
Voice AI products are judged in milliseconds, not features.
From customer support to voice authentication, users expect conversations to feel immediate, human, and uninterrupted. However, achieving that experience depends less on models and more on how audio moves through the system.
Low-latency media streaming determines how quickly speech travels, how responses flow, and how natural conversations remain under load. As AI enters real-time voice workflows, infrastructure becomes the deciding factor between usable systems and frustrating ones.
This blog explains why streaming-first voice architecture is foundational – and how teams can design systems that scale without sacrificing conversation quality.
Why Does Latency Matter So Much In Voice Conversations?
Voice is the most sensitive interface humans use with technology.
Unlike text or images, voice interactions happen in real time. Because of this, even small delays feel obvious and uncomfortable. Standards guidance recommends keeping one-way voice latency at roughly 150 ms or below to preserve natural turn-taking in conversations.
In human conversations:
- A pause longer than 200–300 milliseconds feels unnatural
- Delays over 700 milliseconds feel like the other person is not listening
- Anything over 1–2 seconds breaks conversational flow entirely
Because of this, latency is not a technical detail. Instead, it directly decides whether a voice interaction feels natural or automated.
However, many teams underestimate this impact. While they spend time improving AI models or speech quality, they often ignore how fast audio moves through the system. As a result, users experience awkward pauses, talk over the AI, or disconnect the call.
That is exactly why low-latency media streaming sits at the center of modern voice infrastructure for AI. Without it, even the best AI logic fails to deliver a usable experience.
What Is Low-Latency Media Streaming In Voice Infrastructure?
Low-latency media streaming refers to how quickly audio moves both ways during a live call.
More specifically, it measures:
- How fast user speech is captured
- How quickly it reaches processing systems
- How fast a voice response is played back
In voice systems, latency is usually discussed in two ways:
| Metric | What It Means |
| End-to-end latency | Time from user speech to AI response playback |
| Time To First Audio (TTFA) | Time until the AI’s first spoken word |
For real-time voice applications, both metrics matter. However, TTFA is often the most noticeable to users.
It is also important to separate streaming media from buffered media.
- Buffered media (like HLS video) waits for chunks of audio
- Streaming media sends and plays audio continuously
Because voice interactions cannot pause to buffer, streaming is the only viable approach.
As a result, modern voice systems rely on:
- Continuous audio capture
- Live packet transport
- Immediate playback as data arrives
This streaming layer in telephony is what allows real interaction instead of delayed responses.
How Does A Modern Voice AI Call Actually Work End-to-End?
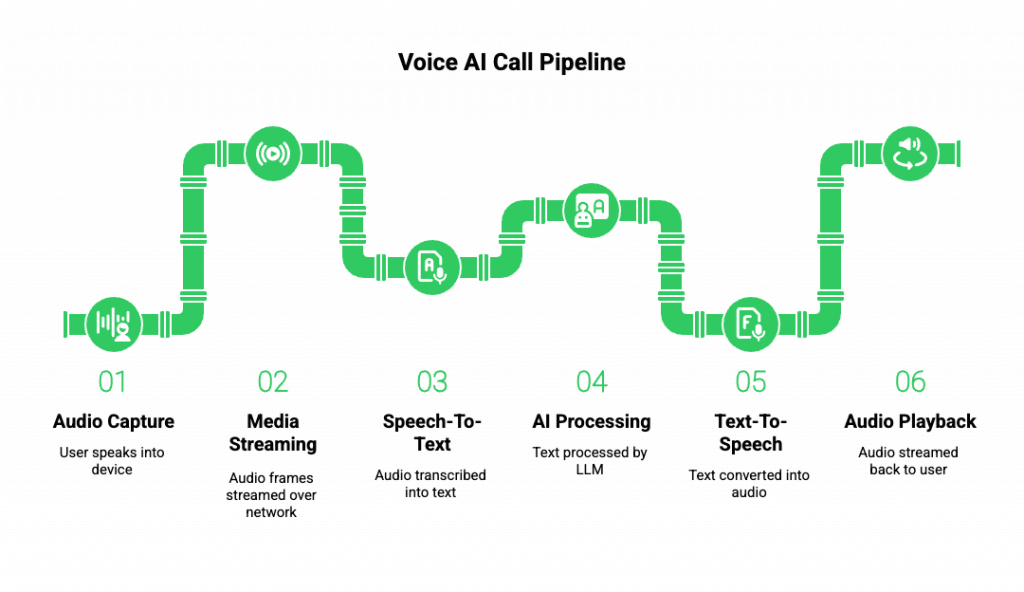
To understand why latency adds up, we first need to understand how voice calls work in modern AI systems.
