
In the world of conversational AI, there is a razor-thin line between a magical interaction and a frustrating one. That line is measured in milliseconds. When a user speaks to an AI voice agent and gets an immediate, natural response, the experience feels seamless and intelligent.
But when there is a one or two-second pause of dead air, the dreaded sound of latency, the illusion shatters. The agent suddenly feels slow, robotic, and unintelligent.
For developers and businesses building the next generation of voice AI, winning the battle against latency is not just a technical goal; it is the single most important factor in creating a successful user experience.
The foundation for this low-latency future is not found in the AI models alone, but in the underlying communication infrastructure. It is a powerful synergy between a modern, developer-first elastic SIP trunking platform and a new class of tools: Real-Time Media APIs.
This combination is what finally allows developers to bridge the gap between the raw, analog world of a phone call and the digital brain of an AI in a truly instantaneous way.
This article will dive deep into the architecture and workflows required to build these high-performance, low-latency voice agents.
Table of contents
Why is Latency the Arch-Nemesis of Conversational AI?
Latency, in its simplest form, is the delay between a cause and its effect. In a voice AI conversation, it is the total time from the moment a user stops speaking to the moment they hear the AI’s response. This delay is not a single event but the sum of several distinct processing and travel times. Understanding this “anatomy of latency” is the key to defeating it.
The total latency in a voice AI round-trip is composed of:
- Network Latency: The time it takes for audio packets to travel from the user’s phone, across the internet to the servers, and back again. This is largely a factor of physical distance.
- STT (Speech-to-Text) Latency: The time it takes for the STT engine to receive the audio and transcribe it into text.
- LLM (Large Language Model) Latency: The time it takes for the AI brain to process the text, understand the intent, decide on a response, and generate the response text. This is often the most variable component.
- TTS (Text-to-Speech) Latency: The time it takes for the TTS engine to synthesize the response text into audible speech.
While developers are constantly working to optimize the AI models themselves, the single biggest and most controllable factor is network latency. The architectural choices you make in your voice infrastructure have a direct and profound impact on this critical number. The demand for instant, conversational support is a powerful driver of this technology.
A recent study by HubSpot found that 90% of customers rate an “immediate” response as important or very important when they have a customer service question. An AI that feels slow is failing this fundamental expectation.
Also Read: How to Handle Last-Minute Bookings via AI Calls?
How Does Traditional Elastic SIP Trunking Fall Short?
The first generation of elastic SIP trunking was a revolution for human-to-human communication, but it was not designed for the demands of real-time AI. The traditional model was built around a simple premise: connect a call from the public telephone network and terminate it to a private phone system, like an on-premise or cloud-based PBX.
The Problem of the “Hidden” Media Stream
The fundamental flaw in this old model for AI is that it hides the media. The SIP trunk provider’s job was simply to deliver the call to the PBX. The PBX would then handle the audio. For a developer building an AI agent, this is a major roadblock.
They need to get their hands on the raw, real-time audio stream (the RTP packets) to send it to their AI’s “ears” (the STT engine).
In the traditional model, getting access to this stream required a complex, often-unreliable process of trying to fork the media from within the PBX itself, creating an extra, slow “hop” in the data path and adding significant latency.
This table clearly illustrates the architectural differences between the old and new worlds.
| Characteristic | Traditional Elastic SIP Trunking | AI-Optimized Elastic SIP Trunking |
| Primary Function | Terminate calls to a PBX. | Provide programmable access to real-time media. |
| Media Access | The media stream is “owned” by the PBX; difficult to access. | The media stream is exposed via a real-time API. |
| Architecture | Centralized; designed for call routing. | Globally distributed (edge-based); designed for low-latency data streaming. |
| Primary User | IT Administrator configuring a phone system. | Software Developer building an application. |
| Workflow | Static and pre-configured. | Dynamic and controlled by code in real-time. |
What is a Real-Time Media API and How Does It Change the Game?
A Real-Time Media API is the evolutionary leap that makes modern, low-latency voice AI possible. It is a set of developer tools that fundamentally changes the role of the elastic SIP trunking provider. Instead of just being a passive pipe that delivers a call, the provider becomes an active, programmable participant in your application’s workflow.
The core capability of a Real-Time Media API is the ability to programmatically “fork” the media stream. This means you can instruct the provider, via an API, to create a perfect, real-time copy of the call’s audio and stream it directly to an endpoint of your choosing, for example, your AI application’s server.
This is a game-changer. It completely bypasses the need for a traditional PBX in the AI workflow, eliminating an entire step and creating the shortest, fastest possible path from the live call to your AI’s brain.
This is the foundation of FreJun AI’s architecture. Our Teler is not just an elastic SIP trunking provider; it is a fully programmable, real-time media server.
Ready to get your hands on the real-time audio stream and start building truly conversational agents? Sign up for FreJun AI.
Also Read: Voice AI For Emergency Response Centers
How Do These Components Work Together to Build a Low-Latency Agent?
By combining a globally distributed elastic SIP trunking infrastructure with a powerful Real-Time Media API, you can construct a workflow that is optimized for speed at every step. The growth of this market is a testament to its power; the global CPaaS (Communication Platform as a Service) market, which is built on these principles, is expected to reach over $45 billion by 2027.
