
As a backend developer, your world is defined by logic, data, and the elegant orchestration of APIs. You can build powerful systems that process information at incredible speeds. Now, a new frontier of interaction has opened up: the Real-Time Voice Bot. The promise is to create an application that can listen, think, and speak in milliseconds, powered entirely by the backend logic you architect. The core components, Speech-to-Text (STT), a Large Language Model (LLM), and Text-to-Speech (TTS) are all available via APIs, making this feel like a familiar challenge.
Table of contents
- What is a Real-Time Voice Bot with Backend Logic?
- The Backend Developer’s Dilemma: The Telephony Black Hole
- FreJun: The Voice Infrastructure API for Your Backend Logic
- DIY Telephony vs. The FreJun API: An Architectural Comparison
- A Backend Example: Architecting a Real-Time Voice Bot
- Best Practices for a Resilient Backend Implementation
- Final Thoughts: Focus on Your Logic, Not the Phone Lines
- Frequently Asked Questions (FAQ)
You can design a brilliant backend that flawlessly juggles these services, and it works perfectly in a test environment. But a critical, often brutal, reality check occurs the moment you try to deploy this bot for a real-world business use case. You discover that the most sophisticated backend logic is useless if it can’t connect to the most fundamental voice channel of all: the telephone.
What is a Real-Time Voice Bot with Backend Logic?
A Real-Time Voice Bot is a system that uses backend logic to manage a live, spoken conversation. It is an event-driven application designed for ultra-low latency. The architectural pipeline is a high-speed, continuous loop:
- Audio Streaming: A user’s voice is captured and streamed, chunk by chunk, to your backend.
- Live Transcription (ASR): Your backend immediately pipes this audio to an ASR service, which transcribes it on the fly, often providing partial transcripts for even faster responsiveness.
- Backend Logic & LLM Processing: The transcribed text hits your core backend logic. This is where the magic happens. Your code can invoke custom functions, query a database, or call a third-party API. It then passes the necessary context to an LLM to generate an intelligent response.
- Streaming Synthesis (TTS): The AI’s text response is sent to a TTS service, which synthesizes it into an audio stream that is sent back to the user.
The “backend logic” is the crucial orchestrator, managing this entire flow, maintaining conversational state, and executing business actions based on the user’s spoken commands.
The Backend Developer’s Dilemma: The Telephony Black Hole
The architecture described above is a familiar challenge for any skilled backend developer. The problem isn’t the AI; it’s the audio source. A backend can easily handle a WebSocket stream from a browser, but it has no native ability to handle a phone call.
To connect your brilliant backend logic to the Public Switched Telephone Network (PSTN), you would have to build a highly specialized and complex infrastructure stack from scratch. This is the telephony black hole, and it involves solving a host of non-trivial engineering problems that have nothing to do with AI:
- Telephony Protocols: Managing complex SIP (Session Initiation Protocol) trunks to connect to telecom carriers.
- Real-Time Media Servers: Building and maintaining dedicated servers to handle raw audio streams from thousands of concurrent calls.
- Call Control Signaling: Architecting a system to programmatically manage the entire lifecycle of every phone call, from ringing and answering to on-hold and terminated.
- Network Jitter and Packet Loss: Engineering solutions to mitigate the network imperfections that are common on phone lines and can ruin a real-time conversation.
This is the backend developer’s dilemma. To deploy your Real-Time Voice Bot, you are forced to become a telecom engineer, a massive diversion of time, resources, and focus.
FreJun: The Voice Infrastructure API for Your Backend Logic
This is the exact problem FreJun was built to solve. We are not another AI API. We are the specialized voice infrastructure platform that provides a simple, powerful API to handle the entire telephony layer. FreJun allows backend developers to focus exclusively on their core competency: writing brilliant, scalable logic.
We abstract away all the complexity of voice transport, so you can connect your backend to the phone network as easily as you would connect to any other web service.
- We are AI-Agnostic: You bring your own AI stack. FreJun integrates seamlessly with any backend built on any combination of STT, LLM, and TTS APIs.
- We Manage the Infrastructure: We handle the phone numbers, the SIP trunks, the global media servers, and the low-latency audio streaming.
- We Speak Your Language: We provide a developer-first API that makes a live phone call look like just another WebSocket connection to your application.
FreJun provides the missing link, the clean, reliable, and scalable infrastructure that your backend logic needs to power a true Real-Time Voice Bot.
