
Voice AI projects succeed or fail based on architectural clarity. In 2025, developers are faced with two equally powerful but fundamentally different tools: Vapi.ai and AssemblyAI. One is designed to act in real time, the other to analyse deeply.
The risk is not picking the weaker option, but picking the wrong one for your problem. This guide unpacks their distinct strengths and shows how FreJun provides the connective tissue to unify both, enabling developers to build voice systems without compromise.
Table of contents
- Building the ‘Ear’ vs. the ‘Mouth’: A Critical Choice for Voice AI Developers
- The Foundational Error: Confusing Voice Action with Voice Analysis
- An Overview of Vapi.ai: The Voice Action Platform
- An Overview of AssemblyAI.com: The Speech Intelligence Engine
- The Connection Layer: How FreJun Unifies the AI Voice Stack
- Core Capabilities: Vapi.ai Vs Assemblyai.com
- Architectural Decision: A Custom Stack with FreJun vs. DIY Infrastructure
- A Developer’s Guide: Choosing Between Active vs. Passive Voice AI
- Final Thoughts: Your Project’s Success Hinges on the Right Tool for the Job
- Frequently Asked Questions
Building the ‘Ear’ vs. the ‘Mouth’: A Critical Choice for Voice AI Developers
For developers embarking on a new AI voice project in 2025, the landscape of available tools is both powerful and perplexing. Two names that frequently appear are Vapi.ai and AssemblyAI.com, both leaders in the voice AI space.
However, choosing between them is not a simple matter of preference; it’s a fundamental architectural decision. It’s akin to deciding whether your application needs a highly advanced ‘ear’ to listen and understand, or a sophisticated ‘mouth’ to speak and interact.
Mistaking one for the other can lead to building a system that is fundamentally misaligned with your project’s goals.
The Foundational Error: Confusing Voice Action with Voice Analysis
The most common mistake developers make is failing to distinguish between platforms designed for voice action and those designed for voice analysis. This isn’t just a difference in features; it’s a difference in purpose.
- Voice Action Platforms like Vapi.ai are built to do things. They are the engines that power real-time, interactive conversations. They manage telephony, route calls, and enable AI agents to speak and respond to users, driving a process forward. Their primary metric is the quality and efficiency of the interaction itself.
- Voice Analysis Platforms like AssemblyAI are built to understand things. They are the brains that process audio, transcribe it with high accuracy, and extract meaningful insights. They identify speakers, detect sentiment, and summarise content. Their primary metric is the accuracy and depth of the data extracted from speech.
Choosing an analysis platform when you need to build an interactive phone agent will leave you without the critical telephony infrastructure. Conversely, choosing an action platform when you need deep audio analytics will provide a lot of functionality you don’t need while lacking the specialised intelligence required for your task. The Vapi.ai Vs Assemblyai.com debate is the perfect illustration of this critical distinction.
An Overview of Vapi.ai: The Voice Action Platform
Vapi.ai is a developer-first API platform architected for one primary purpose: to build and deploy AI-powered voice agents that can interact with humans in real time, primarily over the phone. Its core strength is not in understanding audio in post-processing, but in managing the live, back-and-forth flow of a conversation.
Think of Vapi.ai as the complete operational toolkit for an AI call center agent. It handles the complex and often messy world of telephony, call initiation, routing, concurrency, and maintaining a stable connection so developers can focus on the agent’s conversational logic.
Core Strengths of Vapi.ai
- Real-time Interaction: The platform is optimized for low-latency conversations, ensuring that the pauses between a user speaking and an AI responding feel natural.
- Telephony Infrastructure: Vapi.ai manages the end-to-end call lifecycle, from connecting to the PSTN (Public Switched Telephone Network) to handling voicemail and intelligent call routing.
- Enterprise-Ready: It’s built with reliability and scalability in mind, making it suitable for deploying customer-facing voice bots that can handle significant call volumes with global compliance.
- Primary Use Cases: Its ideal applications include interactive customer service bots, automated sales outreach agents, and intelligent appointment schedulers that replace or augment human agents. This focus on building interactive agents is a common theme among modern conversational AI frameworks.
An Overview of AssemblyAI.com: The Speech Intelligence Engine
AssemblyAI operates on the other side of the voice AI coin. Its platform is a suite of powerful APIs dedicated to transcribing and understanding spoken audio. It is a world-class “ear” that can listen to audio files or real-time streams and convert them into structured, actionable data.
While Vapi.ai is concerned with the conversational exchange, AssemblyAI is focused on extracting every last drop of intelligence from the audio content itself.
