
AI that talks is not hard to build. AI that talks well in real time, over live phone calls is. Most teams underestimate the voice infrastructure required to deliver seamless, low-latency conversations. Between telephony, media streaming, and bidirectional audio, things get messy fast.
FreJun AI is the transport layer that connects your AI to the real world through reliable, production-grade voice. You build the bot. We power the call.
Table of contents
- What is AI Chat Voice and Why Does it Matter?
- The Developer’s Challenge: Complexity of Voice Infrastructure
- FreJun: The Voice Transport Layer for Your AI Stack
- FreJun vs. The DIY Approach: A Head-to-Head Comparison
- A Practical Guide: Connecting Your AI to Live Calls with FreJun
- Core Features That Empower AI Developers
- Final Thoughts: Move from Concept to Production-Grade Voice AI Faster
- Frequently Asked Questions
What is AI Chat Voice and Why Does it Matter?
At its core, AI Chat Voice is the fusion of multiple advanced technologies designed to enable fluid, spoken conversations between humans and AI agents. It goes far beyond the rigid, press-one-for-sales menus of legacy Interactive Voice Response (IVR) systems. Instead of forcing users down a predefined path, it interprets natural human speech, allowing for intuitive and dynamic dialogues. This technology rests on three essential pillars:
- Speech-to-Text (STT): This component listens to the user’s spoken words and accurately converts them into machine-readable text. Leading services include Google Speech-to-Text, Amazon Transcribe, and Microsoft Speech Services.
- Natural Language Understanding (NLU): This is the “brain” of the operation. An AI model, often a Large Language Model (LLM) like those from OpenAI or Google, processes the transcribed text to comprehend the user’s intent, extract key information, and formulate a relevant response.
- Text-to-Speech (TTS): Once the AI has generated a text response, a TTS engine converts it back into natural-sounding, lifelike audio. Services like ElevenLabs, Amazon Polly, and Google Cloud TTS are popular choices for their ability to produce audio with custom voice profiles and emotional tones.
The Developer’s Challenge: Complexity of Voice Infrastructure
For a developer, the path to creating an AI Chat Voice agent seems straightforward on the surface: capture audio, send it to an STT API, process the text with an LLM, send the response to a TTS API, and play the resulting audio back to the user. Many frameworks and cloud providers offer the tools to assemble this pipeline.

However, the real challenge emerges when moving from a browser-based prototype to a production-ready system that handles actual phone calls. This is where developers encounter the harsh realities of telephony and real-time media streaming.
The do-it-yourself (DIY) approach forces your team to solve problems far outside the scope of typical application development:
- Real-Time Media Management: How do you capture a raw audio stream from a live phone call with minimal latency? How do you ensure the stream remains stable even with fluctuating network conditions?
- Bidirectional Streaming: A conversation is a two-way street. You must simultaneously capture the user’s speech while streaming the AI’s response without one interrupting the other, all within milliseconds.
- Latency Stacking: Every step in the DIY chain, call ingress, audio capture, STT API call, LLM processing, TTS API call, and audio playback, adds latency. A few hundred milliseconds at each stage can accumulate into awkward, multi-second pauses that destroy the illusion of a real conversation.
- Telephony Integration: Connecting your application to the global telephone network (PSTN) involves complex protocols (like SIP), carrier negotiations, and regulatory compliance that vary by country.
- Scalability and Reliability: How does your self-built infrastructure handle hundreds or thousands of concurrent calls? Is it geographically distributed to ensure high availability and minimize latency for global users?
FreJun: The Voice Transport Layer for Your AI Stack
This is where FreJun AI provides a clear and powerful alternative. We handle the complex voice infrastructure so you can focus on building your AI. FreJun is not another STT, TTS, or LLM provider. We are the critical transport layer,the enterprise-grade “plumbing”,that connects your AI stack to the telephone network.
Our architecture is designed for one purpose: to turn your text-based AI into a powerful voice agent with speed and clarity. We provide a reliable, low-latency bridge for real-time audio. Here’s how it works:
- Stream Voice Input: FreJun’s API captures real-time, low-latency audio from any inbound or outbound phone call. This raw audio stream is sent directly to your application’s backend.
- Process with Your AI: Your application receives the audio and pipes it to your chosen STT service. The resulting text is then fed into your AI/LLM for processing. You maintain 100% control over the AI logic, context management, and dialogue state. FreJun is completely model-agnostic.
- Generate Voice Response: Once your AI generates a text response, you send it to your preferred TTS service. The system streams the resulting audio back to the FreJun API, which plays it to the user over the call with minimal delay, completing the conversational loop.
With FreJun, you bring your own AI. We manage the voice layer, you manage the intelligence.
