
Voicebots aren’t just “chatbots with sound.” Behind every real-time call lies a stack of fragile, latency-sensitive infrastructure most developers underestimate until they try building one. From audio streaming to SIP, the backend is where most voicebot projects stall. FreJun AI changes that. As your voice transport layer, it removes the telephony burden so you can focus on your AI.
This guide gives backend developers a complete blueprint for launching powerful, production-ready voicebots without becoming a voice engineer.
Table of contents
- Why Building a Voicebot Backend is More Than Just Code?
- The Hidden Complexity: What Makes Voicebot Backends So Challenging?
- Introducing the Modern Approach: The Voice Transport Layer
- The Core Architecture of a High-Performing Voicebot Backend
- The Essential Tech Stack for Backend Development
- FreJun AI vs. Building from Scratch: A Developer’s Comparison
- A Step-by-Step Guide to the Voicebot Backend Workflow
- Best Practices for a Production-Ready Voicebot
- Final Thoughts: Focus on Your AI, Not on Voice Infrastructure
- Frequently Asked Questions
Why Building a Voicebot Backend is More Than Just Code?
For any developer diving into the world of conversational AI, the goal is clear: to create a voicebot that is intelligent, responsive, and indistinguishable from a seamless human conversation. The allure of leveraging powerful Large Language Models (LLMs) to build sophisticated voice agents has never been stronger. However, developers quickly discover that the true challenge isn’t just about crafting clever prompts or fine-tuning an AI model. The real complexity lies in the backend infrastructure required to make that AI talk.
The backend is the central nervous system of any voicebot. It’s responsible for orchestrating a complex dance of real-time audio streaming, multi-service API calls, and state management, all while maintaining the illusion of a single, fluid conversation. This is where brilliant AI concepts often collide with the harsh realities of telephony, network latency, and audio processing. Building this foundation from the ground up is a monumental task, diverting valuable time and resources away from the core objective: building a great conversational experience.
The Hidden Complexity: What Makes Voicebot Backends So Challenging?
When you decide to build a voicebot, you’re signing up for more than just application logic. You become responsible for a fragile, latency-sensitive, real-time communication pipeline. This is a fundamentally different challenge than building a typical web or mobile application backend.
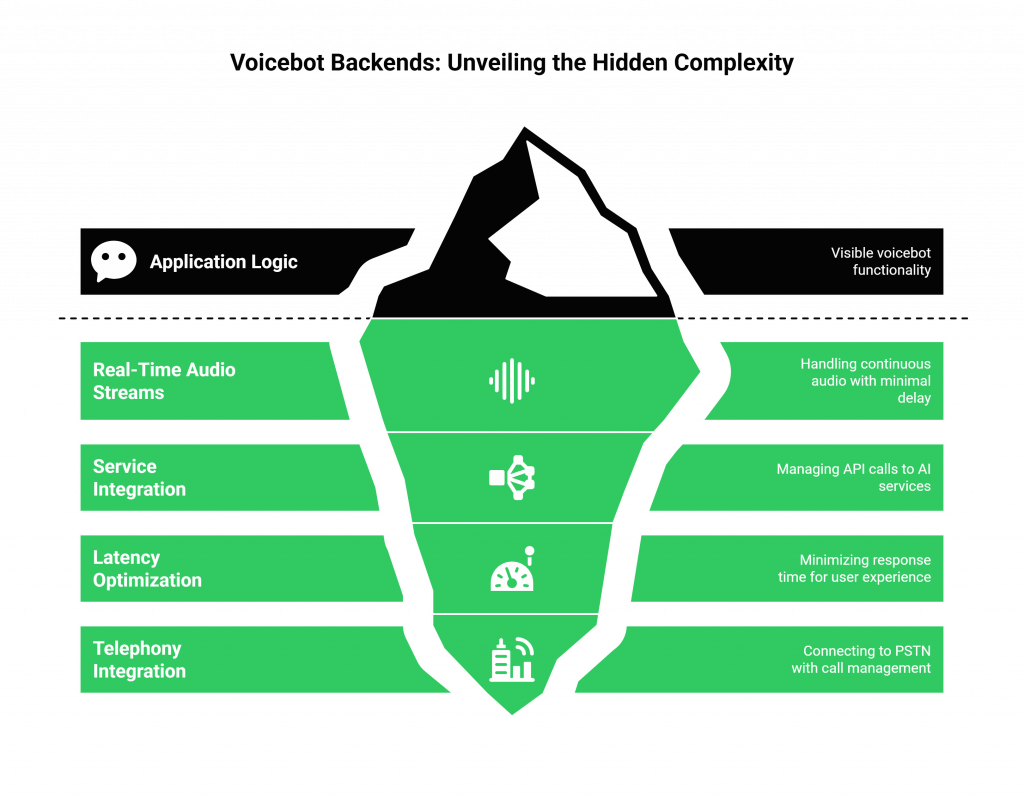
Here are the primary obstacles that developers face:
- Managing Real-Time Audio Streams: Voice is not simple data. It’s a continuous stream of audio that must be captured, transported, and processed with minimal delay. This involves handling low-level audio streaming protocols (like raw PCM over WebSockets), managing buffers, and ensuring every word is captured clearly without dropouts or jitter.
