
Voice agents are emerging as a critical interface. But creating a truly conversational system demands more than just a powerful LLM – it requires real-time media streaming that bridges telephony and intelligence. In this article, we explore how media streaming fuels latency-sensitive voice interactions, why traditional telecom platforms struggle, and what engineering teams must do to build robust, scalable voice-first applications.
Whether you’re a founder, product manager, or engineer, understanding streaming is key to deploying reliable LLM-powered voice agents.
Why Does Media Streaming Matter in LLM-Driven Voice Agents?
The modern voice agent is not a static IVR. Instead, it is a real-time system built on multiple moving components – LLMs, TTS engines, STT engines, telephony carriers, context managers, and tool-calling logic. However, none of these systems can work effectively unless audio flows instantly and reliably across all layers. This is where media streaming becomes a critical foundational block.
Although AI reasoning has evolved rapidly, latency in audio flow is often the biggest bottleneck in delivering natural, human-like conversations. Even the most advanced LLM fails to feel “intelligent” when audio takes 500–800 ms to reach or respond. Therefore, media streaming acts as the bridge between telephony networks and AI systems, ensuring that speech is captured, transported, converted, processed, and returned in near real time.
This is why understanding how media streaming works – and how it directly affects system quality – is essential for founders, product leads, and engineering teams building voice-enabled applications or AI contact automation.
How Exactly Do Voice Agents Work Behind the Scenes?
Before discussing media streaming in depth, it helps to examine the architecture of modern AI voice agents. Even though many implementations look different, almost all follow the same core flow:
Voice Agent = LLM + STT + TTS + Context Manager + Tool Calling Layer
Below is the high-level flow:
- Caller speaks – audio captured from PSTN, VoIP, or WebRTC
- Media stream delivers raw audio to the AI pipeline
- STT converts audio to text
- LLM interprets the text and applies context + memory
- LLM triggers actions (database queries, tool calling, APIs, RAG, etc.)
- Model generates response text
- TTS synthesizes voice output
- Media stream returns audio back to the caller in real time
Even though each step is important, the transport layer – the media stream – determines the conversation quality.
What Is Media Streaming in the Context of Voice AI?
Media streaming refers to the continuous bidirectional flow of audio packets between the telephony world and the AI processing system. Instead of sending audio in large chunks, media streaming delivers:
- small packets
- multiple times per second
- with minimal jitter and loss
This architecture ensures:
- near-zero delay
- stable audio quality
- uninterrupted LLM processing
- seamless STT/TTS loops
Without efficient streaming, the AI pipeline becomes slow and erratic. Even a 200 ms delay per step creates an unnatural “robotic gap” that breaks the experience.
Why Is Low Latency So Critical for LLM-Based Voice Agents?
Low latency decides whether the voice agent feels human or artificial. Since LLMs already compute at extremely high speeds, audio bottlenecks can become the limiting factor.
Standards bodies recommend one-way audio delay budgets below 150 ms for acceptable interactive voice; exceeding that range materially worsens turn-taking and user perception, which makes low-latency media streaming a hard requirement for live voice agents.
Below is a simplified latency breakdown:
| Layer | Typical Delay | Impact |
| Telephony – Media Stream | 10–20 ms | Base transport time |
| STT Interpretation | 20–50 ms | Early recognition boost |
| LLM Reasoning | 40–200 ms | Depends on model + tokens |
| TTS Generation | 30–80 ms | Voice response shaping |
| Media Stream – User | 10–20 ms | Return audio |
A well-built streaming layer keeps the entire conversational loop under 300–400 ms, which feels almost natural.
However, a poorly optimized stream pushes delays upward, causing:
- speaking-over interruptions
- overlapping responses
- blank pauses
- jittery playback
- unnatural speech timing
- failed STT segments
- repeated responses or context loss
This is why founders and engineering teams must treat media streaming as a core system requirement, not an optional add-on.
How Does Media Streaming Connect the Telephony World with LLM Systems?
Telephony systems – PSTN, SIP trunks, VoIP carriers – operate with strict rules around codecs, signaling, and RTP packet timings. On the other hand, AI systems work with raw audio streams, often using PCM, Opus, or WebRTC audio frames.
Therefore, the media streaming layer acts as the AI-to-telephony bridge, converting and delivering audio between:
- Legacy telephony infrastructure
- Modern LLM models
- STT/TTS engines
- Custom application logic
This bridge is responsible for:
Signal Conversion
- RTP packets – AI-friendly PCM frames
- Telephony codec (G.711, μ-law) – LLM/TTS codec (PCM16, Opus)
Transport Reliability
- jitter buffering
- packet ordering
- loss recovery
Timing Accuracy
- ensuring packets arrive exactly when expected
Bidirectional, concurrent streaming
- caller – AI
- AI – caller
Because of this bridging capability, media streaming allows any LLM to function as a large language model voice interface across real phone calls, support lines, sales operations, or automated outreach.
