
The rise of powerful, accessible open-source large language models (LLMs) has democratised artificial intelligence. Models like Stability AI’s StableLM have put state-of-the-art conversational capabilities into the hands of developers everywhere. This has ignited a wave of innovation, with businesses eager to build custom AI solutions for automating customer support calls, qualifying leads, and streamlining their operations.
Table of contents
- The Open-Source Opportunity in Call Automation
- The Production Wall: Why Your Voice Bot Demo Fails in the Real World
- FreJun: The Production-Ready Voice for Your Open-Source AI
- The Core Technology Stack for a Production-Ready Voice Bot
- The Production-Grade StableLM Voice Bot Tutorial
- DIY Infrastructure vs. FreJun: A Strategic Comparison
- Best Practices for Optimizing Your StableLM Voice Bot
- Beyond the Model
- Frequently Asked Questions (FAQs)
The Open-Source Opportunity in Call Automation
The appeal is undeniable: a voice bot powered by a transparent, customizable open-source model that you can fine-tune for your specific domain. With StableLM, the “intelligence” component of a voice bot is more accessible and adaptable than ever. However, a brilliant AI brain is only one piece of a much larger puzzle. To be effective, that brain needs a voice, and that voice must function flawlessly over a real telephone line. This is where the real complexity begins.
The Production Wall: Why Your Voice Bot Demo Fails in the Real World
Many development teams, armed with a powerful open-source LLM, successfully build an impressive proof-of-concept. The bot works perfectly in a controlled lab environment, taking input from a laptop microphone and responding with remarkable intelligence. But when the time comes to transition from this local demo to a live production system that can handle real customer calls, the project often hits a wall.
This is the demo-to-production gap, and it’s caused by the immense, often-underestimated complexity of telephony infrastructure. Building a system that can reliably connect a telephone call to an AI application in real-time is a monumental task, filled with challenges:
- Crippling Latency: The delay between a caller speaking and the bot responding is the number one killer of a natural conversation. High latency leads to awkward pauses, interruptions, and a frustrating user experience.
- The Scalability Barrier: A Python script running on a single server or GPU cannot handle hundreds or thousands of concurrent calls during peak business hours.
- Unreliable Connections: Ensuring crystal-clear audio and 99.99% uptime requires a resilient, geographically distributed network, which is incredibly expensive and complex to build and maintain.
- Integration Nightmare: Stitching together telephony carriers, SIP trunks, and real-time media streaming protocols requires highly specialized expertise and distracts from the core goal of building a great AI.
This infrastructure hurdle is why so many promising voice bot projects fail, consuming vast resources on “plumbing” instead of perfecting the conversational experience.
FreJun: The Production-Ready Voice for Your Open-Source AI
FreJun was created to demolish this production wall. We believe that businesses should be able to leverage the best open-source AI models without having to become telecommunications experts. FreJun handles the complex voice infrastructure so you can focus on building your AI.
Our platform serves as the critical bridge between your StableLM application and the global telephone network. We provide a robust, developer-first API that manages the entire voice layer, from call connection to real-time audio streaming. By abstracting away the complexity of telephony, we enable you to turn your text-based StableLM model into a powerful, production-ready voice agent. This guide will serve as a practical StableLM voice bot tutorial for building a solution that’s ready for the real world.
The Core Technology Stack for a Production-Ready Voice Bot
A modern voice bot is not a single piece of software but a pipeline of specialized services working in concert. For a bot powered by StableLM, a typical high-performance stack includes:
- Voice Infrastructure (FreJun): The foundational layer. It connects to the telephone network, manages the call, and streams audio to and from your application in real-time.
- Automatic Speech Recognition (ASR): A service that transcribes the caller’s raw audio into text.
- Conversational AI (StableLM): The “brain” of the operation. Your custom StableLM application processes the transcribed text and generates an intelligent, contextual response.
- Text-to-Speech (TTS): A service like ElevenLabs or Google TTS that converts the AI’s text response into natural-sounding speech.
FreJun is model-agnostic, giving you the freedom to assemble your preferred stack while we handle the most complex and critical piece: the voice transport layer.
