
Customer support automation has evolved from rigid IVRs to LLM-powered agents capable of understanding nuance and remembering context. Yet, bringing such intelligence into a live phone call introduces steep engineering challenges, real-time streaming, low-latency processing, and robust telephony integration. This is where FreJun fits in.
Paired with Jamba’s vast context memory and structured output capabilities, FreJun provides the enterprise-grade voice infrastructure to turn advanced language models into responsive, natural-sounding support agents ready for production-scale deployment.
Table of contents
- The Customer Support Context Crisis
- What is Jamba and Why is it Built for Voice?
- The Real Bottleneck: Moving Beyond Text to Real-Time Voice
- FreJun: The Enterprise-Grade Voice Layer for Your Jamba Bot
- How to Build a Voice Bot Using Jamba? A Practical Guide
- DIY Voice Infrastructure vs. FreJun: A Strategic Comparison
- Best Practices for a Superior Customer Experience
- Focus on Intelligence, Not Infrastructure
- Frequently Asked Questions (FAQs)
The Customer Support Context Crisis
Every customer support leader knows the sound of frustration. It’s a customer, five minutes into a call, repeating their issue for the third time because the automated system lost the context of the conversation. Traditional IVRs and first-generation chatbots fail because they are stateless and script-bound. They cannot handle the natural, meandering flow of human conversation, forcing customers into rigid, unsatisfying loops.
The emergence of advanced Large Language Models (LLMs) promised a solution. Now, AI can understand nuance, remember details, and generate helpful responses. Models like AI21 Labs’ Jamba are specifically designed to handle long, complex conversations, making them the perfect “brain” for a next-generation support agent.
However, possessing a powerful brain is only half the solution. To truly revolutionise customer support, that brain needs a voice, and connecting it to a live phone call introduces a set of engineering challenges that can derail even the most ambitious projects.
What is Jamba and Why is it Built for Voice?
Jamba is a groundbreaking hybrid language model developed by AI21 Labs. It uniquely combines the strengths of Transformer architecture with Mamba (a State Space Model) and a Mixture-of-Experts (MoE) approach. This design isn’t just an academic exercise; it delivers tangible benefits for real-world applications, especially voice-based customer support.
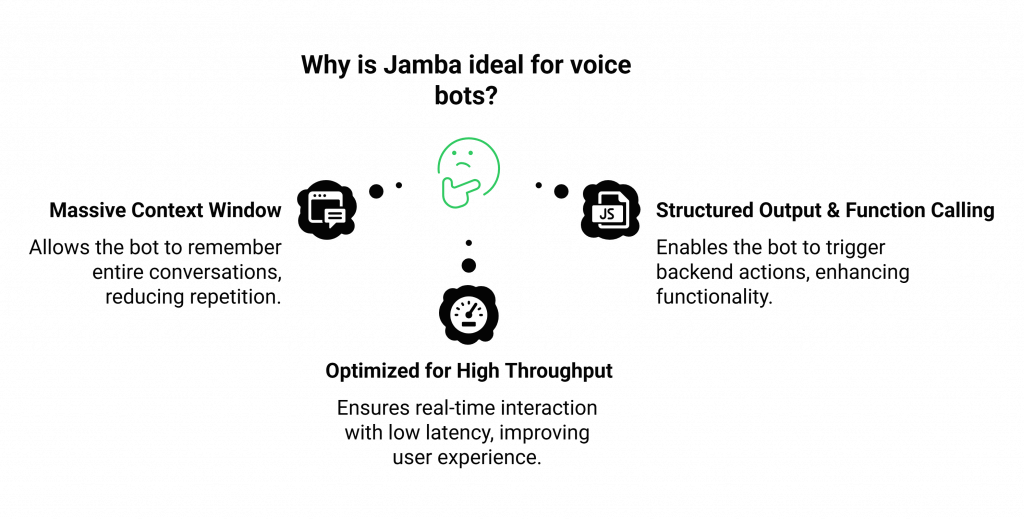
Here’s why Jamba is an ideal foundation for a voice bot:
- Massive Context Window: Jamba supports an enormous context window of up to 256,000 tokens. For a customer support call, this is revolutionary. It means the bot can remember the entire history of a long conversation, including previous questions, user details, and solutions attempted, eliminating the need for customers to repeat themselves.