- Integrating a Disparate Stack of Services: A functional voicebot requires at least three distinct AI services: an Automatic Speech Recognition (ASR) service to convert speech to text, a Natural Language Processing (NLP) or LLM service to understand intent and generate a response, and a Text-to-Speech (TTS) service to convert that response back into audio. Your backend must manage API calls to all three, compounding latency at every step.
- The Latency Nightmare: The total time from when a user stops speaking to when they hear a response is the single most important factor in user experience. A delay of more than a second creates awkward pauses that break the conversational flow. Optimizing this entire chain, from the user’s phone, to your backend, to three different AI services, and back again is a significant engineering challenge.
- The Telephony Black Box: If your voicebot needs to connect to the public telephone network (PSTN), the complexity multiplies. You have to deal with telephony carriers, number provisioning, SIP trunks, and call management protocols. This is a specialized domain far removed from typical backend development.
Attempting to solve these infrastructure problems from scratch is not just difficult; it’s a distraction. It forces your team to become experts in voice engineering instead of experts in conversational AI.
Also Read: Best VoIP Providers in Egypt for International Calls
Introducing the Modern Approach: The Voice Transport Layer
Recognizing these challenges, a new category of infrastructure has emerged: the dedicated voice transport layer. This approach abstracts away the entire complex voice and telephony stack, providing developers with a simple yet powerful API to handle real-time audio.
This is precisely where FreJun AI fits into the modern development workflow. FreJun is not another AI model; it is the robust, high-speed plumbing that connects your AI to the human voice.
FreJun AI provides the critical voice infrastructure that handles:
- Real-time, low-latency audio capture from any inbound or outbound call.
- Reliable streaming of that audio to your backend application.
- Streaming of your generated audio response back to the user on the call.
By handling this complex transport layer, FreJun allows developers to focus entirely on their application’s core logic. You bring your own ASR, LLM, and TTS services, maintaining full control over your AI stack while FreJun ensures your voicebot can hear and speak with speed and clarity. This is the essence of a modern voicebot backend developer guide: focus on your unique value, not on reinventing the wheel of voice infrastructure.
The Core Architecture of a High-Performing Voicebot Backend
To build a scalable and effective voicebot, your backend needs a well-defined architecture. This architecture can be broken down into three primary layers, with the transport layer acting as the foundation.
