
We are living in the age of the intelligent agent. From the AI that books your appointments to the virtual assistant that answers your banking questions, conversational AI is becoming a seamless part of our digital lives. As developers and product leaders, we are often mesmerized by the “brain” of these agents, the powerful Large Language Models (LLMs) that provide the spark of intelligence.
But there is a hidden, equally complex, and arguably more critical layer that makes it all possible: the voice infrastructure. At the heart of this infrastructure, acting as the crucial bridge between your application and the real-time world of audio, is the voice calling SDK.
To the end-user, a voice conversation feels simple and ephemeral. To the developer building it, it is a high-speed, high-stakes symphony of data. A single spoken sentence must be captured, transported, transcribed, understood, responded to, synthesized, and returned, all in less than a second.
The voice calling SDK is the conductor of this symphony. It is the invisible but indispensable layer that handles the immense complexity of the AI voice transport layer, allowing developers to focus on the intelligence of their agent, not the plumbing behind it.
Table of contents
What is the Fundamental Challenge of Real-Time Voice?
Before we can understand the role of an SDK, we must first appreciate the monumental challenge it is designed to solve. A real-time voice call is one of the most demanding applications on the internet. Unlike browsing a webpage or downloading a file, it has zero tolerance for delay or error.
The Tyranny of Real-Time
The core of the problem is the need for real-time media streaming.
- Packet-Based Audio: A human voice is an analog wave. To send it over the internet, it must be digitized, broken up into thousands of tiny data packets, and sent one by one.
- The Unforgiving Timeline: These packets must be reassembled at the other end in the correct order and with precise timing. If packets are lost (packet loss) or arrive in an uneven, spiky pattern (jitter), the audio becomes garbled and incomprehensible.
- The Latency Barrier: The entire round-trip journey for these packets must be incredibly fast. Any significant delay (latency) makes a natural, two-way conversation impossible.
The Complexity of the Backend Voice Architecture
Behind this real-time stream is a deeply complex backend voice architecture. This includes:
- Signaling Protocols (like SIP): The language used to set up, manage, and tear down the call.
- Media Protocols (like RTP): The rules for transporting the actual audio packets.
- Carrier Interconnects: The physical and digital connections to the global Public Switched Telephone Network (PSTN).
- Global Infrastructure: The network of servers (Points of Presence) needed to handle calls with low latency around the world.
Attempting to manage this complexity from scratch is a multi-year, multi-million dollar undertaking that is far outside the core competency of most businesses. This is the problem that a modern voice infrastructure platform, and its associated voice calling SDK, is built to solve.
Also Read: From Chatbots to Callbots: How the Best Voice APIs Are Redefining Business Communication
What is a Voice Calling SDK and What Does It Actually Do?
An SDK, or Software Development Kit, is a set of tools, libraries, and documentation that a platform provides to make it easier for developers to build applications on top of that platform. A voice calling SDK is a specialized SDK that is designed to abstract away the immense complexity of the underlying voice infrastructure explained above.

Think of it this way: if the voice platform’s global network is a complex and powerful engine, the voice calling SDK is the clean, simple, and well-designed dashboard that allows you to drive it. You do not need to be a master mechanic to turn the key and press the accelerator. The SDK’s primary jobs are to:
- Manage the Connection: It handles the secure and reliable connection from your application to the voice platform’s nearest edge server.
- Handle Media Processing: It captures the audio from the microphone, digitizes it, packetizes it, and handles the real-time media streaming to the platform. It does the same in reverse for the incoming audio.
- Provide a High-Level API: It exposes a simple set of functions for the developer, like connectCall(), sendAudio(), and disconnectCall(), that translate into complex, low-level signaling and media operations.
- Emit Real-Time Events: It listens for events from the platform like “call connected,” “incoming audio received,” or “call disconnected”, and communicates them to your application so it can react accordingly.