A real-time voice AI call follows this pipeline:
- Audio Capture
- User speaks into a phone or soft client
- Audio is captured in small frames (typically 10–30 ms)
- User speaks into a phone or soft client
- Media Streaming
- Audio frames are streamed over the network
- Packets are sent continuously, not in batches
- Audio frames are streamed over the network
- Speech-To-Text (STT)
- Incoming audio is transcribed, often using a streaming ASR model
- Partial transcriptions are produced while the user is still speaking
- Incoming audio is transcribed, often using a streaming ASR model
- AI Processing
- Transcribed text flows into an LLM
- The LLM may query tools, databases, or RAG pipelines
- Tokens are generated progressively
- Transcribed text flows into an LLM
- Text-To-Speech (TTS)
- Generated text is converted into audio
- Audio can be streamed while generation is ongoing
- Generated text is converted into audio
- Audio Playback
- The response is streamed back over the call
- Playback starts as soon as audio packets arrive
- The response is streamed back over the call
This flow makes one thing clear:
A voice agent is not a single system – it is a live pipeline.
Because every stage runs in sequence, even small delays in each step create noticeable pauses. Therefore, optimizing individual components is not enough. Instead, the entire pipeline must be designed as a streaming system.
Where Does Latency Get Introduced In The Voice AI Pipeline?
Latency does not come from one source. Instead, it accumulates across several layers.
Let’s break it down.
Audio Capture And Framing
- Audio is recorded in small frames
- Larger frames reduce overhead but increase delay
- Smaller frames lower latency but increase packet volume
Even this early step influences total delay.
Network Transport
- Packet travel time depends on routing, distance, and congestion
- Jitter causes packets to arrive unevenly
- Packet loss forces retransmissions or concealment
This is why voice systems need stable, optimized media paths.
Speech-To-Text Processing
- Batch transcription waits for full sentences
- Streaming STT emits partial results early
Because of this, streaming STT is critical for fast responses.
LLM Reasoning And Tool Calls
- Token generation speed depends on model size
- Tool calls (APIs, databases) may add hundreds of milliseconds
- RAG queries increase variability
Without careful orchestration, this stage becomes the biggest latency contributor.
Text-To-Speech Generation
- High-quality voices take longer to synthesize
- Non-streaming TTS waits for full text
- Streaming TTS begins playback immediately
Therefore, modern systems favor incremental synthesis over full response generation.
Audio Playback
- Jitter buffers smooth playback
- Larger buffers reduce glitches but add delay
Once again, tradeoffs must be balanced.
Because latency compounds, the difference between a responsive and slow system often comes down to architecture, not models.
Why Is Streaming The Only Viable Architecture For Real-Time Voice?
Request-response architectures work well for text. However, they fail voice use cases.
Here’s why:
- Voice has no “submit” button
- Humans expect responses while they speak
- Silence feels like failure
Streaming solves this by changing how systems think about time.
Instead of waiting for completion:
- Audio is sent as it is spoken
- Transcripts appear before speech ends
- LLM tokens stream as they are generated
- TTS speaks while the AI is still thinking
This creates overlapping execution rather than serial waits.