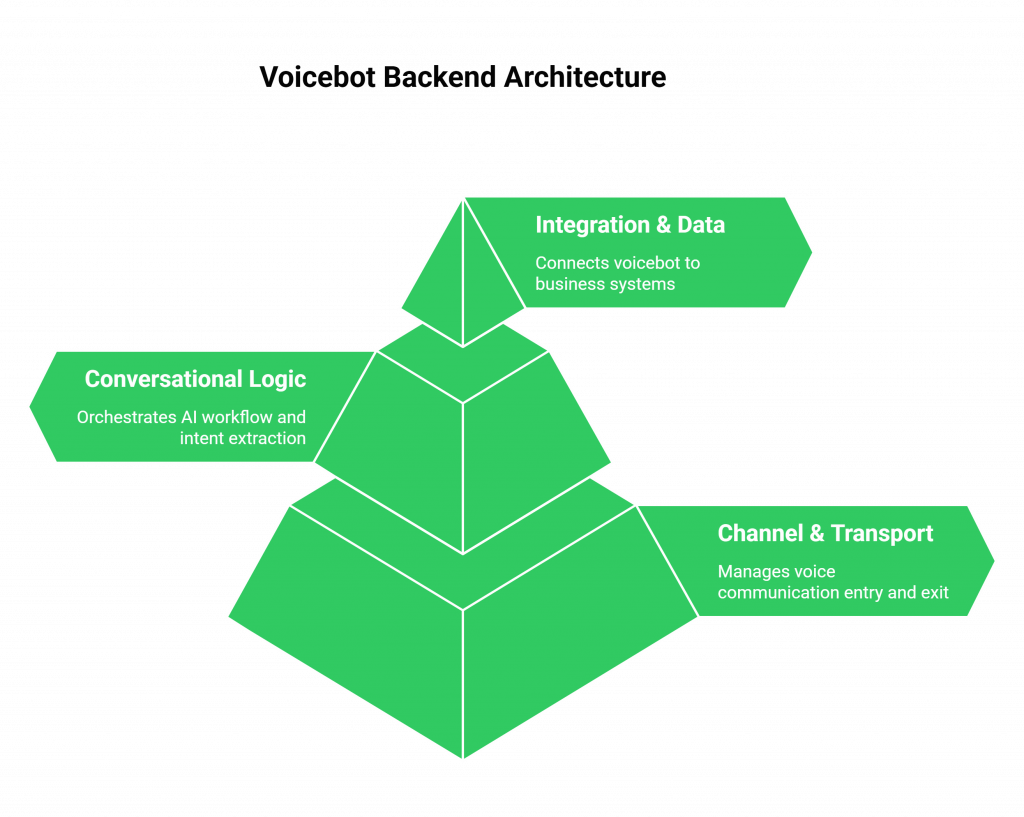
The Channel & Transport Layer (The “How”)
This is the entry and exit point for all communication. It’s responsible for capturing the user’s voice from a channel (like a phone call or a web app) and delivering the bot’s response. This is the layer that FreJun AI manages, exposing simple endpoints so your backend doesn’t have to deal with raw audio protocols or telephony connections.
The Conversational Logic Layer (The “What”)
This is the heart of your application and where your unique code lives. This layer receives the audio stream from the transport layer and orchestrates the AI workflow. Its key responsibilities include:
- Sending the audio to your chosen ASR service.
- Taking the transcribed text and sending it to your NLP or LLM for intent extraction and response generation.
- Maintaining the conversational state and context across multiple turns.
- Applying business logic (e.g., checking a database, calling an external API).
The Integration & Data Layer (The “With”)
This layer connects your voicebot to the wider world of business systems. After your conversational logic layer has determined the user’s intent, it might need to:
- Fetch customer data from a CRM.
- Query a product database.
- Book an appointment in a scheduling system.
- Log the interaction details for analytics.
This layered approach, powered by a dedicated voice transport solution, creates a clean separation of concerns and is fundamental to any successful voicebot backend developer guide.
Also Read: Top 13 VoIP Providers in Israel for Global Calling
The Essential Tech Stack for Backend Development
When building out your conversational logic layer, choosing the right technologies is critical. Here’s a breakdown of the modern tech stack that forms the basis of this voicebot backend developer guide.
Programming Languages
- Python & Node.js: These are the most popular choices due to their extensive ecosystems of libraries for AI, NLP, and web services. Their asynchronous capabilities are also well-suited for handling real-time I/O.
AI/NLP Frameworks
- TensorFlow & PyTorch: For developers building custom machine learning models.
- spaCy & NLTK: Powerful open-source libraries for natural language processing tasks.