This table provides a clear breakdown of what is handled by the SDK versus what the developer is responsible for.
| Task | Handled by the Voice Calling SDK & Platform | Handled by the Developer’s Application |
| Low-Level Signaling (SIP) | YES | NO |
| Real-Time Media Transport (RTP) | YES | NO |
| Audio Encoding/Decoding (Codecs) | YES | NO |
| Network Jitter Buffering | YES | NO |
| Calling the High-Level Functions (e.g., connectCall()) | NO | YES |
| Handling the Application’s Logic | NO | YES |
| Building the AI’s “Brain” (LLM, etc.) | NO | YES |
Also Read: The Role of Elastic SIP Trunking in Building Real-Time Voice Applications
How Does a Voice Calling SDK Enable the AI Voice Transport Layer?
The voice calling SDK is the first and last link in the AI voice transport layer. It is the component that lives inside your application and acts as the on-ramp and off-ramp for the audio data. Let’s follow the journey of a single conversational turn to see how it all fits together:
- The User Speaks: The SDK, running in your application, captures the audio from the user’s microphone.
- SDK Sends Audio: The SDK handles the complex job of streaming these audio packets securely and efficiently to the nearest edge server of the voice infrastructure platform (like FreJun AI’s Teler engine).
- The Backend Does Its Magic: The backend voice architecture takes over. The platform’s servers receive the audio stream and, as orchestrated by your application’s logic, forward it to your AI’s “brain” (your AgentKit) for STT, LLM, and TTS processing.
- SDK Receives Audio: The platform’s servers stream the AI’s synthesized audio response back to the SDK.
- The User Hears the Response: The SDK receives these audio packets, decodes them, and plays them through the user’s speaker.
This entire round trip happens in a fraction of a second. The SDK’s role in optimizing the real-time media streaming and minimizing the processing time on the device is absolutely critical. It helps in achieving the low latency that a natural conversation demands.
A recent Google report on the performance of real-time communication applications found that optimizing the client-side media pipeline can reduce end-to-end latency by as much as 30%, highlighting the critical role of the SDK.
Ready to see how a powerful and easy-to-use SDK can accelerate your voice AI development? Sign up for FreJun AI and explore our SDKs for your favorite platforms.
What Should You Look for in a Modern Voice Calling SDK?
Not all SDKs are created equal. The quality of a voice calling SDK can be the difference between a smooth, rapid development process and a frustrating, bug-filled nightmare. The best SDKs are designed with the developer’s experience as the absolute top priority. The key features to look for include:
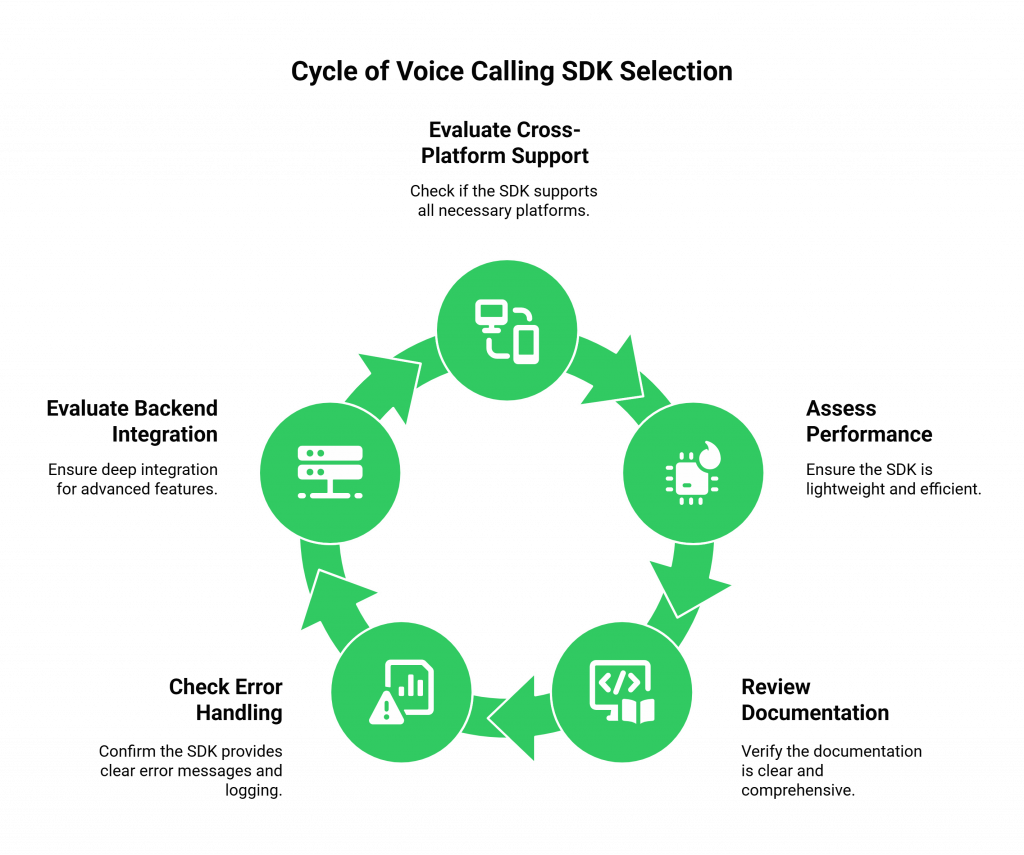
- Cross-Platform Support: It should be available for all the platforms you need to support: web (JavaScript), mobile (iOS/Swift, Android/Kotlin), and server-side (Python, Java, etc.).