What Are the Core Components of a Voice Media Stream?
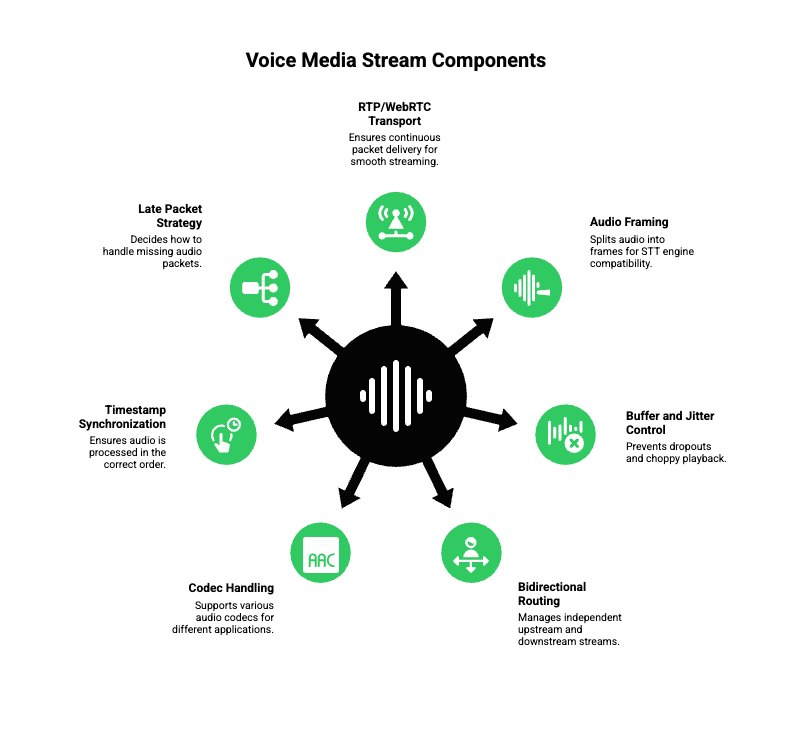
A robust media streaming system contains multiple technical layers working at once:
1. RTP or WebRTC Transport Layer
Ensures continuous packet delivery.
2. Audio Framing
Splits audio into 10–20 ms frames tailored for STT engines.
3. Buffer and Jitter Control
Prevents dropouts or choppy playback.
4. Bidirectional Routing
Two independent streams:
- Upstream (caller – AI)
- Downstream (AI – caller)
5. Codec Handling
Common codecs include:
- μ-law (telephony)
- A-law
- PCM16
- Opus (LLM/TTS optimized)
6. Timestamp Synchronization
Ensures the LLM receives audio in the correct order.
7. Late Packet Strategy
Decides whether to:
- replay
- drop
- re-synthesize missing audio
A properly configured pipeline lets the LLM start processing speech before the caller finishes the sentence, enabling predictive response and more natural timing.
What Breaks When Media Streaming Is Not Optimized?
Founders often assume voice agent issues come from “LLM hallucination” or “TTS delay,” when in reality the root cause is usually audio transport inefficiency.
Poor media streaming results in:
1. High Latency
- noticeable pauses after every sentence
- slow agent responses
- mismatch between STT input and LLM output
2. STT Errors
- missing words
- broken transcripts
- partial recognition
- incorrect segmentation
3. Choppy or Robotic TTS Playback
- jitter
- packet drops
- incorrect audio spacing
4. Conversation Overlaps
- AI starts speaking before user finishes
- user interruptions are ignored
- contextual mistakes accumulate
5. LLM Misinterpretation
- incomplete fragments reaching the model
- out-of-order speech frames
- context loss
These issues degrade user experience significantly, even if the LLM model is powerful.
Learn how to deploy production-grade voice agents using Teler & AgentKit – a practical guide from MCP to real-world LLM deployment.
How Do AI Voice Agents Use Streaming to Maintain Context?
LLM-based voice agents rely heavily on incremental real-time processing. Instead of waiting for full sentences, the system must begin interpreting speech while the user is still talking.
Media streaming enables:
1. Partial Transcription
STT can transcribe frames every 10–20 ms.
2. Early LLM Reasoning
LLMs can run:
- predictive intent estimation
- partial semantic analysis
3. Mid-Speech Interruption Detection
The AI can detect:
- user corrections
- objections
- new intent signals
4. Smooth Context Carryover
Because packets arrive in sequence, the LLM retains clean memory.