As a result:
- Perceived latency drops
- Conversations feel continuous
- Interruptions and barge-ins are possible
This low latency architecture mirrors how humans talk – listening, thinking, and responding at the same time.
What Does A Low-Latency Voice Infrastructure Need To Do Well?
When evaluating a voice infrastructure for AI, certain capabilities are essential.
Core Requirements
- True bidirectional media streaming
- Support for partial audio and transcripts
- Stable long-lived connections
- Token-level streaming compatibility
Performance Capabilities
- Predictable latency under load
- Global routing awareness
- Minimal jitter and packet loss
Integration Flexibility
- Works with any LLM
- Works with any STT/TTS
- Supports custom RAG and tools
Observability
- End-to-end latency tracking
- TTFA measurement
- Clear visibility into bottlenecks
Together, these features define a high-performance voice API fit for AI-driven use cases.
Why Traditional Telephony APIs Struggle With AI Voice Use Cases
Many telephony platforms were designed for a different era.
Their core strengths include:
- Reliable call setup
- Call routing
- Billing and compliance
However, AI voice systems demand more.
Traditional platforms often:
- Assume batch audio handling
- Focus on call events, not media flow
- Lack fine-grained streaming control
- Provide limited latency visibility
As a result, teams are forced to build complex workarounds. Even then, latency issues persist.
This gap is why modern voice infrastructure must treat media streaming as a first-class concern – not an add-on.
How Can Teams Design Low-Latency Voice AI Systems In Practice?
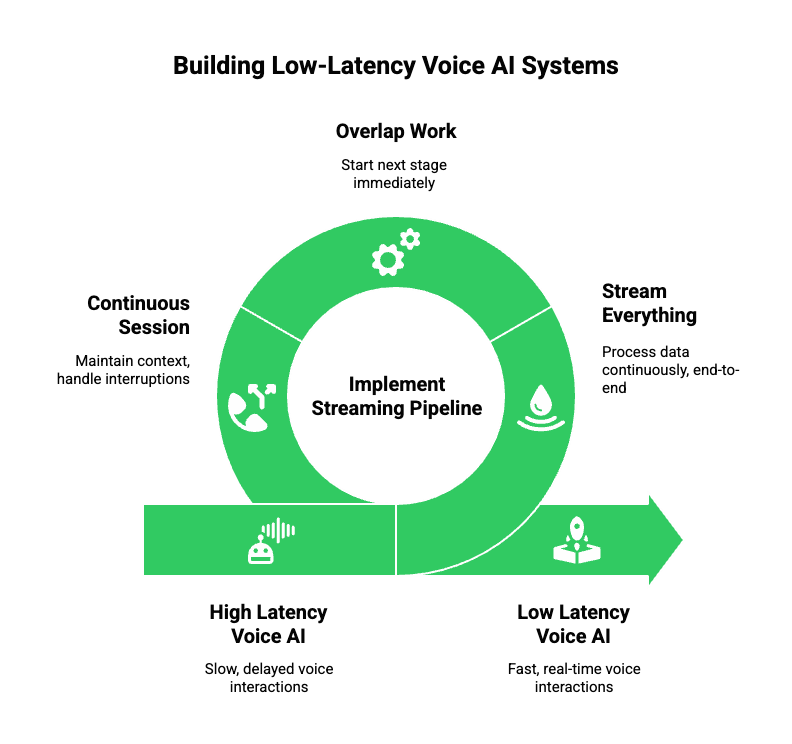
Once teams understand where latency comes from, the next challenge is implementation.
Although the theory is clear, real-world systems often struggle because components are added without considering how they interact in real time. Therefore, the goal is not simply to assemble STT, an LLM, and TTS, but to connect them through a continuously streaming pipeline.
A practical low-latency voice architecture follows three clear principles:
1. Stream Everything, End To End
Instead of waiting for completion at each stage:
- Stream incoming audio frames without buffering
- Consume partial transcripts from speech recognition
- Stream tokens from the LLM as they are generated
- Begin speech synthesis as soon as text stabilizes
Because of this approach, perception shifts from delay to flow.
