
You have just finished building a voice bot. The AI is brilliant, the conversational logic is flawless, and in your quiet development environment, the audio sounds perfect. But the moment you deploy it to the real world, the complaints start rolling in: “The bot sounded garbled,” “I couldn’t understand what it was saying,” “It kept misunderstanding me.”
The intelligence of your AI is being completely undermined by a problem that is much more fundamental: poor call quality. For any developer or business deploying a voice AI, understanding, measuring, and optimizing for call quality is not just a technical task; it is the absolute foundation of a successful user experience.
But “quality” is a notoriously subjective term. What one person considers “good” another might find “unacceptable.” To move from subjective opinion to objective engineering, you need a clear, data-driven framework. You need a set of standardized audio performance metrics that can tell you, with precision, exactly how good (or bad) your call quality is.
This guide will break down the essential metrics that define modern call clarity benchmarks and provide a clear framework for how to measure and optimize them.
Table of contents
Why is Measuring Call Quality So Critical for Building Voice Bots?
For a human-to-human conversation, our brains are incredibly good at compensating for poor audio. We can fill in the gaps, ask for clarification, and use context to understand a slightly garbled sentence. An AI’s “ears”, the Speech-to-Text (STT) engine, are far less forgiving.
The “garbage in, garbage out” principle is brutally absolute in voice AI. If the STT engine receives a choppy, low-quality audio stream, it will produce an inaccurate transcription.
This inaccurate text is then fed to your brilliant Large Language Model (LLM), which, despite its intelligence, is now working with corrupted data. It will misunderstand the user’s intent and provide an answer that is irrelevant or just plain wrong.
From the user’s perspective, the “bot is stupid,” when in reality, the bot is simply “deaf.” Therefore, measuring and ensuring the highest possible audio quality is the first and most important step in ensuring the accuracy of your entire AI system.
The Objective Metrics: Measuring the Network and the Signal
The first set of metrics are objective, technical measurements of the network’s performance and the audio signal itself. These are the numbers that your voice infrastructure provider should make available to you for every call.
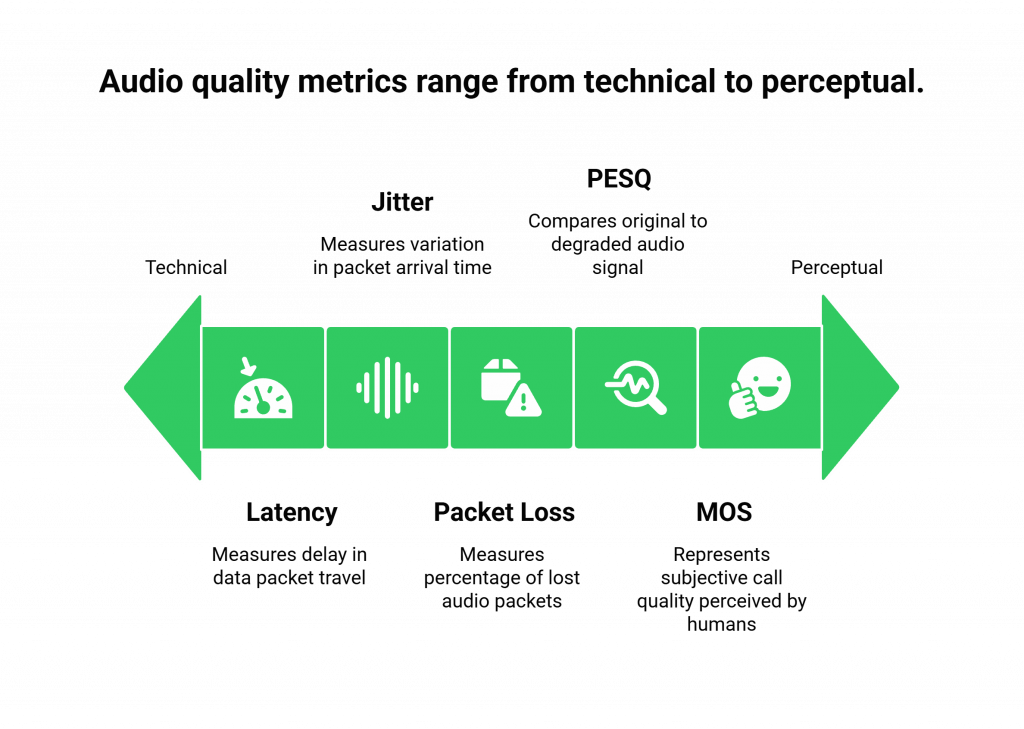
The “Big Three” of Network Health
These three metrics are the vital signs of the IP network that is carrying your call.
- Latency (or Round-Trip Time): This is the delay, measured in milliseconds (ms), for a data packet to travel from the speaker to the listener and back again. High latency is the cause of the awkward, unnatural pause in a conversation. For a good quality call, you want this to be consistently under 300ms.