Key Third-Party Services (Bring Your Own AI):
- Automatic Speech Recognition (ASR): Google Speech-to-Text, Azure Cognitive Services, Amazon Transcribe.
- Large Language Models (LLM): OpenAI GPT-4, Azure GPT-4o, Anthropic’s Claude, Google’s Gemini.
- Text-to-Speech (TTS): Google Text-to-Speech, Azure Cognitive Services, Amazon Polly, ElevenLabs.
Voice Transport & Channel Integration:
- FreJun AI: A specialized voice transport layer designed for low-latency, real-time voice agent applications. It provides SDKs to handle the telephony and streaming infrastructure.
- Other platforms like Twilio, LiveKit, or Agora can also be used for managing communication channels.
FreJun AI vs. Building from Scratch: A Developer’s Comparison
For a backend developer, the choice is clear: do you spend months building and debugging low-level voice infrastructure, or do you leverage a platform that solves it for you? This is a classic “build vs. buy” decision, and for real-time voice, the argument for “buy” is compelling.
| Feature / Aspect | Building Your Own Voice Infrastructure | Using the FreJun AI Platform |
| Real-Time Audio Handling | Manually manage WebSocket/PCM audio streams, packet loss, and jitter. | Simple, high-level SDKs handle all low-level audio streaming. |
| Telephony Integration | Procure numbers, manage SIP trunks, and handle complex carrier integrations. | Fully managed telephony infrastructure. Provision numbers via an API. |
| Latency Management | Manually optimize every network hop between multiple services. | End-to-end optimized stack engineered specifically for low-latency voice. |
| Developer Focus | 80% on infrastructure plumbing, 20% on AI logic. | 10% on infrastructure integration, 90% on AI logic and user experience. |
| Scalability & Reliability | Responsible for building a distributed, high-availability system. | Leverage a proven, geographically distributed infrastructure built for scale. |
| Time to Production | Months of development and testing. | From concept to a talking agent in days or weeks. |
Also Read: Top 15 VoIP Providers in Kuwait for Global Calls
A Step-by-Step Guide to the Voicebot Backend Workflow
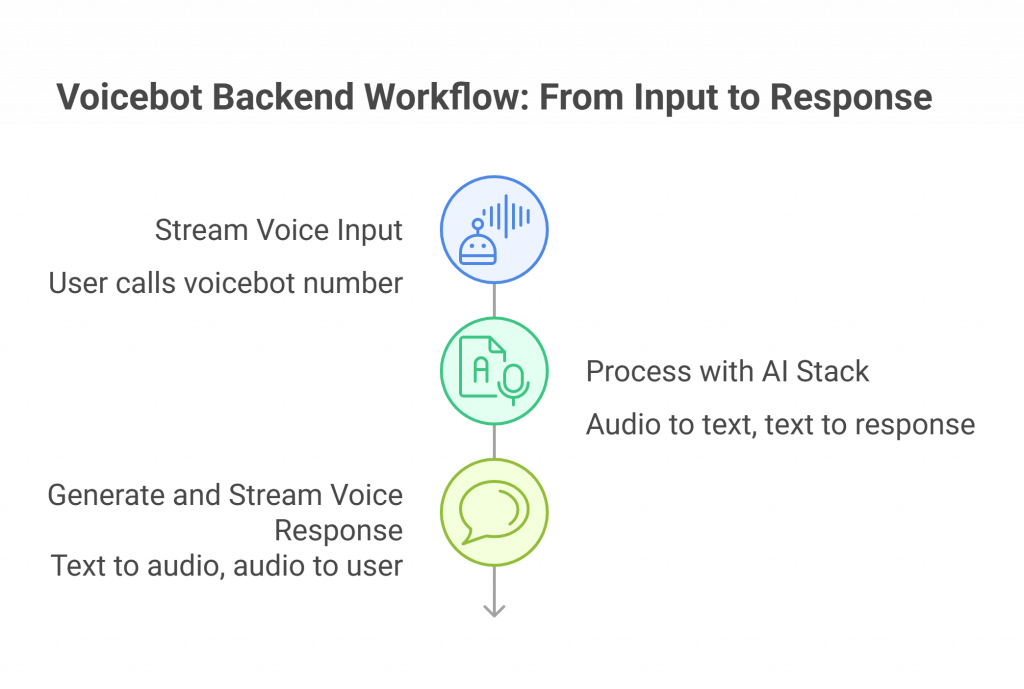
Leveraging a transport layer like FreJun AI dramatically simplifies the backend workflow. Here is the step-by-step process of how a user’s voice is processed and responded to in a modern architecture.