- Structured Output and Function Calling: The model can generate structured JSON outputs and supports function calling. This allows the bot to do more than just talk; it can trigger actions in your backend systems, like retrieving account information, creating a support ticket, or processing a refund, all based on the natural language conversation.
- Optimized for High Throughput: Jamba’s architecture is engineered for efficiency and speed. Its ability to be deployed on modest GPU clusters means you can achieve the low latency required for a fluid, real-time voice interaction without breaking the bank.
Building a voice bot using Jamba provides the intelligence to create a truly helpful and context-aware customer experience. But this intelligence remains trapped in text until you solve the voice connectivity problem.
Also Read: How to Build an AI Voice Agents Using GPT-4o for Customer Support?
The Real Bottleneck: Moving Beyond Text to Real-Time Voice
A functional voice bot requires a perfectly synchronized trio of technologies operating in milliseconds:
- Automatic Speech Recognition (ASR): To instantly convert the customer’s spoken words into text.
- The LLM (Jamba): To process the text, access its vast context memory, and generate a coherent, helpful response.
- Text-to-Speech (TTS): To convert Jamba’s text response back into clear, natural-sounding audio.
The challenge is not finding these individual components. The true difficulty lies in the voice transport layer, the complex telephony infrastructure that handles the live phone call, streams audio back and forth between the user and your AI services, and does so with imperceptible delay.
Building this layer yourself involves wrestling with SIP trunks, managing call state, battling jitter and packet loss, and engineering a system that can scale to handle thousands of concurrent calls. This is a deep, specialized field of engineering that distracts from your primary goal: building an intelligent customer support agent.
FreJun: The Enterprise-Grade Voice Layer for Your Jamba Bot
FreJun provides the missing piece of the puzzle. We are not an LLM provider. Our platform is the robust, developer-first voice infrastructure that handles all the complex telephony, so you can focus entirely on your AI. We serve as the high-speed, low-latency bridge between the public telephone network and your voice bot using Jamba.
Our model-agnostic API is designed for exactly this purpose. You bring your best-in-class AI stack, your chosen ASR, your Jamba model, and your preferred TTS engine. FreJun manages the rest:
- Real-Time Media Streaming: We capture audio from any inbound or outbound call and stream it to your application in real time.
- Full Conversational Control: Your application maintains complete control over the dialogue state. FreJun acts as a reliable channel, ensuring your backend can track and manage the conversation’s context independently.
- Low-Latency Playback: The audio response generated by your TTS service is streamed back over the call with minimal delay, completing the conversational loop and ensuring a natural flow.
FreJun lets you bypass months of complex telephony development and go straight to building the intelligent voice agent you envisioned.