Core Strengths of AssemblyAI.com
- Advanced Speech-to-Text (ASR): AssemblyAI is renowned for its highly accurate transcription models, which can handle noisy environments and support over 30 languages. The accuracy of the underlying ASR is a critical factor when comparing speech technology providers.
- Speech Intelligence: Beyond simple transcription, it offers a rich set of features like speaker diarization (who spoke when), sentiment analysis, topic detection, and summarization.
- Data Extraction: Its APIs can perform entity detection to identify names, locations, and other critical pieces of information mentioned in the audio.
- Primary Use Cases: It’s the perfect tool for developers building media monitoring platforms, call analytics dashboards, applications that require accurate transcription, or any system that needs to derive insights from recorded or streaming speech.
The discussion of Vapi.ai Vs Assemblyai.com is fundamentally about action versus insight.
The Connection Layer: How FreJun Unifies the AI Voice Stack
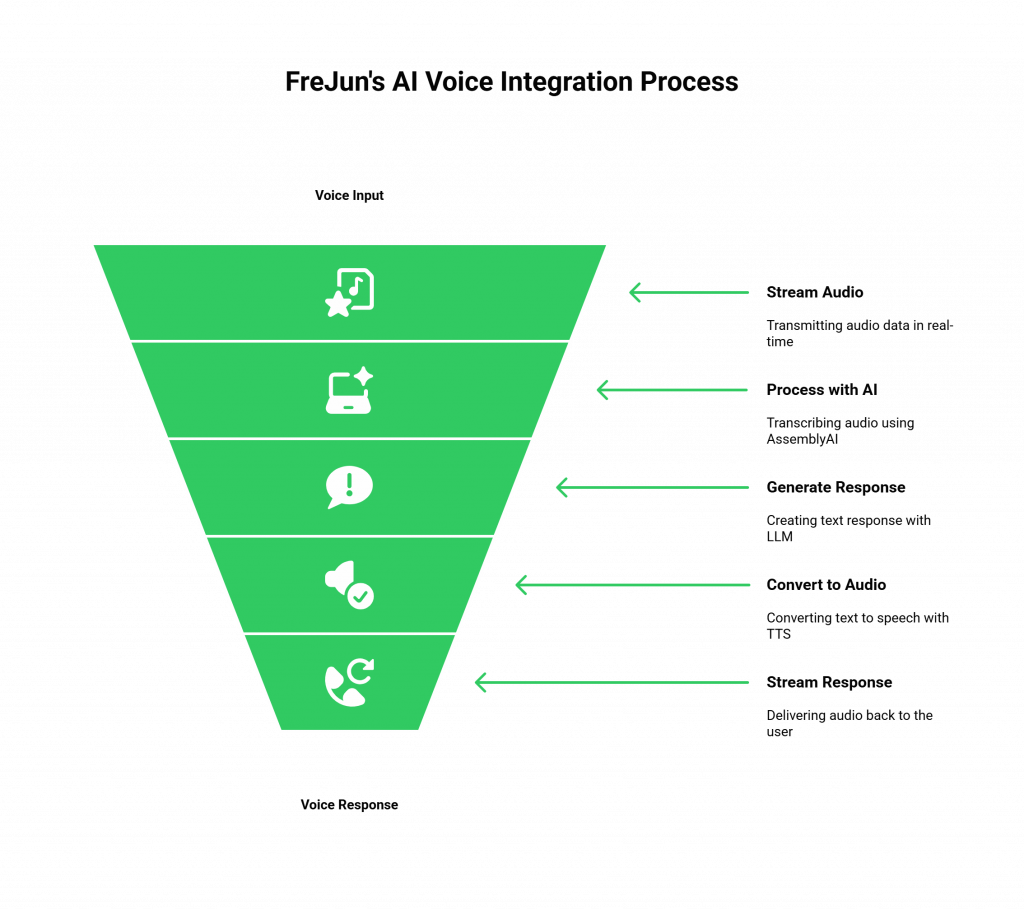
So, where does that leave developers who need both? What if you want to build an interactive phone agent (like Vapi.ai) that uses a best-in-class transcription engine (like AssemblyAI) and a custom language model? This is where the architecture becomes critical, and where a foundational layer like FreJun provides the solution.
FreJun is not another all-in-one platform. It is a specialized voice transport layer that provides the robust telephony infrastructure needed to connect the real world to your AI stack.
FreJun allows you to:
- Stream Voice Input: It captures low-latency audio from any inbound or outbound phone call.
- Process with Your AI: You can then pipe that raw audio stream directly to AssemblyAI for transcription.