- Lightweight and Performant: The SDK should have a minimal footprint and be highly optimized to consume as little CPU and battery as possible, especially on mobile devices.
- Clear and Comprehensive Documentation: The documentation should be excellent, with clear guides, detailed API references, and ready-to-use code samples for common use cases.
- Robust Error Handling and Logging: When things go wrong, the SDK should provide clear, actionable error messages and have powerful logging capabilities to make debugging easy.
- Deep Integration with the Backend: The SDK should be more than just a thin wrapper. It should be deeply integrated with the backend voice architecture to provide advanced features like real-time call quality metrics and adaptive codec selection.
Also Read: Why a Unified Voice API Matters for Scalable Business Communication?
Conclusion
The intelligence of an AI voice agent may live in the cloud, but the experience of that agent lives on the client. The voice calling SDK is the critical, invisible layer that governs that experience. It is the sophisticated software that tames the wild, unpredictable world of real-time audio, transforming it into a clean, reliable data stream that your application can work with.
For developers building voice AI with SIP, the SDK is your most important tool. It is the ultimate abstraction, the component that handles the immense complexity of the voice infrastructure explained so that you can focus on the part that truly matters: creating a voice agent that is not just intelligent, but also a pleasure to talk to.
Want to do a deep dive into our SDKs and see how they can simplify your voice AI application’s architecture? Schedule a demo for FreJun Teler.
Also Read: Telephone Call Logging Software: Keep Every Conversation Organized
Frequently Asked Questions (FAQs)
A voice calling SDK (Software Development Kit) is a set of software libraries and tools that allows a developer to easily add real-time voice communication features (like making and receiving calls) directly into their own applications (web, mobile, or desktop).
While you could theoretically handle the raw media streaming yourself, it is an incredibly complex task. The SDK abstracts away this complexity, handling all the low-level real-time media streaming protocols, audio processing, and connection management for you.
The AI voice transport layer is the complete, end-to-end path that the voice data travels in an AI conversation. It starts with the SDK capturing audio, goes through the voice platform’s network to the AI for processing. Then comes all the way back to the SDK to be played to the user.
A well-designed SDK is highly optimized. It uses efficient audio codecs, manages a jitter buffer to smooth out network inconsistencies, and maintains a persistent, low-latency connection to the nearest server in the backend voice architecture, all of which help to minimize delay.
A client-side SDK is designed to run in the user’s application (e.g., in a web browser or on a mobile phone) and primarily deals with capturing and playing audio. A server-side SDK is designed to run in your backend application. It is used to control the call flow, make outbound calls, and manage the overall voice infrastructure explained.
Typically, the setup involves installing the SDK library into your project, initializing it with your API credentials from the provider, and then using its simple functions to establish a connection and start a call.
No. The SDK requires a stable internet connection (Wi-Fi or cellular data) to communicate with the voice platform’s servers and to handle the real-time media streaming.