FreJun vs. The DIY Approach: A Head-to-Head Comparison
Choosing the right foundation for your AI Chat Voice agent is a critical decision. The following table contrasts the DIY approach with the strategic advantages of using FreJun’s dedicated voice transport layer.
| Feature | The DIY (Do-It-Yourself) Approach | The FreJun Advantage |
| Voice Infrastructure | You must build, manage, and maintain complex telephony connections, media servers, and streaming protocols. | FreJun provides a fully managed, enterprise-grade voice infrastructure, abstracting away all telephony complexity. |
| Latency Optimization | Latency is a constant battle. Each component in your self-built stack adds delay, requiring significant engineering effort to minimize. | Our entire stack is engineered for low-latency media streaming, eliminating the awkward pauses that break conversational flow. |
| Scalability & Reliability | Scaling to handle thousands of concurrent calls requires significant investment in redundant, geographically distributed infrastructure. | Built on resilient, geo-distributed infrastructure engineered for high availability, ensuring your voice agents are always online. |
| Development Focus | A significant portion of developer time is spent on “plumbing”, managing audio streams, telephony protocols, and infrastructure issues. | Developers focus 100% on their core competency: building and refining the AI’s intelligence and conversational capabilities. |
| Speed to Market | The path from a text-based bot to a production-grade voice agent can take months of specialized infrastructure development. | Launch sophisticated, real-time voice agents in days, not months. Our APIs and SDKs are built to accelerate your timeline. |
| Integration & Support | You are on your own to integrate disparate services and troubleshoot issues across the entire stack. | Get dedicated integration support from our experts, from pre-launch planning to post-launch optimization, ensuring your success. |
A Practical Guide: Connecting Your AI to Live Calls with FreJun
Integrating your AI with FreJun to handle live phone calls is a straightforward process designed for developers. It allows you to use your preferred tools and maintain full control over your agent’s logic.
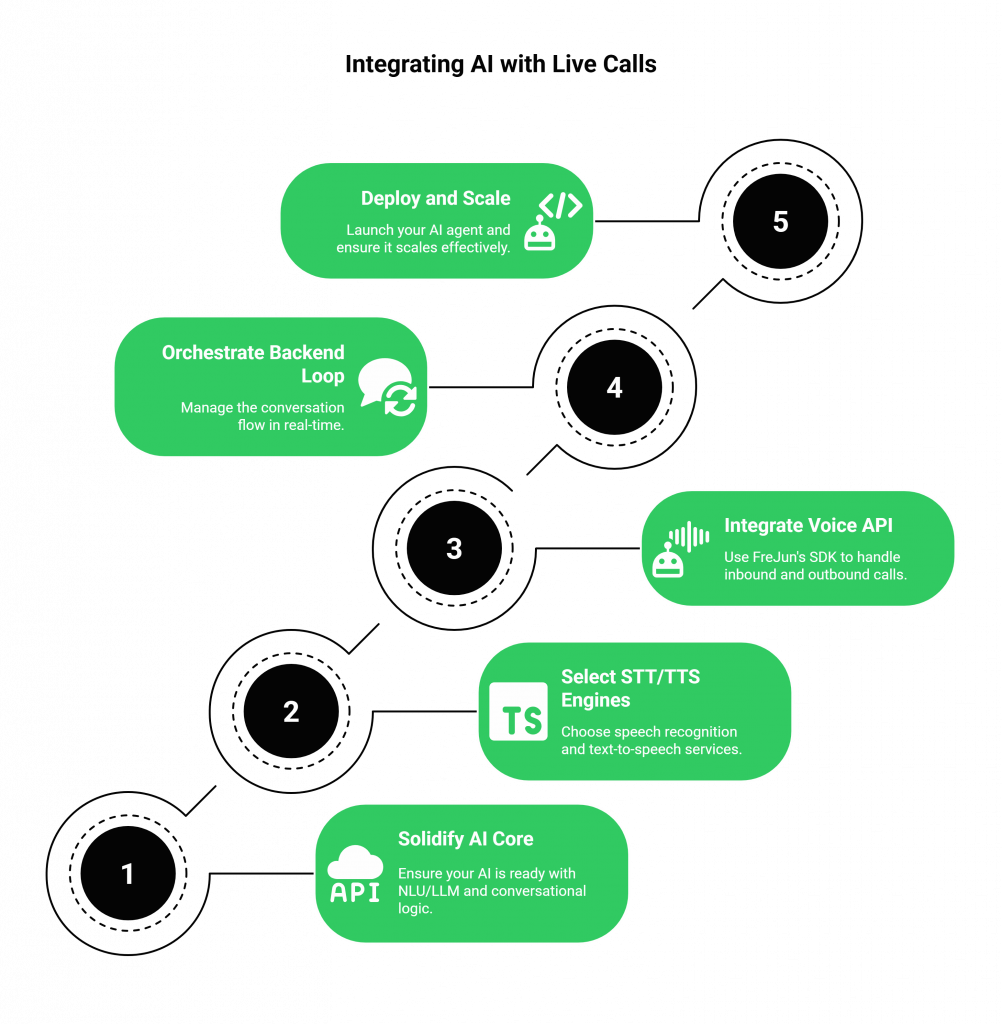
Step 1: Solidify Your AI Core
Before touching the voice components, ensure your text-based AI is ready. This includes setting up your NLU/LLM, defining your conversational logic, and establishing a system for managing conversational context and state. This is your domain, and you have complete freedom to use any model or framework, such as Rasa, OpenAI, or a custom Python/Node.js stack.