- Jitter: This is the variation in the arrival time of the audio packets. If packets arrive in an uneven, spiky pattern, it forces the receiving device to either discard them or delay playback, both of which result in choppy, garbled audio. A jitter of less than 30ms is generally considered excellent.
- Packet Loss: This is the percentage of audio packets that are lost in transit and never arrive at their destination. Even a small amount of packet loss (1-2%) can cause noticeable gaps and dropouts in the audio.
Also Read: How Programmable SIP APIs Are Redefining Real-Time Communication?
The “Gold Standard” of Perceptual Quality: MOS and PESQ
While the network metrics are crucial, what we really care about is the perceived quality of the audio. Two of the most important metrics for this are MOS and PESQ.
- MOS (Mean Opinion Score): This is the mos voice quality measurement gold standard. It is a score from 1 (bad) to 5 (excellent) that represents the subjective quality of a call as perceived by a human listener. While it was originally determined by having actual humans score calls, modern systems use sophisticated algorithms that have been trained to predict a MOS score based on the technical characteristics of the audio stream. A MOS score of 4.0 or higher is generally considered high quality.
- PESQ (Perceptual Evaluation of Speech Quality): This is a more objective, algorithmic approach defined by the ITU-T P.862 standard. A pesq score analysis works by comparing the original, clean audio signal (before it was sent) to the degraded signal (after it has been received). It then generates a score, typically on a scale from -0.5 to 4.5, that correlates closely with the subjective MOS score. It is a powerful tool for automated quality testing.
The Subjective-but-Critical Metric: STT Accuracy
This is a metric that is unique and absolutely critical when building voice bots. Your network can be perfect and your MOS score can be a flawless 4.5, but if your STT engine is not accurately transcribing what the user is saying, your entire AI workflow will fail.
Understanding and Measuring STT Accuracy Scoring
The accuracy of a Speech-to-Text engine is typically measured using a metric called the Word Error Rate (WER).
- What is WER? WER compares the text that the STT engine produced to a “ground truth” human transcription of the same audio. It calculates the number of substitutions, deletions, and insertions required to get from the STT’s output to the correct text. A lower WER is better.
- How to Measure It: A robust stt accuracy scoring process involves taking a sample of your real-world call audio, having it transcribed by a human, and then running it through your STT engine to compare the results.
- Why It Matters: The WER of your STT engine is a direct input to the overall accuracy of your voice bot. If your WER is 20%, it means that, on average, one out of every five words is being misunderstood by your AI.
This table summarizes the key metrics, their targets, and what they measure.
| Metric | What It Measures | The Goal | Why It’s Critical for a Voice Bot |
| Latency | The delay in the conversation. | < 300ms round-trip | Prevents unnatural pauses and users talking over the AI. |
| Jitter | The unevenness of audio packet arrival. | < 30ms | Prevents choppy, garbled audio that is hard for the STT to understand. |
| Packet Loss | The percentage of lost audio packets. | < 1% | Prevents audio dropouts and missing words. |
| MOS (Mean Opinion Score) | The overall perceived quality of the audio. | > 4.0 | A holistic measure of how “good” the call sounds to a human (and an AI). |
| WER (Word Error Rate) | The accuracy of the STT transcription. | As low as possible (<10-15%) | Directly impacts the AI’s ability to understand the user’s intent. |
Ready to build on a platform that gives you deep visibility into all of these critical quality metrics? Sign up for FreJun AI
Also Read: SIP vs Programmable SIP What the Difference and Why It Matters for Developers
What is the Role of the Voice Infrastructure Provider in Building Voice Bots?
While you are responsible for your application’s logic and your choice of AI models, your voice infrastructure provider is your most important partner in achieving these call clarity benchmarks. A modern, developer-first provider like FreJun AI plays a critical role in three key areas.