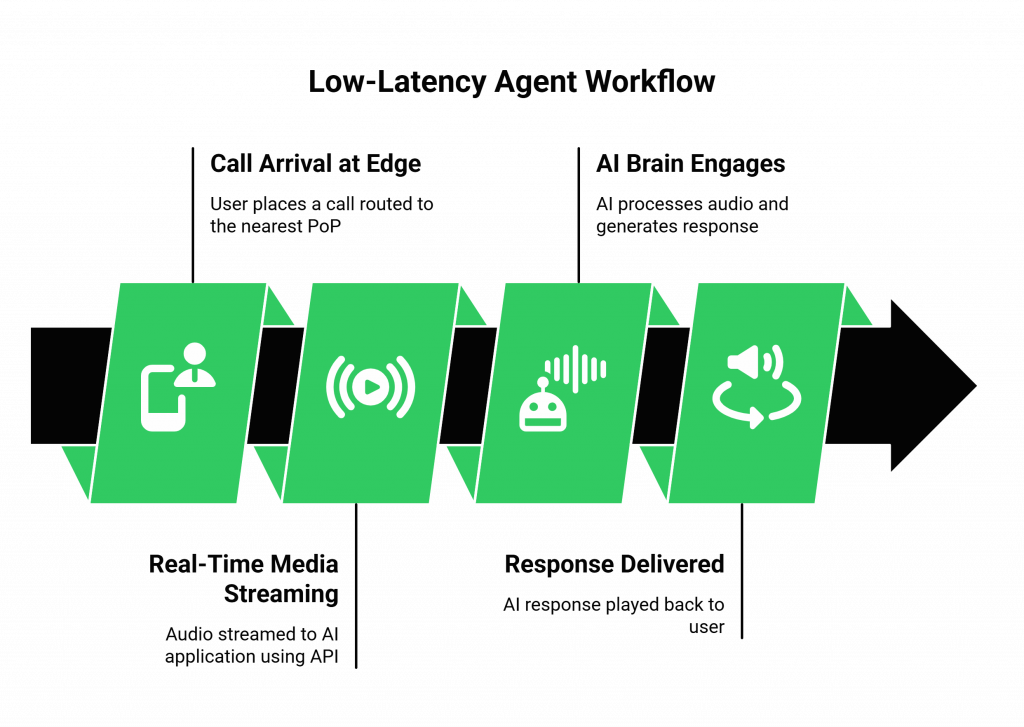
Here is a step-by-step look at the data flow of a single, low-latency conversational turn:
- Call Arrival at the Edge: A user places a call. It is routed to the nearest edge Point of Presence (PoP) of the FreJun AI Teler engine. Handling the call close to the user is the first and most important step in minimizing network latency.
- Real-Time Media Streaming: As soon as the user starts speaking, your application, using our Real-Time Media API, has already instructed Teler to begin forking the audio. Teler streams the raw RTP packets directly to your AI application (your AgentKit).
- The AI “Brain” Engages: Your AgentKit’s STT engine transcribes the audio, the LLM processes the intent and generates a text response, and the TTS engine synthesizes this text back into a new audio stream. Because this is happening in parallel with the call, the process begins the instant the first audio packets arrive.
- The Response is Delivered: Your AgentKit sends this newly generated audio back to Teler via the API with a command to “play audio.” Teler immediately plays this audio back to the user on the live call.
This direct, API-driven path is the key. It eliminates all unnecessary middlemen and ensures that the data travels the shortest possible distance, resulting in a conversation that feels immediate and natural. This is the core of our philosophy: “We handle the complex voice infrastructure so you can focus on building your AI.”
Also Read: Step-by-Step Guide to Building Voice-Enabled AI Agents Using Teler and OpenAI’s AgentKit
Conclusion
The pursuit of truly human-like conversational AI is a relentless battle against latency. The magic of a seamless voice agent is not just in the intelligence of its LLM, but in the speed and efficiency of the infrastructure that connects it to the world.
Traditional elastic SIP trunking was the first step in liberating voice from the world of hardware, but it was not the final destination. The true revolution is happening now, with the fusion of this elastic connectivity and the power of Real-Time Media APIs.
This powerful combination gives developers the direct, programmable control they need to build the next generation of low-latency voice agents, finally allowing the brilliance of AI to be heard without delay.
Want to do a technical deep dive into our Real-Time Media API and architect a low-latency solution for your specific use case? Schedule a demo for FreJun Teler.
Also Read: UK Mobile Code Guide for International Callers
Frequently Asked Questions (FAQs)
Latency is the total delay from the moment a user finishes speaking to the moment they hear the AI’s response. It is the “pause” in the conversation, and minimizing it is critical for a natural user experience.
It is a set of developer tools that allows you to programmatically access and control the raw audio stream (the media) of a live phone call in real-time. This is essential for connecting a call to an AI.
This is the core function of a Real-Time Media API. It is the ability to create a live, real-time copy of the call’s audio and send it to a specified destination (like your AI application’s server) while the call is in progress.
It is the most effective way to reduce network latency. By handling a call at a data center that is physically closer to the end-user, the data has a shorter distance to travel, which directly translates to a faster and more responsive conversation.
A traditional provider focuses on terminating a call to a PBX. An AI-optimized provider, like FreJun AI, focuses on giving developers programmable, API-driven access to the real-time media stream of the call.
No. A modern, developer-first platform abstracts away the low-level telecom complexity. A software developer can use a high-level API to control the call’s media without needing to be an expert in the underlying SIP and RTP protocols.
Yes. A key benefit of this architecture is being model-agnostic. The job of the elastic SIP trunking and Real-Time Media API is to get the audio to and from your application. You have complete freedom to use whichever AI models you choose in your application.
Absolutely. A production-grade platform must use the Secure Real-time Transport Protocol (SRTP) to encrypt the media stream. It ensure that the voice conversation is protect and confidential.
FreJun AI provides the foundational elastic SIP trunking infrastructure (our Teler engine) and the powerful Real-Time Media API. We provide the secure, reliable, and low-latency “plumbing”. It allows you to connect your AI applications to the global telephone network.