Also Read: Enterprise Virtual Phone Solutions for Professional B2B Growth in Austria
How to Build a Voice Bot Using Jamba? A Practical Guide
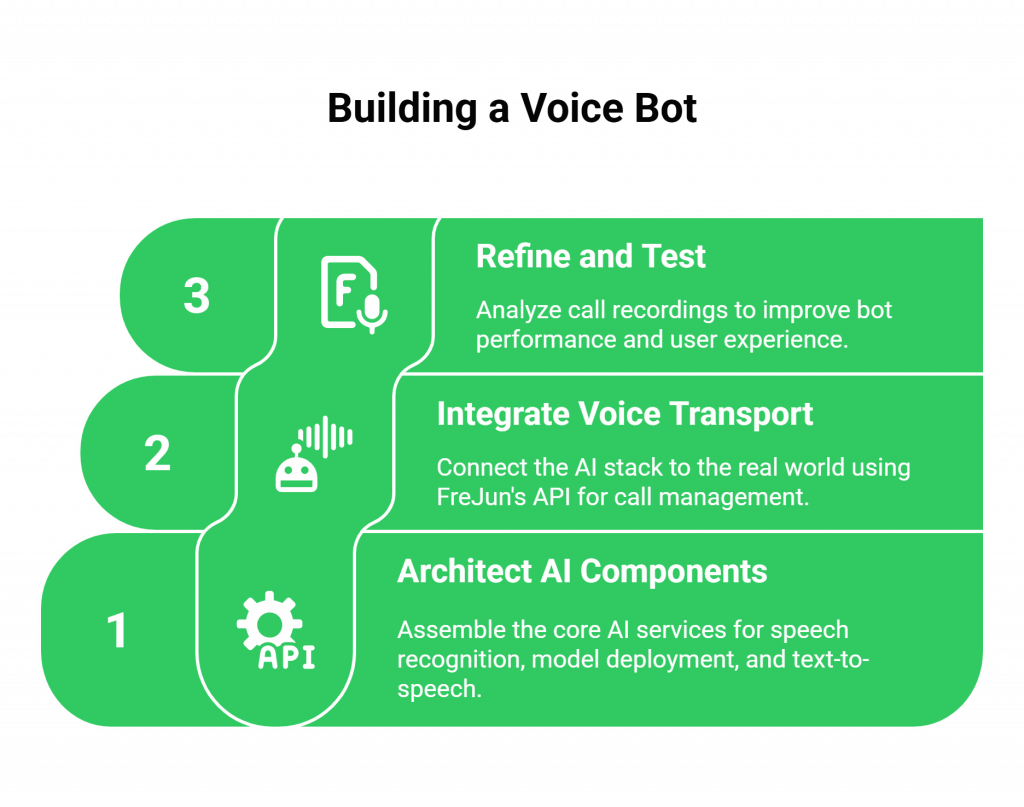
Here is a step-by-step architectural overview of how to build a production-ready customer support voice bot with Jamba and FreJun.
Step 1: Architect Your Core AI Components
First, assemble the three pillars of your bot’s intelligence. These services will run on your backend, ready to be called via APIs.
- Select an ASR Service: Choose a real-time, streaming Automatic Speech Recognition engine capable of accurately transcribing customer speech, even with various accents.
- Deploy Your Jamba Model: Set up your Jamba instance. You have several enterprise-ready options:
- AI21 Studio: Use their managed SaaS platform for quick deployment.
- Amazon Bedrock: Leverage the managed Jamba model available within AWS’s ecosystem.
- Self-Hosted / Private VPC: For maximum data security, deploy Jamba within your own virtual private cloud.
Configure your API calls with parameters like temperature and top_p to control the creativity of the responses.
- Choose a TTS Engine: Select a low-latency Text-to-Speech service, like Amazon Polly, that can generate high-quality, natural-sounding audio to represent your brand’s voice.
Step 2: Integrate the FreJun Voice Transport Layer
With your AI stack ready, you connect it to the real world using FreJun’s API. This step replaces the need to build your own telephony infrastructure.
- Provision a Number: Get a local or toll-free number from FreJun to act as the entry point for your customer support line.
- Configure Call Webhooks: Set up a webhook in your FreJun dashboard that points to your application’s backend. When a customer calls the number, FreJun will notify your application and establish a real-time audio stream.
- Orchestrate the Real-Time Flow: Your backend code will now manage the conversation:
- FreJun streams the customer’s audio to your backend.
- Your backend forwards the audio to your ASR service.
- The transcribed text, along with the conversation history, is sent to the Jamba API.
- Jamba processes the input and returns a text response, which may include a function call.
- Your backend parses the response. If there’s a function call (e.g., “get_order_status”), it executes that action against your internal systems.
- The final text response is sent to your TTS engine.
- The resulting audio is streamed back to FreJun, which plays it to the customer.
This entire loop happens in near real-time, creating a seamless and interactive experience.
Step 3: Refine and Test
Once the workflow is operational, focus on refining the bot’s performance and user experience. Use FreJun’s call recording capabilities to capture interaction data. Analyze these conversations to:
- Fine-tune Jamba’s system prompts for better domain-specific accuracy.