2. Overlap Work Wherever Possible
In high-performing systems:
- The user is still speaking while transcription begins
- The AI begins reasoning while transcription continues
- Speech playback starts while the AI is still generating
As a result, overall response time drops without requiring faster models.
3. Treat Voice As A Continuous Session
Voice interactions are not isolated requests. Instead, they are long-running stateful sessions. For this reason:
- Connections must stay open
- Context must be preserved
- Interruptions must be handled gracefully
This mindset is essential for building voice infrastructure for AI that works reliably at scale.
How Should Speech, AI, And Tools Be Orchestrated Together?
Latency is often lost during orchestration, not model execution.
Although STT, LLMs, and TTS may each be fast individually, poor coordination creates pauses. Therefore, orchestration deserves just as much attention as model choice.
Recommended Orchestration Flow
- Streaming STT With Partial Results
- Partial transcripts provide early intent signals
- Enables AI planning before speech ends
- Partial transcripts provide early intent signals
- Incremental LLM Processing
- Feed partial text into the LLM
- Stream generated tokens instead of waiting for full output
- Feed partial text into the LLM
- Controlled Tool Invocation
- Trigger tools only after confidence thresholds
- Cache common queries to avoid repeat delays
- Trigger tools only after confidence thresholds
- Progressive TTS Generation
- Convert stable phrases into audio immediately
- Avoid waiting for full responses unless necessary
- Convert stable phrases into audio immediately
This orchestration model minimizes idle time across the pipeline. As a result, it reduces both actual and perceived latency.
What Makes Real-Time Voice Infrastructure Different From Calling Infrastructure?
At this point, an important distinction becomes clear.
Calling infrastructure focuses on:
- Call setup
- Call routing
- Minutes, records, and billing
Voice AI infrastructure, however, focuses on:
- Continuous media streaming
- Latency guarantees
- Conversational flow control
The difference is not superficial.
| Calling-Focused Systems | Voice AI Infrastructure |
| Event-driven | Stream-driven |
| Batch audio handling | Live audio frames |
| Call lifecycle focus | Conversation flow focus |
| Limited AI awareness | AI-first orchestration |
Because of this gap, many teams struggle when they attempt to build AI voice agents on top of traditional telephony stacks. Even if calls connect reliably, conversations still feel slow.
This is where a dedicated streaming layer in telephony becomes essential.
How Does FreJun Teler Fit Into A Modern Voice AI Architecture?
This is where FreJun Teler enters the picture.
FreJun Teler is designed as a low-latency media streaming layer that sits between telephony networks and your AI systems. Instead of bundling AI logic, it focuses entirely on transporting voice in real time – reliably and fast.
How Teams Use Teler In Practice
At a high level:
- Teler handles inbound and outbound calls
- Live audio is streamed to your backend with minimal delay
- Your system connects any LLM, STT, TTS, RAG, or tools
- Generated audio is streamed back instantly to the caller
In other words:
You bring the intelligence.
Teler handles the voice infrastructure.
Why This Separation Matters
Because Teler is model-agnostic:
- Teams are not locked into a specific AI provider
- Models can be swapped without changing voice plumbing
- AI logic stays inside the organization’s systems
Technically, Teler solves hard problems such as:
- Maintaining stable, long-lived media streams
- Handling bidirectional audio efficiently
- Managing routing, jitter, and network variability
- Providing SDKs that simplify streaming integrations
As a result, teams can focus on building better agents instead of rebuilding telephony foundations.
What Use Cases Depend Most On Low-Latency Streaming?
Low latency is not just about speed. Instead, it unlocks entirely new use cases.