Key Takeaway
A successful Real-Time Voice Bot implementation is a two-part problem. The first part is the backend logic that orchestrates the AI, a task well-suited to modern developers. The second, much harder part is the voice infrastructure needed to connect that logic to the telephone network. FreJun provides the simple, powerful API that solves this second problem, allowing you to focus on your core competency while still delivering an enterprise-grade, scalable voice solution.
DIY Telephony vs. The FreJun API: An Architectural Comparison
| Feature | The DIY Telephony Approach | The FreJun API-First Approach |
| Infrastructure Focus | Build and maintain voice servers, SIP trunks, and PSTN interconnects. | Integrate a single voice API into your existing backend. |
| Developer’s Role | Becomes a hybrid backend developer and telecom engineer. | Remains focused on backend logic, API orchestration, and AI quality. |
| Time to Deployment | Months, or even years, to build a stable, scalable telephony solution. | Weeks. Get your telephony-enabled bot live in a fraction of the time. |
| Scalability | Extremely difficult and costly to scale for high call concurrency. | Built on an enterprise-grade platform that scales on demand. |
| Maintenance | Continuous, 24/7 maintenance of complex telecom infrastructure. | Zero telephony maintenance. FreJun guarantees uptime and reliability. |
| Core Challenge | Solving low-level telephony and networking problems. | Optimizing the performance and intelligence of your Real-Time Voice Bot. |
A Backend Example: Architecting a Real-Time Voice Bot
This guide outlines the modern, scalable architecture for a voice bot, focusing on the backend logic and using FreJun as the infrastructure layer.
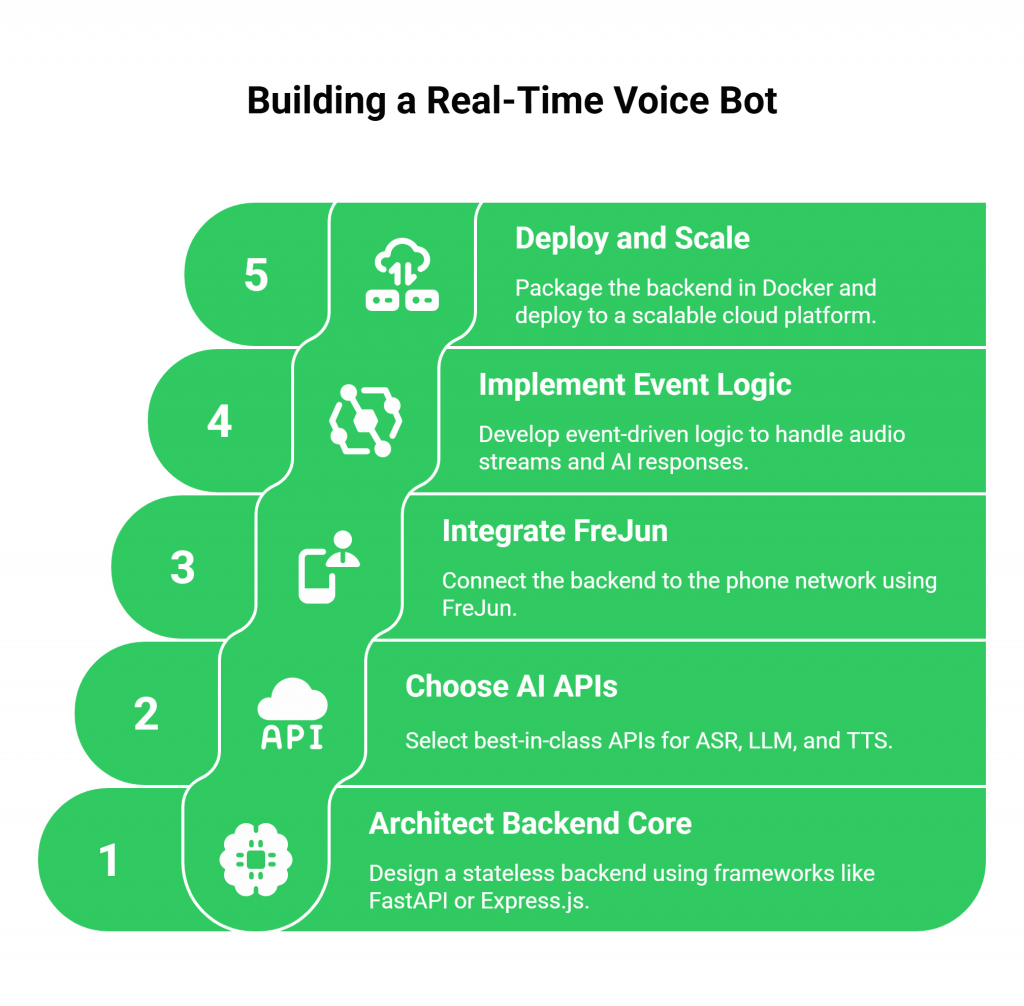
Step 1: Architect a Stateless Backend Core
First, build the “brain” of your voice bot. Using your preferred backend framework (like FastAPI in Python or Express.js in Node.js), write the code that will orchestrate your AI pipeline. A critical best practice is to design this application to be stateless, managing all conversational context in an external, persistent data store like Redis or DynamoDB.