- Identify areas where customers struggle and adjust the conversational design.
- Test the bot’s ability to handle different accents and background noise.
Also Read: Llama 4 Scout Voice Bot Tutorial
DIY Voice Infrastructure vs. FreJun: A Strategic Comparison
When planning your voice bot using Jamba, the “build vs. buy” decision for the voice layer is critical. Here’s how the two approaches stack up.
| Aspect | The DIY Infrastructure Approach | The FreJun Infrastructure Approach |
| Development Focus | Split between AI model, business logic, and complex telephony engineering (SIP, WebRTC, etc.). | 100% focused on refining your Jamba model, business logic, and customer experience. |
| Time to Production | 6-12 months to build a stable, scalable, and secure voice transport layer. | Days or weeks to connect your AI stack to a production-ready, global voice network via API. |
| Latency Management | A constant struggle. Requires deep expertise to optimize the entire audio pipeline for sub-second responses. | Solved by design. FreJun’s entire stack is engineered for low-latency, real-time voice AI applications. |
| Scalability & Reliability | Your responsibility. Requires significant ongoing investment in infrastructure and DevOps to handle call volume and ensure uptime. | Managed for you. Our geographically distributed infrastructure scales on demand and is built for high availability. |
| Specialized Expertise | Requires hiring or training a team of dedicated telecom and VoIP engineers. | Handled by us. You get access to a team of voice experts for dedicated integration support. |
| Core Business Value | Building infrastructure that doesn’t differentiate your product. | Building a smarter voice bot using Jamba that directly improves your customer support metrics. |
Also Read: Virtual Number Implementation for B2B Growth with WhatsApp Business in Spain
Best Practices for a Superior Customer Experience
Building the technology is the first step. Designing a thoughtful interaction is what makes it successful.
- Design a Graceful Handoff: Ensure there is a seamless and clearly communicated process for transferring a customer to a human agent when the bot cannot resolve their issue.
- Implement Fallback Prompts: When the bot doesn’t understand, it should use helpful prompts like, “I’m sorry, I didn’t quite get that. Could you rephrase your request?” instead of just failing.
- Prioritize Data Privacy: When deploying Jamba and handling customer conversations, ensure your entire stack complies with relevant data privacy standards like GDPR.
- Test Extensively: Test the bot with a wide range of user accents and in various acoustic environments to ensure your ASR and the overall system perform reliably in real-world conditions.
Focus on Intelligence, Not Infrastructure
The future of customer support is intelligent, context-aware automation. With a model like Jamba, the AI capability to deliver this future is already here. The primary obstacle is no longer the intelligence but the complex engineering required to give that intelligence a voice.
Choosing to build your voice infrastructure is a strategic misstep. It diverts your most valuable resources, your engineers, to solving a problem that has already been solved at an enterprise scale.
By partnering with FreJun, you make a strategic decision to focus on your core competency: building a sophisticated AI that understands and serves your customers. We provide a secure, scalable, and low-latency voice foundation, allowing you to innovate faster and deliver a customer support experience that builds loyalty and drives business value.
Sign up and try FreJun AI now!
Also Read: How to Build a Voice Bot Using Microsoft Phi-3 for Customer Support?
Frequently Asked Questions (FAQs)
Jamba’s key advantage is its extremely large 256K context window. This allows the voice bot to remember the entire conversation history, preventing customers from having to repeat information and enabling more natural, context-rich interactions.
You need three main services: an Automatic Speech Recognition (ASR) engine to transcribe speech, the Jamba LLM to process intent and generate responses, and a Text-to-Speech (TTS) engine to vocalize the bot’s replies. FreJun provides the essential voice transport layer to connect these services to a live phone call.
You can deploy Jamba via the AI21 Studio SaaS platform, as a managed model on Amazon Bedrock, or self-host it in a private VPC for maximum data security and control.
FreJun is the voice infrastructure provider. Our platform handles the complex telephony part of the equation, managing the phone call, streaming audio in real-time with low latency, and connecting the caller to your backend AI application via a simple API. We are the “plumbing” that makes your voice bot work.