The Production-Grade StableLM Voice Bot Tutorial
While many online tutorials start with capturing microphone audio, a real business application starts with a phone call. This StableLM voice bot tutorial outlines the production-ready pipeline using FreJun.
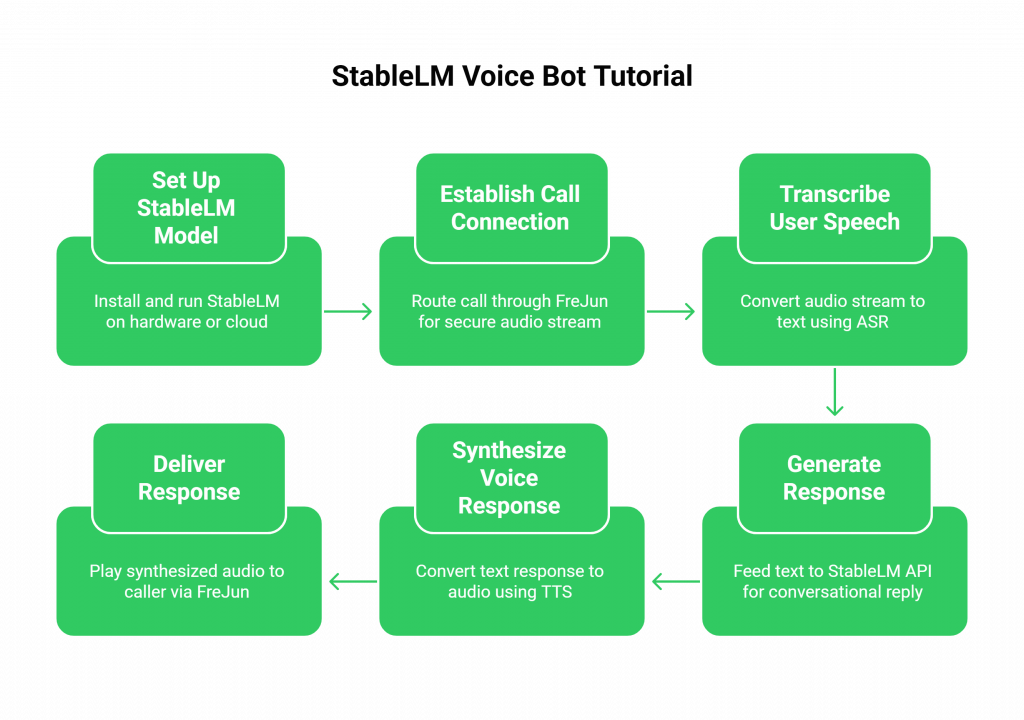
Step 1: Set Up Your StableLM Model
Before you can automate calls, your AI brain needs to be running.
- How it Works: Install and run the StableLM model of your choice (e.g., 3B or 7B parameters) on your own hardware, following the official setup guides. Alternatively, use a cloud-hosted version. Ensure you have an API endpoint ready to receive text prompts and return AI-generated responses.
Step 2: Establish the Call Connection with FreJun
This is where the real-world interaction begins. A customer dials your business phone number.
- How it Works: The call is routed through FreJun’s platform. Our API establishes the connection and immediately begins providing your application with a secure, low-latency stream of the caller’s voice.
Step 3: Transcribe User Speech with ASR
The raw audio stream from FreJun must be converted into text.
- How it Works: You stream the audio from FreJun to your chosen ASR service. The ASR transcribes the speech in real time and returns the text to your application server.
Step 4: Generate a Response with Your StableLM API
The transcribed text is fed to your StableLM model.
- How it Works: Your application takes the transcribed text, appends it to the ongoing conversation history for context, and sends it all as a prompt to your StableLM API endpoint. The model processes this information and generates a relevant, conversational reply.
Step 5: Synthesize the Voice Response with TTS
The text response from StableLM must be converted back into audio.
- How it Works: The generated text is passed to your chosen TTS engine. To maintain a natural flow, it is critical to use a streaming TTS service that begins generating audio as soon as the first words of the response are available.
Step 6: Deliver the Response Instantly via FreJun
The final, crucial step is playing the bot’s voice to the caller.
