
For the last few years, the world of AI has been a world of text. We’ve built chatbots that can write poetry and answer complex questions, all through a silent, text-based interface. We then gave these AIs a voice, allowing them to speak and listen. But in both cases, the AI remained fundamentally blind and disconnected from our visual world. It could hear our problems, but it could never see them.
That era is now coming to a rapid close. We are on the cusp of the next great leap in artificial intelligence: the rise of the multimodal AI agents. “Multimodal” simply means the AI can perceive and understand the world through multiple “modes” of data, sight, sound, and text, all at the same time, just like a human.
This isn’t a far-off, futuristic concept. The tools and frameworks to begin building AI agents with multimodal models are here today. And by next year, they will be at the heart of the most advanced digital experiences.
The era of multimodal AI agents 2025 is about creating assistants that don’t just process information but perceive reality. This guide is for the developers and builders who want to get ahead of the curve and understand the practical tools needed to build this future.
Table of contents
Why are Multimodal AI Agents the Next Major Leap in AI?
A single-modal AI, like a traditional voicebot, is like having a conversation on a phone call. It’s useful, but you’re missing a huge amount of context. A multimodal AI is like upgrading to a high-definition video call with a super-smart expert who can see what you’re seeing. This shift from a “phone call” to a “video call” with AI unlocks a new dimension of problem-solving.
This isn’t just a niche improvement; it’s a fundamental driver of the next wave of AI adoption. A recent report from IBM revealed that 42% of enterprise-scale companies have already actively deployed AI, and multimodal capabilities are the next frontier for expanding these deployments into more complex, real-world scenarios.
- Solving Physical World Problems: Many of the most challenging support issues are visual. A multimodal agent can look at a picture of a broken part, read an error message from a photo of a screen, or guide a user through a physical assembly process.
- Creating Radically Intuitive Interfaces: Multimodal interaction is how humans naturally operate. It removes the need for users to tediously describe a visual problem, creating an experience that is faster, less frustrating, and more accessible.
- Achieving a Deeper Level of Understanding: When an AI can correlate what a user is saying with what they are looking at, it gains a profound level of contextual understanding that leads to far more accurate and helpful responses.
Also Read: How To Enable Multilingual Voice Agents With Teler?
What Are the Core “Senses” of a Multimodal Agent?
To build one of these advanced agents, you need to assemble a set of digital “senses” that can perceive and interpret world.
- Sight (Computer Vision): This is the AI’s ability to see, using a computer vision model to analyze a live video stream or a static image.
- Hearing & Speech (Voice I/O): This is the AI’s ability to have a conversation, using Speech-to-Text (STT) to listen and Text-to-Speech (TTS) to speak. This real-time audio channel is the backbone of the interactive experience.
- Thinking & Reasoning (The Multimodal LLM): This is the central “brain.” The true breakthrough is the development of native multimodal models like Google’s Gemini and OpenAI’s GPT-4o, which can accept and reason about different types of data (e.g., an image and a text prompt) in a single step.
What Are the Essential Tools and Frameworks for Building in 2025?
Building AI agents with multimodal models requires a modern, API-driven development stack. Here are the key tools and frameworks you need to know.
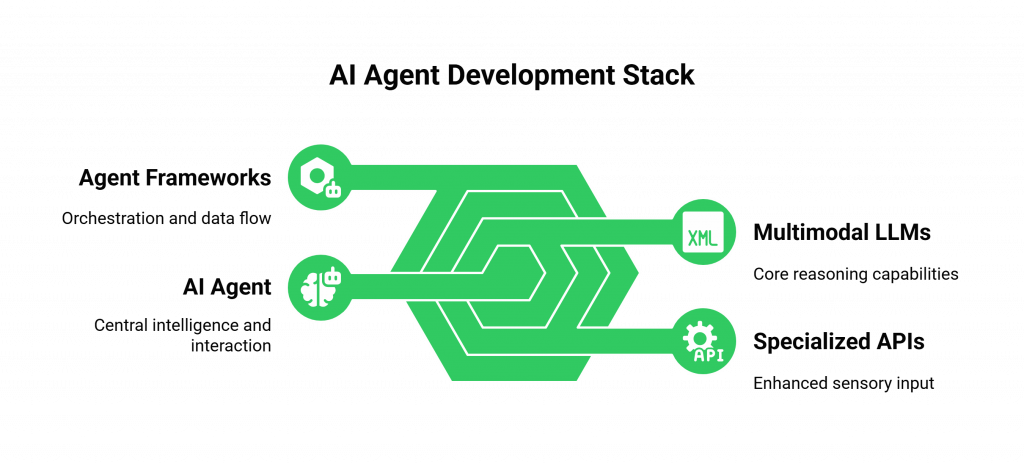
The “Brain”: The Multimodal LLM Providers
This is the core of your agent’s intelligence. Your choice of LLM will define its reasoning capabilities.
- OpenAI’s GPT-4o: A flagship model known for its state-of-the-art performance in understanding both text and images.
- Google’s Gemini Family: Gemini was designed from ground up to be natively multimodal, making it a powerful and flexible choice.
- Open-Source Alternatives: Models like LLaVA (Large Language and Vision Assistant) are rapidly advancing, offering a self-hostable option for businesses that need maximum data privacy.