Step 2: Select Your STT and TTS Engines
Choose the speech recognition and text-to-speech services that best fit your needs for language, voice style, and cost. Whether it’s Google Speech-to-Text for its accuracy or ElevenLabs for its expressive voices, FreJun’s model-agnostic platform allows you to plug in any provider via their API.
Step 3: Integrate the FreJun Voice Transport API
This is the core integration step. Using FreJun’s developer-first SDKs, you configure your application to handle inbound and outbound calls. Our API acts as a bidirectional pipe:
- Inbound Audio: FreJun captures the caller’s voice from the live call and streams the raw audio to your backend endpoint in real time.
- Outbound Audio: Your application sends the audio generated by your TTS service back to the FreJun API for immediate playback to the caller.
Step 4: Orchestrate the Conversational Loop in Your Backend
Your backend server becomes the central orchestrator for every turn in the conversation:
- Receive the raw audio stream from FreJun.
- Forward this stream to your chosen STT service’s API.
- Take the transcribed text and pass it to your AI/LLM for processing.
- Receive the text response from your AI.
- Send this text to your chosen TTS service’s API to generate an audio response.
- Pipe the TTS audio response back into the FreJun call stream.
This entire loop happens in near real-time, powered by FreJun’s low-latency infrastructure.
Step 5: Deploy and Scale with Confidence
Once your integration is complete, you are ready to go live. FreJun’s robust infrastructure handles all the complexities of call management, scaling, and reliability. Whether you have ten calls or ten thousand, our platform ensures your AI Chat Voice agent remains responsive and available.
Core Features That Empower AI Developers
FreJun’s platform is more than just an API; it’s a complete toolkit designed to help you build and scale production-grade voice applications.
- Direct LLM & AI Integration: Our API is fundamentally model-agnostic. You bring your own AI. This gives you complete freedom to use any chatbot framework, Large Language Model, or custom NLU engine, ensuring you maintain full control over your agent’s logic.
- Developer-First SDKs: We provide comprehensive client-side and server-side SDKs to accelerate development. Easily embed voice capabilities into web and mobile applications or manage call logic entirely on your backend.
- Enable Full Conversational Context: FreJun acts as a stable and reliable transport layer. This provides a persistent channel that allows your backend to track and manage the conversational context independently, which is crucial for sophisticated, multi-turn dialogues.
- Engineered for Low-Latency Conversations: Real-time media streaming is at the heart of our platform. We have optimized our entire stack to minimize the delay between user speech, AI processing, and voice response, eliminating the frustrating pauses that make conversations feel robotic.
Final Thoughts: Move from Concept to Production-Grade Voice AI Faster
The ambition to create a compelling AI Chat Voice agent is the right one. Voice is the most natural interface for communication, and its potential for transforming customer interactions is immense. However, the path to achieving this is often littered with unexpected technical hurdles related to voice infrastructure.
Attempting to build this infrastructure from the ground up is a drain on resources, time, and focus. It forces brilliant AI developers to become amateur telecom engineers, solving problems that have already been solved. The strategic choice is not to reinvent the wheel, but to build upon a solid foundation.
FreJun AI provides that foundation. By abstracting away the immense complexity of real-time voice transport, we empower you to focus on your unique value proposition: the intelligence of your AI. Our platform de-risks your project, accelerates your development timeline, and provides the enterprise-grade reliability and scalability you need to deploy with confidence.
Don’t let infrastructure challenges be the barrier between your innovative AI and the users who need it. Let us handle the voice, so you can perfect the conversation.
Also Read: Top 11 VoIP Providers in Nepal for Seamless International Calling
Frequently Asked Questions
No. FreJun is a voice transport layer. We are intentionally model-agnostic to give you maximum flexibility. You bring your own preferred STT, TTS, and AI/LLM providers, and our platform provides the low-latency infrastructure to connect them seamlessly to a live phone call.
Absolutely not. Our platform is designed to work with any AI chatbot, NLU engine, or Large Language Model. You maintain 100% control over your AI stack and simply use FreJun to manage the voice and telephony layer.
Our entire architecture is engineered from the ground up to minimize latency. We focus on optimizing the real-time media streaming of audio to and from your application, which is the most common source of delay in voice AI systems. This ensures your conversations flow naturally without awkward pauses.
Think of it as the specialized “plumbing” for voice conversations. It handles all the complex, behind-the-scenes work of connecting to the telephone network, capturing raw audio from a call in real time, streaming it to your application, and playing back your AI’s audio response to the caller. It manages the connection so your application doesn’t have to.
No. We are a developer-first company. We provide comprehensive client-side and server-side SDKs and clear API documentation to make integration as fast and simple as possible. Our goal is to get your AI talking in days, not months.