Step 1: Stream Voice Input
The process begins when a user calls the number connected to your voicebot. The FreJun API captures their voice in real-time and streams the low-latency audio directly to an endpoint on your backend server.
Step 2: Process with Your AI Stack
Your backend receives the raw audio stream. Now, your code takes over:
- You pipe the incoming audio stream to your chosen ASR service (e.g., Google Speech-to-Text).
- The ASR returns a text transcription.
- You send this text to your LLM (e.g., OpenAI GPT-4) along with the conversation history to maintain context.
- The LLM processes the text and returns a text-based response.
Step 3: Generate and Stream Voice Response
Your application now has the text of what it needs to say.
- You send this text response to your chosen TTS service (e.g., Amazon Polly).
- The TTS service returns a stream of response audio.
- You pipe this generated audio directly to the FreJun API, which streams it back over the call to the user with minimal delay, completing the conversational loop.
This clean, three-step process is the core of our voicebot backend developer guide, enabling rapid development and iteration.
Best Practices for a Production-Ready Voicebot
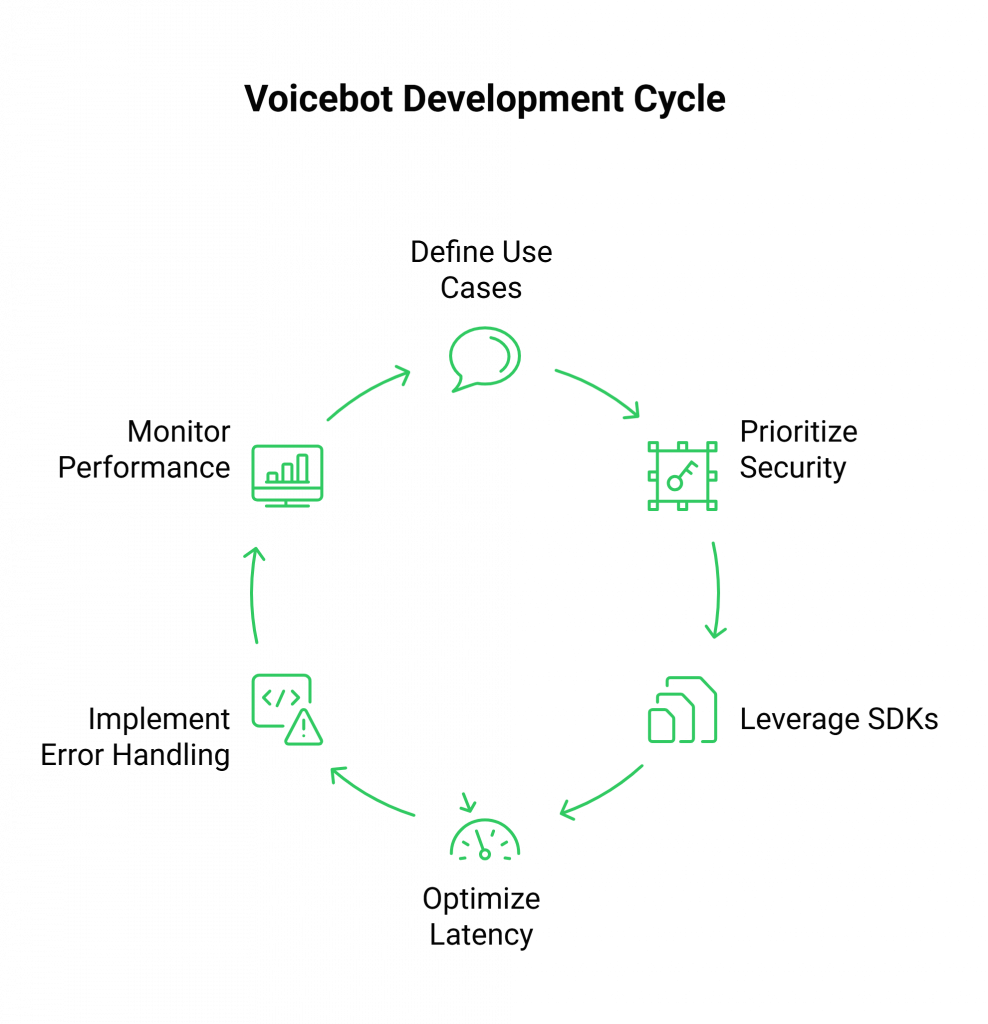
As you move from prototype to production, adhering to best practices is crucial for building a robust and reliable system.
