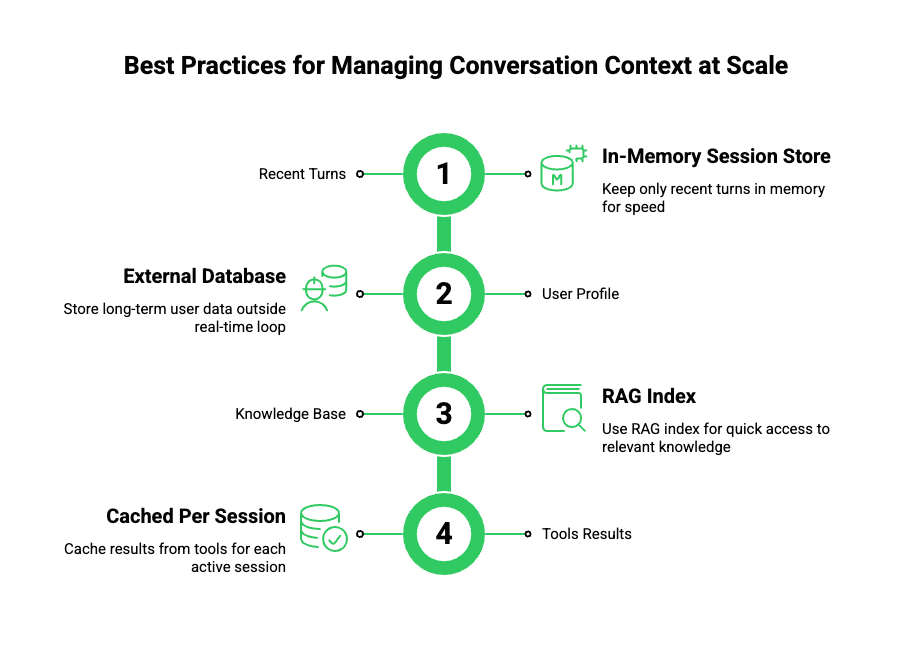
State management becomes complex when thousands of calls are active concurrently.
Although voice interactions feel sequential, production systems must treat them as event streams.
Best Practices For Context Management
- Maintain only recent turns in memory
- Store long-term data outside the real-time loop
- Pass structured context to the LLM instead of raw transcripts
- Avoid session-wide prompt accumulation
| Context Type | Storage Strategy |
| Recent Turns | In-memory session store |
| User Profile | External database |
| Knowledge Base | RAG index |
| Tools Results | Cached per session |
Because of this separation, systems stay fast and predictable under load.
How Do You Scale Voice AI Without Exploding Costs?
Voice systems are often priced per minute, which makes inefficiency expensive.
Therefore, cost optimization must be architectural, not reactive.
Cost Control Techniques
- Stream silence but discard inactive frames
- End sessions early when intent is resolved
- Avoid long idle playback buffers
- Use region-aware routing to reduce cloud egress
Additionally, streaming pipelines help reduce waste. Since audio is processed incrementally, systems can stop work as soon as responses are no longer needed.
As a result, scalable streaming for AI becomes both faster and cheaper.
How Do You Ensure Reliability And Fault Tolerance?
Production voice AI must assume failures will happen.
Networks drop packets. Models time out. Regions go offline.
Reliability Design Principles
- Isolate each call session
- Use retries only at streaming boundaries
- Avoid global locks and shared state
- Design fast failover paths
Furthermore, multi-region voice streaming ensures that calls can be routed to the nearest available media endpoint without user impact.
Because of these safeguards, failures degrade gracefully instead of cascading.
How Do Security And Compliance Fit Into Voice Infrastructure?
Voice systems often contain sensitive information such as names, addresses, and payment details.
Therefore, security must be built into the transport layer itself.
Core Security Controls
- Encrypted media streams
- Secure API authentication
- Role-based access to call data
- Configurable data retention
Importantly, AI components should never receive more data than necessary. This minimizes risk without limiting functionality.
What Should Founders And Engineering Leaders Build First?
For teams starting now, prioritization matters.
Instead of adding features early, scalable systems focus on foundations.
Recommended Build Order
- Real-time media streaming
- Cloud voice infrastructure
- Multi-region session routing
- Event-based AI orchestration
- Tool calling and RAG
- Optimization and observability
Because each step depends on the previous one, skipping ahead usually leads to rework.
Final Thoughts: Why Cloud-Based Media Streaming Defines Voice AI At Scale
Scalable voice AI systems are not built by stitching models together. Instead, they are built by treating audio as a live system, not static data. Media streaming enables natural conversation. Cloud voice infrastructure enables scale. Multi-region streaming enables global reach.
When these layers are designed correctly, teams gain the freedom to iterate on AI logic without fear of infrastructure limits. Latency stays predictable. Reliability remains intact. Growth becomes manageable instead of risky.
That is why cloud-based media streaming is not optional. It is the foundation of every production-grade voice AI system.
FreJun Teler provides this foundation, allowing teams to implement any LLM, any STT or TTS, and scale voice agents globally with confidence.
FAQs –
- What is media streaming in voice AI?
Media streaming sends live audio in real time, enabling instant AI processing and natural conversations without waiting for full recordings. - Why is cloud voice infrastructure important?
It allows voice systems to scale, recover from failures, and handle high call volumes reliably. - Can I use any LLM with voice AI systems?
Yes. Voice infrastructure should be model-agnostic, supporting any LLM without architectural changes. - How does multi-region streaming reduce latency?
It routes audio to the nearest region, reducing network distance and response delays. - Is WebRTC necessary for voice AI?
WebRTC provides proven low-latency media transport and is widely used in production voice systems. - What causes delays in voice AI calls?
File-based audio handling, centralized regions, and synchronous APIs commonly introduce delays. - How does streaming help AI interrupt or barge-in?
Streaming processes audio continuously, allowing AI to respond before users finish speaking. - What is a global voice API architecture?
It separates media transport, AI logic, and application workflows using streaming APIs. - Can voice AI scale without rearchitecture?
Yes, if the underlying media and cloud infrastructure is designed for scalability. - Where does FreJun Teler fit?
Teler provides the global voice streaming layer, allowing teams to focus on AI logic.