Step 2: Choose Your AI API Stack
Select the best-in-class APIs for each component of your Real-Time Voice Bot.
- ASR API: AssemblyAI or the GPT-4o Realtime API for streaming transcription.
- LLM API: OpenAI, Gemini, or Claude for intent detection and response generation.
- TTS API: ElevenLabs or the GPT-4o API for low-latency, streaming synthesis.
Step 3: Integrate FreJun for the Voice Transport Layer
This is the step that connects your backend to the phone network.
- Sign up for FreJun and instantly provision a virtual phone number.
- Use FreJun’s server-side SDK in your backend to handle incoming WebSocket connections from our platform.
- In the FreJun dashboard, configure your number’s webhook to point to the public URL of your deployed backend service.
Step 4: Implement the Event-Driven Backend Logic
Your backend will now act as an event-driven orchestrator.
- When a call comes in, FreJun establishes a WebSocket and streams the live audio. Your backend receives this audio.
- Your logic pipes this audio to your ASR API and receives a real-time transcription.
- The transcribed text is passed to your LLM API. This is where your custom logic can shine, for example, if the LLM detects an “order_status” intent, your backend can make a database call before generating the final prompt for the LLM.
- The AI’s text response is sent to your TTS API.
- Your backend streams the synthesized audio from the TTS API back to FreJun, which plays it to the caller.
Step 5: Deploy and Scale Your Backend
Package your stateless backend application in a Docker container and deploy it to a scalable cloud platform like Amazon ECS or Google Cloud Run. This allows you to automatically scale the number of server instances based on call volume, ensuring your service is both resilient and cost-effective.
Best Practices for a Resilient Backend Implementation
- Prioritize Ultra-Low Latency: Minimize buffering and use streaming endpoints for both ASR and TTS to keep the conversation fluid.
- Implement Function Calling: Allow your LLM to instruct your backend to execute specific functions (like looking up information or calling a third-party API). This makes your bot far more powerful.
- Design for Failure: Your backend should gracefully handle failures from any of the external APIs it calls. Implement retries or a fallback mechanism, like transferring the call to a human agent.
- Secure All Connections: Use TLS for all API and streaming connections and manage your credentials securely using a secret manager.
Final Thoughts: Focus on Your Logic, Not the Phone Lines
The power of a Real-Time Voice Bot lies in its logic. It’s in the intelligence of its conversations, the efficiency of its workflows, and the seamlessness of its integration with your business systems. This is the domain of the backend developer. The underlying telephony infrastructure, while essential, is a complex, undifferentiated commodity.
Attempting to build this infrastructure yourself is a strategic error. It drains resources, delays your roadmap, and forces your team to become experts in a field that is not core to your business.
The smart path to deployment is to leverage a specialized platform that has already solved the problem of voice at scale. By partnering with FreJun, you can focus your energy on what you do best: writing brilliant backend logic. Let us handle the complexities of connecting your creation to the world.
Further Reading – Voice Chatbot Online: How to Stream Real-Time Audio
Frequently Asked Questions (FAQ)
No. FreJun is a model-agnostic voice infrastructure platform. We provide the API that connects your backend to the phone network, giving you the freedom to choose and integrate any AI services you prefer.
Asynchronous frameworks like FastAPI (Python) and Express.js (Node.js) are particularly well-suited for the real-time, I/O-bound nature of a Real-Time Voice Bot because they can efficiently handle many concurrent WebSocket connections.
Your backend uses a unique session ID, provided by FreJun for each call, to store and retrieve the entire conversation history from an external database or cache (like Redis). This allows any of your server instances to handle any turn of a conversation with full context.
Yes. FreJun’s API provides full, programmatic control over the call lifecycle, including initiating outbound calls. This allows you to deploy your voice bot for proactive use cases like automated appointment reminders or lead qualification campaigns.
A consolidated API can simplify the AI part of the pipeline. However, it still does not solve the fundamental problem of connecting that API to the telephone network. You would still need a platform like FreJun to act as the bridge between the PSTN and the consolidated AI endpoint.