Also Read: How To Scale Voice Agents For Millions Of Calls?
The “Senses”: The Specialized APIs
While a multimodal LLM is the brain, you often still need specialized APIs for the best possible sensory input.
- Vision APIs: For advanced tasks like Optical Character Recognition (OCR) or specific object detection, dedicated services like Google Vision AI or Amazon Rekognition can sometimes outperform the general vision capabilities of an LLM.
- Voice Infrastructure: This is arguably the most critical component for a real-time multimodal conversation. The LLM’s brain might be fast, but the conversation will feel slow if the “nervous system” is laggy. This is where a specialized voice infrastructure platform like FreJun AI is essential. We are not an LLM provider; we provide the ultra-low-latency, real-time “auditory nerve.” Our platform is engineered to handle the high-speed, bidirectional streaming of audio required to make a complex multimodal interaction feel instant and natural.
The “Orchestrator”: The Agent Frameworks
How do you connect the brain to all these different senses and tools? This is the job of an orchestration framework.
- LangChain & LlamaIndex: These open-source frameworks are the “glue” for the modern AI stack. They provide a standardized way to build complex chains and sequences of calls to different models and APIs. They help you manage the flow of data, from the STT transcript and the video frame to the LLM, and then out to the TTS.
Ready to build the future of AI interaction? Sign up for FreJun AI’s real-time voice infrastructure for your multimodal project.
Also Read: How To Integrate Tool Calling Into Voice Conversations?
What Does a Real-World Multimodal Workflow Look Like?
Let’s make this concrete with a practical “visual support” example:
- A user starts a session on your mobile app, which activates their camera and microphone.
- FreJun AI’s infrastructure establishes the real-time audio stream.
- The user points their camera at a router and says, “This red light is blinking. What does that mean?”
- Your backend application captures a frame from the video stream and, simultaneously, uses a streaming STT to transcribe the user’s question.
- Your application, likely using a framework like LangChain, sends both the image of the blinking red light and the text “This red light is blinking. What does that mean?” to the multimodal LLM’s API in a single call.
- The LLM analyzes both inputs, understands the context, and generates a text response: “A blinking red light on that model of router indicates a failed internet connection. I recommend unplugging it for 30 seconds and then plugging it back in.”
- This text is sent to a TTS engine.
- FreJun AI streams the resulting audio back to the user’s device.
This entire loop happens in about a second, creating a seamless, problem-solving experience.
Conclusion
We are at a pivotal moment in the history of human-computer interaction. The blind and deaf AI of the past is evolving into a perceptive, aware partner. The era of multimodal AI agents 2025 will be defined by these rich, multisensory experiences that can solve real-world problems in a way that feels completely intuitive.
The global generative AI market is projected to explode to over $1.3 trillion by 2032, and these powerful, problem-solving agents will be a primary driver of that value.
Building AI agents with multimodal models requires a new way of thinking and a modern development stack. It’s about combining a powerful multimodal brain with best-in-class sensory APIs and, most importantly, a high-performance infrastructure to connect them all in real-time.
Want to learn more about the voice component of the next generation of AI? Schedule a demo with FreJun AI today.
Also Read: How Automated Phone Calls Work: From IVR to AI-Powered Conversations
Frequently Asked Questions (FAQs)
Multimodal AI agents are a type of artificial intelligence that can process and understand information from multiple types of data, or “modalities” at the same time. This includes text, images, video, and voice, allowing for a much richer and more contextual understanding of the world.
A regular voicebot is single-modal; it can only process audio and text. A multimodal agent can, for example, see an object in a video stream while simultaneously listening to a user’s question about that object, and use both pieces of information to form its answer.
A native multimodal LLM, such as OpenAI’s GPT-4o or Google’s Gemini, is built to handle multiple input types naturally. It accepts text, images, audio, and more in a unified way, instead of using separate models joined together for each sense.
The biggest challenges are latency, data synchronization, and cost. You need to process multiple real-time data streams (like video and audio) and ensure they are perfectly synced and delivered to the AI models with extremely low delay. Processing video is also more computationally expensive than text or audio.
LangChain is a popular open-source framework that helps developers build applications with Large Language Models. It provides tools and a standardized structure for “chaining” together calls to different LLMs, APIs, and data sources, which is essential for orchestrating complex multimodal workflows.
The best use cases are those that involve solving problems in the physical world. This includes remote technical support, visual product identification for e-commerce, interactive “how-to” guides for assembly or repairs, and immersive training simulations.
Yes. There are several powerful open-source multimodal models, with LLaVA (Large Language and Vision Assistant) being one of the most popular. This is a great option for businesses that require a self-hosted solution for maximum data privacy.
While some multimodal models now support native audio input and output, specialized models still perform better. For the best quality and lowest latency, use top-tier STT and TTS systems. These are optimized for real-time streaming and remain the recommended choice for production setups.
In a multimodal system that involves voice, FreJun AI provides the essential voice infrastructure. It handles the complex task of capturing the user’s speech from their device and delivering the AI’s spoken response back, all with the ultra-low latency required for a natural, real-time conversation.
By 2025, multimodal AI agents will be more proactive and autonomous. They will have better memory for visuals and conversations. They will understand and generate video, not just static images.