Intelligent Inbound Call Handling
- AI receptionists that do not pause awkwardly
- Conversational IVRs that respond mid-sentence
- Support agents that clarify and interrupt naturally
Scalable Outbound Voice Automation
- Lead qualification without robotic delays
- Reminder calls that feel conversational
- Feedback collection with natural pacing
Internal Enterprise Workflows
- Voice-based dashboards
- Automated call reviews
- Agent assist systems during live calls
In all these cases, latency directly affects outcomes. Faster responses increase trust, completion, and adoption.
Sign Up with FreJun Teler Now!
How Should Teams Measure Low-Latency Voice Performance?
Measurement is critical. Without it, teams optimize blindly.
Key Metrics To Track
- Time To First Audio (TTFA): Measures how fast the system begins responding
- End-To-End Latency (P50 / P95 / P99): Percentiles reveal real-world performance
- Jitter And Packet Loss: Directly impact perceived audio quality
- Barge-In Success Rate: Indicates responsiveness during interruptions
Why Averages Are Misleading
Average latency hides edge cases. Therefore, high-performing systems always track percentiles. A system that feels fast most of the time but stalls occasionally still feels unreliable to users.
Monitoring these metrics allows teams to tune codecs, buffering, routing, and orchestration continuously.
Why Low-Latency Media Streaming Enables The Future Of Voice AI
As AI models improve, expectations will rise – not relax.
Users will expect:
- Immediate acknowledgment
- Natural turn-taking
- No pauses or overlaps
At the same time:
- Models will grow more capable
- Tool usage will increase
- Conversations will become longer
Because of this, latency budgets will become stricter, not looser.
Low-latency media streaming is what makes this future possible. It is the backbone that allows intelligence to flow naturally through voice conversations.
Without it:
- AI feels slow
- Voice feels unreliable
- Automation adoption stalls
With it:
- Conversations feel human
- Systems scale confidently
- Voice becomes a true interface, not a workaround
Final Thoughts
Modern voice systems succeed or fail based on infrastructure, not ideas.
While advanced models shape intelligence, media streaming defines experience. Without a streaming-first foundation, even the best AI struggles with broken turn-taking, delayed responses, and unnatural conversations.
Teams that prioritize low-latency architecture early avoid costly re-engineering as traffic, AI complexity, and global scale increase. By treating voice as a continuous stream – not a sequence of requests, teams can deliver predictable performance across STT, inference, and TTS.
Teler is built around this principle. Its streaming-native voice infrastructure gives product and engineering teams precise control over latency, routing, and real-time audio flow, without rebuilding telephony stacks from scratch.
Low-latency media streaming is not optional.
It is the backbone of modern voice infrastructure.
FAQs –
1. Why does my voice AI feel slow even with fast models?
Latency usually comes from buffering, transport, or orchestration – not the model itself—especially when audio is processed in batches.
2. What latency is acceptable for real-time voice AI?
Conversations feel natural below 150 ms one-way latency; beyond that, turn-taking and interruptions become noticeable.
3. Is WebRTC required for low-latency voice systems?
Not always, but WebRTC or RTP-based streaming protocols are commonly used to achieve sub-second audio delivery.
4. Why does batch audio processing fail for live calls?
Batch processing waits for full audio chunks, which delays responses and breaks conversational flow.
5. Where does most voice AI latency originate?
Streaming STT delays, external tool calls, buffering layers, and audio transport decisions contribute most.
6. Can cloud deployment increase voice latency?
Yes, poor regional routing and centralized processing can add hundreds of milliseconds if not optimized.
7. How do teams measure voice latency accurately?
By tracking TTFA, token emission time, and end-to-end percentiles (p90, p99) instead of averages.
8. Does encryption impact voice streaming latency?
Proper real-time protocols like SRTP secure audio without introducing noticeable buffering overhead.
9. Why do voice systems break at scale?
Most are not designed as continuous streams, causing orchestration bottlenecks as traffic grows.
10. When should teams invest in streaming-first architecture?
At the earliest design stage – retrofitting streaming later is costly and structurally limiting.