- Generate a Response: Take the text from AssemblyAI, send it to your Large Language Model (LLM) for a response, and then use a Text-to-Speech (TTS) service to generate audio.
- Stream Voice Response: Pipe the generated audio back through FreJun’s API, which plays it back to the user over the call with minimal delay.
FreJun is the model-agnostic “plumbing” that lets you choose the best “ear” (AssemblyAI), “brain” (your LLM), and “mouth” (your TTS) and connect them seamlessly to the global phone network. This approach offers ultimate control and flexibility.
Core Capabilities: Vapi.ai Vs Assemblyai.com
This table provides a clear, at-a-glance breakdown to solidify the distinction between the two platforms. This direct comparison of Vapi.ai Vs Assemblyai.com highlights their complementary, rather than competing, roles.
| Feature / Aspect | Vapi.ai | AssemblyAI.com |
| Core Function | Voice Action & Interaction | Voice Analysis & Intelligence |
| Primary API Offering | AI voice agent deployment & call management | Speech-to-text (ASR) & speech understanding |
| Focus | Real-time, interactive, output-driven | Asynchronous or streaming, input-driven |
| Key Features | Telephony integration, call routing, live agents | Transcription, speaker diarization, sentiment analysis |
| Ideal Project | Building an AI receptionist or sales bot | Building a call analytics dashboard or media transcriber |
| Measures of Success | Conversational flow, task completion rate | Transcription accuracy, depth of insights |
| Analogy | The ‘Mouth’ and ‘Hands’ of the operation | The ‘Ear’ and ‘Brain’ of the operation |
Architectural Decision: A Custom Stack with FreJun vs. DIY Infrastructure
For teams requiring a bespoke solution, the alternative to using an integrated platform is building from the ground up. However, creating your telephony infrastructure is a notoriously complex, expensive, and time-consuming endeavour. This is where leveraging a managed voice layer like FreJun becomes a strategic advantage.
| Aspect | DIY Telephony Infrastructure | FreJun’s Managed Voice Layer |
| Initial Setup | Procure carrier contracts, configure SIP trunks, set up servers. A multi-month process. | Integrate a simple API. Get started in hours and launch in days. |
| Developer Focus | Divided between telecom engineering and core AI development. | 100% focused on the application’s AI logic (STT, LLM, TTS). |
| Flexibility | High, but comes with an immense operational burden. | High, with complete freedom to choose and swap AI models (like AssemblyAI) without infrastructure changes. |
| Reliability & Scale | You are responsible for global redundancy, uptime, and scaling for call volume. | Built on geographically distributed, high-availability infrastructure designed for enterprise scale. |
| Latency | Optimizing for low-latency audio streaming across the entire stack is a significant engineering challenge. | The entire stack is pre-optimized to minimize latency between the user, your AI, and the response. |
Choosing FreJun allows you to achieve the customization of a DIY approach without inheriting the immense technical debt and distraction of becoming a telecom company.
A Developer’s Guide: Choosing Between Active vs. Passive Voice AI
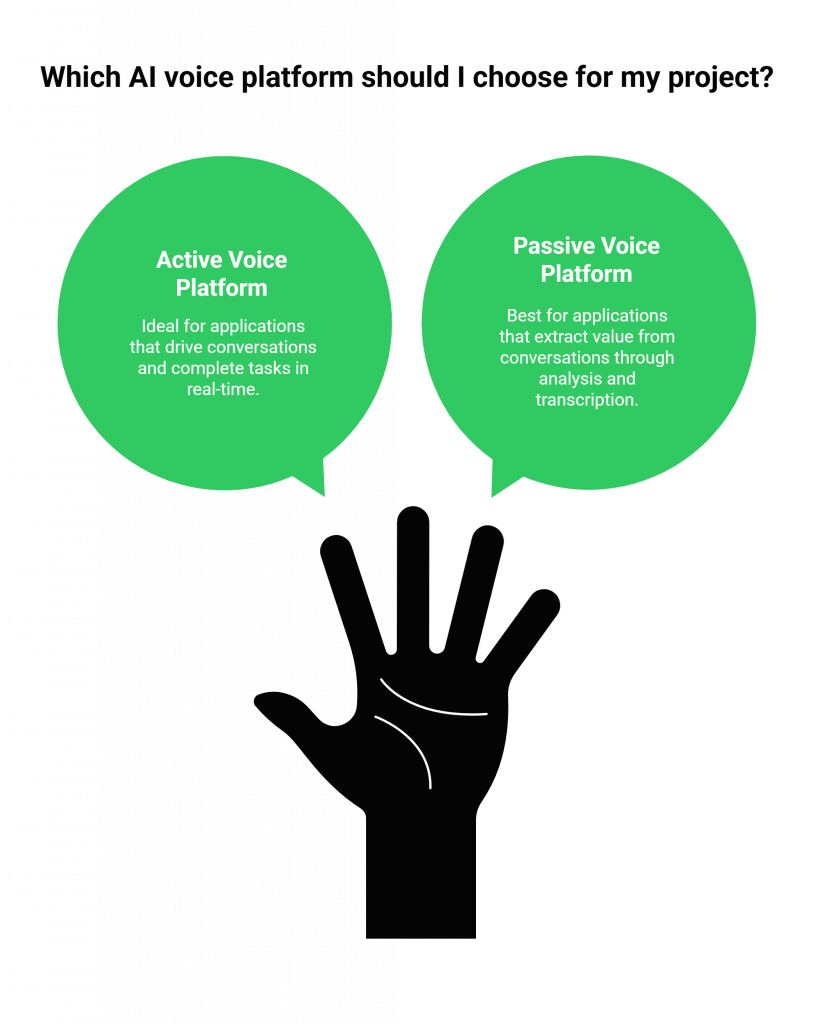
To make the right choice for your project, answer this one question: Is your application’s primary role active or passive?