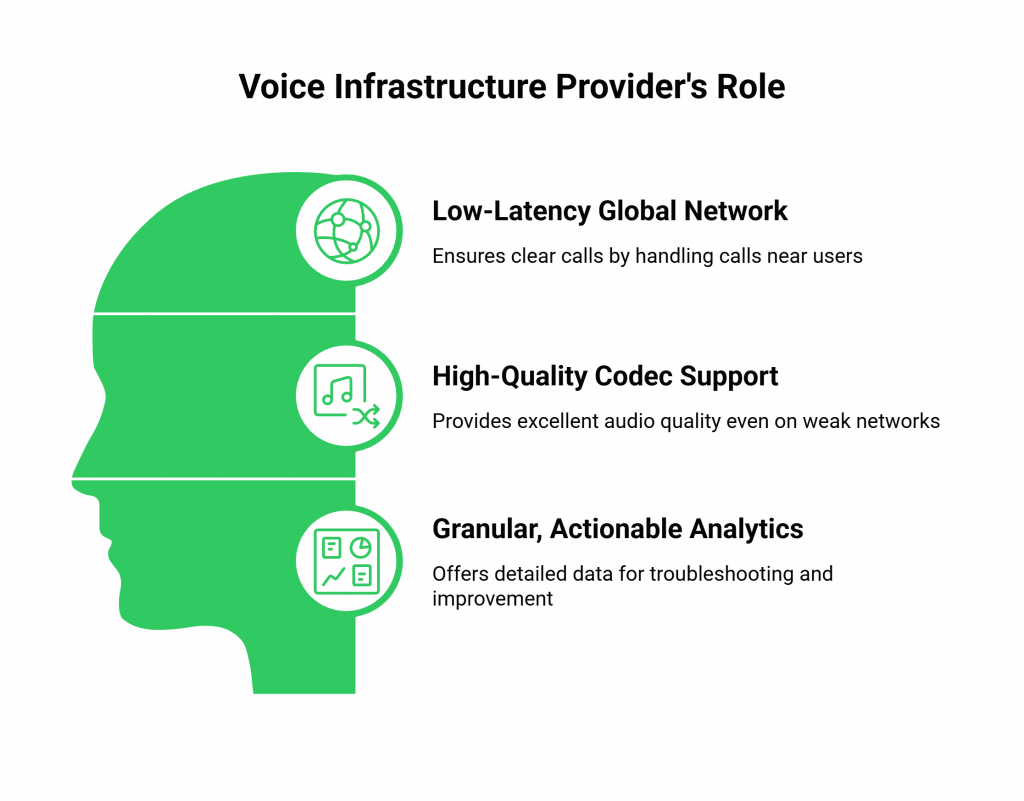
Providing a Low-Latency Global Network
The provider’s core architecture is the single biggest factor in combating latency, jitter, and packet loss. A provider with a globally distributed, edge-native network (like our Teler engine) can automatically handle the call at a location physically close to the user, ensuring the best possible network performance from the start.
Offering High-Quality Codec Support
The audio codec is the software that compresses and decompresses the voice. A good provider will support high-quality, modern codecs like Opus, which are designed to deliver excellent audio quality even on lower-bandwidth networks.
Delivering Granular, Actionable Analytics
You cannot fix what you cannot see. A key feature of a developer-first platform is deep observability. The provider must give you API access to detailed, per-call analytics that include all of the key audio performance metrics like MOS, jitter, and packet loss. This data is invaluable for troubleshooting voice integrations and proactively identifying quality issues.
Also Read: How Programmable SIP Enables Scalable AI-Driven Voice Experiences?
Conclusion
Building voice bots that deliver a truly exceptional customer experience is a journey that begins with a relentless focus on call quality. The intelligence of your AI is a fragile thing, and it can be completely undermined by a poor audio foundation.
By moving beyond subjective assessments and embracing a data-driven approach based on a clear set of objective and subjective metrics, you can systematically measure, diagnose, and optimize every aspect of your voice application’s performance.
By understanding and monitoring the key call clarity benchmarks, from network health metrics like latency and jitter to the all-important stt accuracy scoring, you can ensure that your voice bot is not just smart, but that it is always listening with perfect clarity.
Want a personalized walkthrough of our analytics dashboard and a deep dive into how we measure and maintain our call quality standards? Schedule a demo for FreJun Teler.
Also Read: 5 Best Autodialer Software in 2025: Top Platforms, Features, Pricing & Reviews
Frequently Asked Questions (FAQs)
While all are important, the Mean Opinion Score (MOS) is often considered the most holistic metric. It is a single number (from 1 to 5) that represents the overall perceived quality of the call, taking into account the combined effects of latency, jitter, packet loss, and the codec.
A mos voice quality measurement of 4.0 or higher is generally considered to be high-quality, or “toll-quality,” and is a good target when building voice bots. Anything below 3.5 will likely be perceived as noticeably degraded.
PESQ objectively compares original and received audio, while MOS reflects perceived quality; PESQ suits automated lab testing.
Word Error Rate (WER) is a measure of the accuracy of your Speech-to-Text (STT) engine. A high WER means the AI is “mishearing” the user, which is the root cause of most conversational failures. Accurate stt accuracy scoring is essential for diagnosing AI performance issues.
Yes. You could have a crystal-clear audio connection (a high MOS), but if your STT engine is not well-tuned for your users’ accents or your industry’s specific jargon, it could still have a high Word Error Rate (WER), causing the bot to misunderstand the user.
The single biggest cause of latency is the physical distance the data packets have to travel over the internet. This is why using a voice provider with a globally distributed, edge-native network is so critical.
Network congestion causes packet loss; prioritize voice traffic with QoS and use providers with intelligent routing.