- How it Works: You pipe the synthesized audio stream from your TTS service directly to the FreJun API. Our platform plays this audio to the caller over the phone line with minimal delay, completing the conversational loop. This part of the StableLM voice bot tutorial is what creates a seamless, interactive experience.
DIY Infrastructure vs. FreJun: A Strategic Comparison
As you follow this StableLM voice bot tutorial, you face a critical build-vs-buy decision for your voice infrastructure. This choice will define the speed, cost, and ultimate success of your project.
| Feature / Aspect | DIY Telephony Infrastructure | FreJun’s Voice Platform |
| Primary Focus | 80% of your resources are spent on complex telephony and network engineering. | 100% of your resources are focused on building and refining the AI conversational experience. |
| Time to Market | Extremely slow (months or even years). Requires hiring a team with rare and expensive telecom expertise. | Extremely fast (days to weeks). Our developer-first APIs and SDKs abstract away all the complexity. |
| Latency | A constant and difficult battle to minimize the conversational delays that make bots feel robotic. | Engineered for low latency. Our entire stack is optimized for the demands of real-time voice AI. |
| Scalability & Reliability | Requires massive capital investment in redundant hardware, carrier contracts, and 24/7 monitoring. | Built-in. Our platform is built on a resilient, high-availability infrastructure designed to scale with your business. |
| Maintenance | You are responsible for managing carrier relationships, troubleshooting complex failures, and ensuring compliance. | We provide guaranteed uptime, enterprise-grade security, and dedicated integration support from our team of experts. |
Best Practices for Optimizing Your StableLM Voice Bot
Building the pipeline is the first step. To create a truly effective bot, follow these best practices:
- Master Prompt Engineering: The quality of your prompts directly impacts the quality of the StableLM model’s responses. Design your system prompts and conversation structure to guide the bot’s tone and relevance.
- Leverage Open-Source for Fine-Tuning: The biggest advantage of an open-source model like StableLM is the ability to fine-tune it on your own data. This allows you to create a highly specialized bot that understands your specific industry jargon and customer intents with superior accuracy.
- Implement Robust Context Management: A coherent, multi-turn conversation depends entirely on maintaining accurate context. Ensure your application correctly stores and sends the conversation history with every turn.
- Test in Real-World Conditions: Move beyond testing with clean audio. Use real phone calls and test with diverse accents, background noise, and varying connection quality to ensure your bot is robust and reliable.
Beyond the Model
The availability of powerful open-source models like StableLM presents a transformative opportunity for businesses to build custom AI solutions. But a powerful AI is not, by itself, a business product. It needs to be connected, reliable, and scalable. It needs a voice.
By building on FreJun’s infrastructure, you make a strategic decision to bypass the most significant risks and costs associated with voice AI development. You can focus your valuable resources on what you do best: creating an intelligent, engaging, and valuable customer experience with your custom-tuned StableLM model. Let us handle the complexities of telephony, so you can build the future of your business communications.
Also Read: Virtual Phone Providers for Enterprise Success in Argentina
Frequently Asked Questions (FAQs)
Stability AI developed StableLM as a suite of open-source large language models. These models handle various natural language tasks and work especially well for building conversational AI applications like voice bots.
No. FreJun is the specialised voice infrastructure layer. Our platform is model-agnostic, meaning you bring your own AI model (like StableLM), Automatic Speech Recognition (ASR), and Text-to-Speech (TTS) services. This gives you complete control and flexibility.
A simple demo often uses a microphone and runs locally. A production tutorial focuses on building a scalable, reliable system that can handle real phone calls from the public telephone network, which requires robust voice infrastructure like FreJun to manage latency, scalability, and call connectivity.
Open-source models offer transparency, accessibility, and the crucial ability to fine-tune them on your own private data. This allows you to create a highly specialized AI that is an expert in your specific business domain, which is often not possible with closed, proprietary models.
Low latency is essential for a natural conversation. Long delays between a user speaking and the bot replying create awkward silences and lead to users interrupting the bot, causing a frustrating and ineffective experience. FreJun is engineered to minimize this latency.