Choose an Active Voice Platform (like Vapi.ai) if
Your application needs to drive a conversation.
- Goal: To complete a task, such as booking an appointment, answering a question, or qualifying a sales lead.
- Key Requirement: Real-time interactivity, robust call handling, and the ability to manage conversational state.
- Project Examples: AI-powered IVR systems, proactive outreach agents, virtual receptionists.
Choose a Passive Voice Platform (like AssemblyAI.com) if
Your application needs to extract value from a conversation.
- Goal: To understand what was said, who said it, and what it means.
- Key Requirement: High-accuracy transcription, speaker identification, and rich analytics features.
- Project Examples: Compliance monitoring for call centers, meeting summarization tools, video subtitling services, conversational intelligence platforms.
This active vs. passive framework is the clearest way to navigate the Vapi.ai Vs Assemblyai.com decision and ensure your architecture aligns with your objectives from day one. Choosing the right text-to-speech and synthesis tools is another key part of building a complete, high-quality voice experience.
Final Thoughts: Your Project’s Success Hinges on the Right Tool for the Job
In the rapidly maturing world of voice AI, specialization is key. The era of one-size-fits-all platforms is fading, replaced by a new ecosystem of specialized tools designed to do one thing exceptionally well. Vapi.ai’s excellence lies in live, automated voice interaction. AssemblyAI’s strength is in its unparalleled ability to understand and dissect spoken language.
Your job as a developer is not to force a square peg into a round hole. It is to recognize the shape of your problem and select the tool that was purpose-built to solve it. For many, a single specialized platform will be the perfect fit. But for the most innovative and demanding applications, the future lies in an unbundled, best-of-breed approach.
By leveraging a robust transport layer like FreJun, you are no longer limited by the integrated components of a single platform. You are empowered to assemble your dream team of AI services, the best ear, the sharpest brain, and the most natural-sounding mouth and build an application that is truly in a class of its own.
Start Your Journey with FreJun AI!
Also Read: Virtual PBX Phone Systems Implementation for B2B Growth in Enterprises in Sweden
Frequently Asked Questions
While you could use AssemblyAI for the real-time transcription part of a phone bot, it does not provide the necessary telephony infrastructure (call routing, PSTN connection, call management) to handle the phone calls. You would need a separate service, like FreJun, for that.
Vapi.ai is an integrated platform that includes components for speech-to-text as part of its end-to-end service for powering voice agents. However, its core value proposition is the orchestration of the entire live interaction, not just the transcription component.
No, they are not direct competitors. They are complementary tools that serve different parts of the voice AI workflow. Vapi.ai is for voice output and interaction, while AssemblyAI is for voice input and analysis. An advanced application could potentially use both.
FreJun handles the most complex, non-differentiating part of building a voice agent: the real-time telephony infrastructure. This allows you to avoid months of work dealing with carriers and latency optimisation and instead focus immediately on integrating powerful AI services like AssemblyAI to build your application’s core logic.
You would need two more components: a Large Language Model (LLM) like GPT-4 or Claude to handle the “thinking” and generate a text response, and a Text-to-Speech (TTS) service like ElevenLabs to convert that text response back into audio. FreJun acts as the seamless bridge between the phone call and this custom AI stack.