- Define Use Cases Clearly: Before writing a single line of code, map out the conversation flows. Understand the primary goals of the voicebot and define the happy paths and potential failure scenarios.
- Prioritize Security: Always secure your backend endpoints with access tokens or OAuth. Ensure any sensitive data, like voice recordings or user information, is encrypted both in transit and at rest.
- Leverage Proven SDKs: Avoid reinventing the wheel. Use the developer-first SDKs provided by platforms like FreJun AI to handle the complexities of audio handling and channel integration. This accelerates development and reduces bugs.
- Invest in Latency Optimization: While the transport layer is critical, your own backend logic also contributes to latency. Optimize your code, use fast databases, and consider co-locating your servers in the same region as your primary ASR/TTS/LLM providers.
- Implement Robust Error Handling: What happens if your TTS service times out or the ASR fails to transcribe? Your backend must gracefully handle these faults, perhaps by asking the user to repeat themselves or escalating to a human agent.
- Monitor Everything: Deploy monitoring systems to track key performance indicators like end-to-end latency, transcription accuracy, API error rates, and user satisfaction. Use this data to continuously improve your voicebot.
This focus on best practices is what elevates a project from a simple script to a production-grade application, a key lesson in any practical voicebot backend developer guide.
Also Read: 15 Best VoIP Providers in Saudi Arabia for International Call
Final Thoughts: Focus on Your AI, Not on Voice Infrastructure
The future of voice AI is specialization. The most innovative and effective voicebots will be built by developers who can dedicate their time and expertise to what truly matters: crafting intelligent, empathetic, and effective conversational logic. The era of spending months wrestling with SIP protocols and audio codecs is over.
By adopting a modern architectural approach and leveraging a dedicated voice transport layer like FreJun AI, you fundamentally change the development equation. You abstract away the immense complexity of real-time voice communication, freeing yourself to focus on the AI that makes your voicebot unique.
You maintain complete control over your AI stack, choosing the best models for your use case, while relying on a battle-tested foundation to handle the audio.
This is the definitive path forward. Stop building plumbing and start building intelligence. That is the most important lesson in this voicebot backend developer guide.
Further Reading –Stream Voice to a Chatbot Speech Recognition Engine via API
Frequently Asked Questions
No. FreJun AI is a model-agnostic voice transport layer. You bring your own AI stack (e.g., Google Speech-to-Text, OpenAI, Amazon Polly). We provide the complex real-time voice streaming and telephony infrastructure, giving you full control over the AI logic and model selection.
You can use any backend language you are comfortable with. However, Python and Node.js are the most popular choices because of their strong library support for AI/NLP tasks and excellent asynchronous handling capabilities, which are essential for real-time applications. FreJun AI’s SDKs are designed to integrate easily with any modern backend.
Managing latency is a shared responsibility. Your backend code should be highly optimized, but the transport layer is critical. The FreJun AI platform is engineered from the ground up for low-latency media streaming, which significantly minimizes the round-trip delay between the user speaking, your AI processing the request, and the voice response being played back.
Yes, absolutely. This is a core function of your backend’s conversational logic layer. Once your LLM has processed the user’s intent, your backend code is responsible for making the necessary API calls to any external system, such as a CRM, database, or third-party service, to fetch information or perform actions.