Without streaming, context management collapses into chunk-based processing, which feels unnatural for real-world calls.
How Does Media Streaming Enable Real-Time Actions & Tool Calling?
Modern voice agents are more than conversational. They execute actions through tool calling – checking calendars, pulling CRM data, validating phone numbers, generating summaries, or updating tickets.
These actions depend on precise timing:
- STT completes –
- LLM interprets –
- tool call executes –
- response arrives –
- TTS converts –
- stream returns the audio
Even small jitter or packet delay can cause:
- duplicated tool calls
- incorrect sequencing
- API retries
- mismatched responses
- broken UX
Thus, reliable media streaming ensures the pipeline moves seamlessly from speech – reasoning – action – speech, without system drift.
How Do Different Media Streaming Architectures Compare for Voice AI?

While many voice systems look similar on the surface, their streaming architectures vary significantly. As a result, engineering teams often struggle with unexpected latency or inconsistency.
Below is a simple comparison of the three common approaches:
A. Polling-Based Audio Transfer (Outdated)
- Sends audio in chunks
- Has 500–1000 ms delay
- Causes unnatural pauses
- Not suitable for real calls
B. WebSocket Audio Streaming
- Better than polling
- Works well for browser apps
- Not fully reliable for telephony-grade calls
- Still vulnerable to jitter
C. RTP-Based Media Streaming (Preferred for Voice AI)
- Sends small audio packets every 10–20 ms
- Lowest latency for both PSTN and VoIP
- Provides stable timing + jitter resistance
- Ideal for llm voice streaming systems
Because voice agents must sustain synchronous back-and-forth audio, RTP-based real-time media streaming is the most suitable architecture.
How Does Media Streaming Improve Accuracy in Voice Recognition and LLM Reasoning?
Even high-performance STT engines and LLMs depend on the timing and quality of the incoming audio. When media streaming is optimized, the AI pipeline becomes significantly more accurate.
A. Better STT Precision
Stable audio – cleaner phonemes – fewer errors.
B. Improved Sentence Boundaries
Because packets arrive consistently, the STT engine can detect:
- pauses
- emphasis
- sentence breaks
C. Faster LLM Interpretation
LLMs handle:
- partial transcripts
- incremental context
- predictive meaning extraction
This helps the model understand user intent earlier, reducing the total round-trip time.
D. More Natural TTS Output
Since timing is preserved, the TTS engine can match:
- pacing
- prosody
- stress patterns
- natural pauses
As a result, the voice agent feels smoother during real customer calls – including sales, support, routing, and follow-up workflows.
How Does Media Streaming Support Interruptions and Overlapping Speech?
Human conversations always include interruptions. People naturally:
- cut in
- change their mind mid-sentence
- correct the agent
- talk over the response
- add new context before finishing
In ordinary IVR or bot systems, this usually breaks the flow. However, llm voice streaming architectures handle interruptions effectively.
How interruption detection works
- Media stream sends audio continuously
- STT processes frames in parallel
- A detection module checks for new upstream packets
- If user begins speaking:
- TTS audio is paused
- LLM stops its response
- New user intent is processed immediately
- TTS audio is paused
Without streaming, interruption handling becomes clunky, often forcing the caller to wait until the bot finishes speaking. This is a major UX flaw that modern voice agents must avoid.
Sign Up for FreJun Teler Today!
Where Does Media Streaming Sit in the Full Technical Stack?
To understand the larger architecture, here is a simplified technical stack for an AI call media streaming system:
| Layer | Role |
| Telephony Layer | PSTN, SIP trunking, VoIP carriers |
| Signaling Layer | SIP, WebRTC signaling |
| Media Streaming Layer | RTP transport, packetization, jitter control |
| Audio Processing Layer | framing, buffering, codec conversion |
| STT Layer | phoneme detection, partial transcription |
| LLM Layer | reasoning, RAG, tool calling, context |
| TTS Layer | voice synthesis, prosody shaping |
| Outbound Stream | return audio to caller |
This structure reflects how a large language model voice interface actually functions in production.
Why Do Founders and Product Teams Need to Care About Streaming Infrastructure?
Many teams underestimate media streaming because they assume the “AI engine” is the main challenge. In reality, the AI logic is easier to manage than the voice transport pipeline.
Poorly built streaming will cause:
- high dropout rates
- caller frustration
- context resets
- inconsistent tone
- failed actions or API calls
- slow response experience
- reduced model quality perception
Because founders and product leads are aiming for real customer-facing automation, the reliability of the media pipeline becomes a business-critical decision, not only a technical choice.
How Does FreJun Teler Solve the Media Streaming Challenge?
Most AI or LLM-focused providers are strong on the model side but weak on the voice transport and telephony infrastructure. Conversely, traditional telephony companies are strong on voice but weak on AI.
FreJun Teler sits precisely in the middle, offering the ai-to-telephony bridge that connects any LLM, STT, or TTS engine with real phone calls.
Here is how Teler supports production-grade media streaming:
A. Low-Latency Real-Time Media Streaming
- optimized packet timing
- stable RTP transport
- millisecond-level audio handoff
- ensures conversational flow stays seamless
B. Carrier-Grade Telephony + AI-Friendly Audio
Teler handles:
- SIP trunking
- PSTN connectivity
- VoIP routing
- audio transcoding (μ-law – PCM16/Opus)
This eliminates compatibility issues that engineering teams usually face.
C. Model-Agnostic Architecture
Teams can plug in:
- any STT engine
- any TTS engine
- any LLM (OpenAI, Anthropic, local models, etc.)
- any custom context manager
D. Full Control Over Dialogue Logic
You maintain your entire AI logic.
Teler manages the streaming and transport.
E. Consistency Across Inbound and Outbound Calls
Whether the use case is:
- AI receptionist
- inbound support agent
- outbound sales automation
- appointment reminders
- self-service workflows
The streaming quality remains stable.
Because of this, engineering teams can move from prototype – scalable system without rebuilding their telephony backbone.
What Technical Best Practices Should Teams Follow When Implementing Voice AI?
To ensure stability and quality in llm voice streaming applications, engineering teams should adopt the following guidelines:
1. Use Opus or PCM16 for AI Processing
These codecs preserve clarity and phoneme-level detail.
2. Keep Packet Size Between 10–20 ms
This ensures fast STT turnaround.
3. Maintain a Consistent Jitter Buffer
Avoid dynamic resizing unless necessary.
4. Stream Audio Concurrently
Do not wait for full sentences; use partial frames.
5. Avoid Chunk-Based Architectures
These increase latency drastically.
6. Tune STT for Real-Time Scenarios
Enable partial transcription and early endpointing.
7. Prioritize Stable RTP Paths
Packet loss more than 3% will degrade TTS and STT noticeably.
8. Keep LLM Outputs Concise
Short responses reduce total round-trip time.
These optimizations ensure the voice agent feels natural during live customer calls.
What Future Developments Will Improve Media Streaming for AI Voice Agents?
Although the current streaming models are already strong, several advancements will push the field forward:
- faster incremental STT models
- LLMs optimized for half-duplex speech
- full-duplex, no-interruption dialogue engines
- adaptive streaming based on call environment
- client-side noise classification
- predictive TTS rendering
As these systems mature, voice agents will move closer to human conversational timing, reducing the gap between machine and natural interaction.
Final Thoughts
AI voice agents are not defined solely by their large language models. The media streaming pipeline is the true foundation of a lifelike, responsive, and reliable conversation. When you build a system with optimized call media streaming, you unlock natural dialogue flow, instant turn-taking, highly accurate transcription, rapid AI reasoning, smooth synthesized voice, and dependable telephony integration. For founders, engineering leads, and product teams focused on next-gen voice automation, investing in a robust, low-latency media layer is not optional – it’s essential for scaling.
Ready to build production-grade voice agents?
FAQs –
- Can I use any LLM with Teler’s media streaming layer?
Yes – Teler supports model-agnostic integration, so you can use OpenAI, Anthropic, or your own LLM. - Do I need to change my STT or TTS engine to use Teler?
No – Teler works with any STT or TTS provider you choose, letting you plug into your preferred stack. - How low can the call latency be while using streaming audio?
With optimized settings, round-trip audio latency can stay in the 300–400 ms range or lower. - Does media streaming support interruptions or barge-in during calls?
Yes – streaming allows caller interruptions, enabling mid-sentence context updates and smoother conversations. - How does Teler handle codec conversion between telephony and AI engines?
Teler transparently converts audio (e.g. µ-law – Opus or PCM), preserving quality and synchrony. - Can I combine real-time RAG/tool calling with streaming voice?
Absolutely – you can run retrieval or API calls mid-conversation while streaming, with minimal pause. - Is the voice data encrypted, and how is privacy handled?
Yes – Teler supports SRTP/TLS for media and TLS-encrypted control, with industry-standard compliance. - What happens if a call drops or reconnects?
Teler supports session persistence; it can rehydrate your conversation state on reconnection. - Do I need to manage my own jitter buffers and packet loss?
No – Teler’s media layer handles buffering, packet reordering, and jitter concealment for you. - Is Teler production-ready for high call volumes?
Yes – Teler is built for enterprise scale, with carrier-grade SIP / PSTN integration and robust scaling.